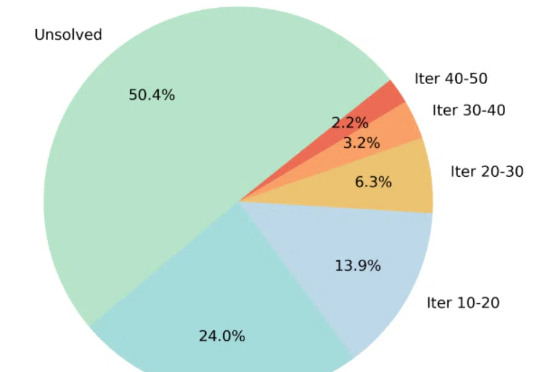
7B超越GPT!1/20数据,无需知识蒸馏,马里兰等推出全新视觉推理方法
7B超越GPT!1/20数据,无需知识蒸馏,马里兰等推出全新视觉推理方法通过蒙特卡洛树搜索筛选高难度样本,ThinkLite-VL仅用少量数据就能显著提升视觉语言模型的推理能力,无需知识蒸馏,为高效训练提供了新思路。
来自主题: AI技术研报
9547 点击 2025-04-24 14:38
 搜索
搜索
通过蒙特卡洛树搜索筛选高难度样本,ThinkLite-VL仅用少量数据就能显著提升视觉语言模型的推理能力,无需知识蒸馏,为高效训练提供了新思路。

最近也是好起来了,上周四去杭州参加了字节火山的线下meetup开发者大会。在会议现场亲自体验了他们这次新发布的大模型和产品,整个过程还挺有意思的。视觉模型Doubao-1.5-vision-pro也非常nice

o3和o4-mini视觉推理突破,竟未引用他人成果?一名华盛顿大学博士生发出质疑,OpenAI研究人员对此回应:不存在。
知道大模型接下来要卷视觉推理,但没想到这么卷——数学试卷都快要不够用了。
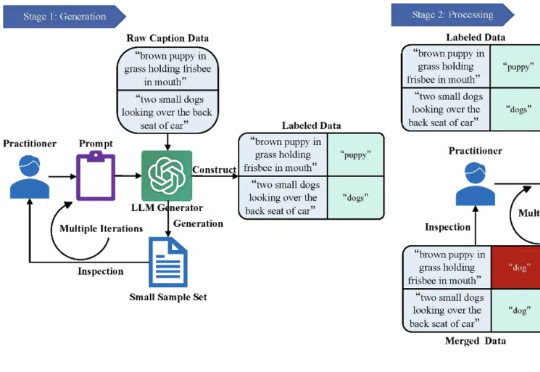
对于AI视觉多模态大模型只关注显著信息这一根本性缺陷,哈工大GiVE实现突破!

最近,来自大连理工和莫纳什大学的团队提出了物理真实的视频生成框架 VLIPP。通过利用视觉语言模型来将物理规律注入到视频扩散模型的方法来提升视频生成中的物理真实性。
“史上最强视觉生成模型”,现在属于快手。一基双子的可灵AI基础模型——文/图生图的可图、文/图生视频的可灵,都重磅升级到2.0版本。可图2.0,对比MidJourney 7.0,胜负比「(good+same) / (same+bad)」超300%,对比FLUX超过150%;

今天,字节发布了一整套 AI 全家桶,深度思考模型、视觉推理、文生图、AI Agent……几乎涵盖了最近 AI 圈关注度最高的产品。字节发布的产品和亮点有哪些:1. 豆包 1.5 · 深度思考模型,2. 文生图 3.0
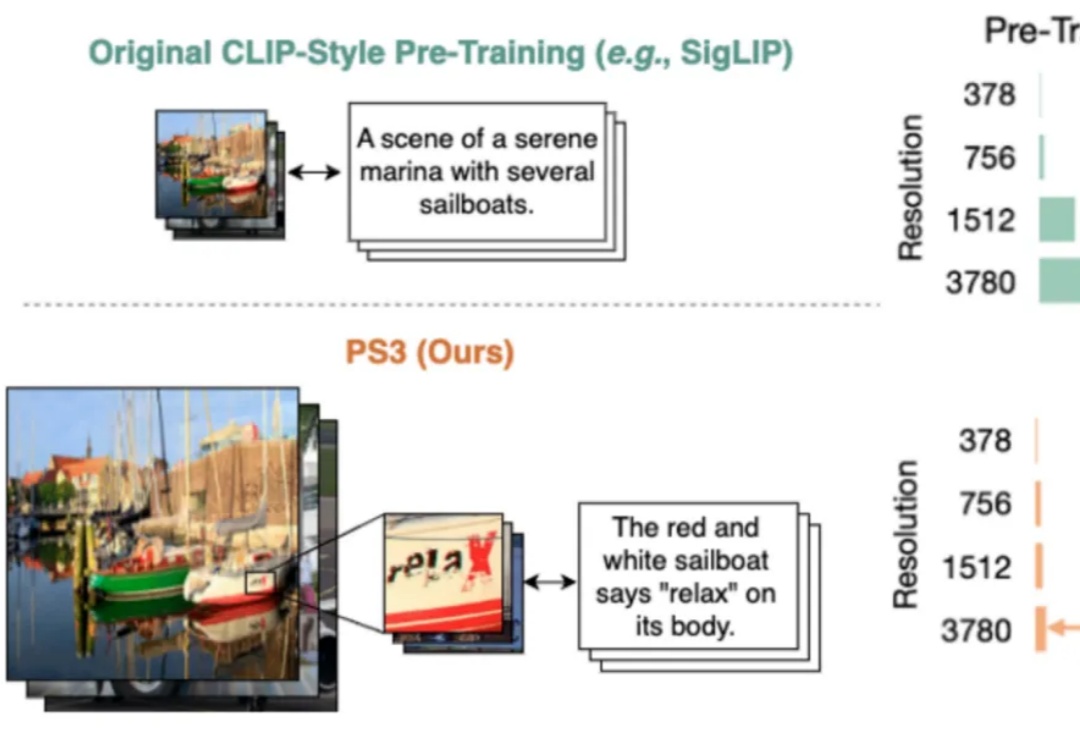
当前,所有主流的视觉基础模型(如 SigLIP、DINOv2 等)都仍然在低分辨率(如 384 * 384 分辨率)下进行预训练。对比人类视觉系统可以轻松达到 10K 等效分辨率,这种低分辨率预训练极大地限制了视觉模型对于高清细节的理解能力。

满血版o3和o4-mini深夜登场,首次将图像推理融入思维链,还会自主调用工具,60秒内破解复杂难题。尤其是,o3以十倍o1算力刷新编程、数学、视觉推理SOTA,接近「天才水平」。此外,OpenAI还开源了编程神器Codex CLI,一夜爆火。