
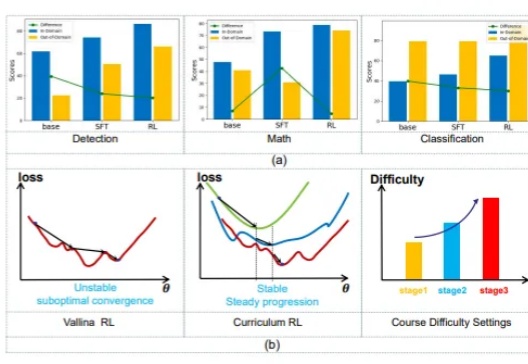
视觉自回归生成理解编辑大一统!北大团队多模态新突破,VARGPT-v1.1训练数据代码全面开源
视觉自回归生成理解编辑大一统!北大团队多模态新突破,VARGPT-v1.1训练数据代码全面开源北京大学团队继VARGPT实现视觉理解与生成任务统一之后,再度推出了VARGPT-v1.1版本。该版本进一步提升了视觉自回归模型的能力,不仅在在视觉理解方面有所加强,还在图像生成和编辑任务中达到新的性能高度
来自主题: AI技术研报
8607 点击 2025-04-16 09:44
 搜索
搜索
北京大学团队继VARGPT实现视觉理解与生成任务统一之后,再度推出了VARGPT-v1.1版本。该版本进一步提升了视觉自回归模型的能力,不仅在在视觉理解方面有所加强,还在图像生成和编辑任务中达到新的性能高度

传统科技公司、尤其是 2B 的公司,其信息、视觉传达都是以公司、产品、技术创新为中心的。但是,处在现代最前沿技术之一的 AI 公司,似乎想做一些不一样的传达。我们将近距离看一下 OpenAI,Cohere,Anthropic 这三家 AI 模型公司的信息、视觉传达,看看他们怎么是从传统科技公司的风格中,做出一些不一样的、以人为本的品牌设计的。
近年来,随着大型语言模型(LLMs)的快速发展,多模态理解领域取得了前所未有的进步。像 OpenAI、InternVL 和 Qwen-VL 系列这样的最先进的视觉-语言模型(VLMs),在处理复杂的视觉-文本任务时展现了卓越的能力。
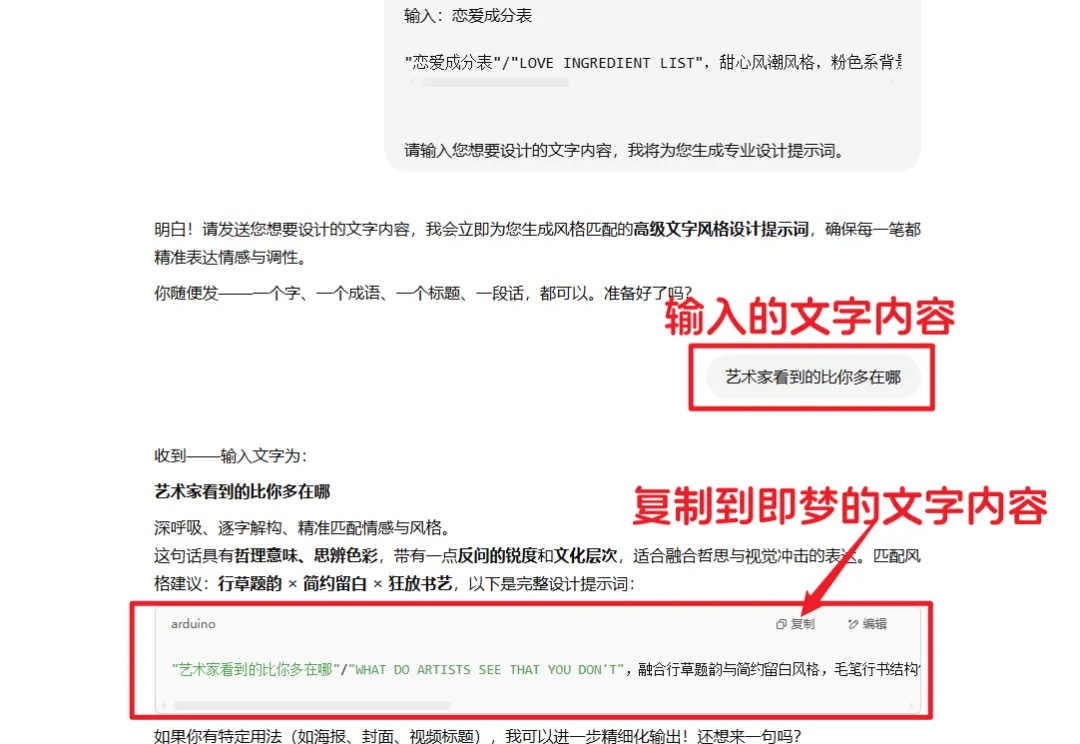
每天脑子里都有很多想法转瞬即逝,不赶紧记录下来就会懒到不想再实践,于是在周五依然好好更新了!今天也是一个很不错的干货,这组提示词的作用是,你只需要输入你的文字内容,就可以得到还不错的文字设计的视觉效果。为了它的效果测试和呈现我几乎掏空了我的即梦AI,测试非常多组合和风格后确信效果确实是还不错的。

从海底的慢动作漂浮到战场的史诗旋转,这十个视频全是Google Veo 2的神来之笔!它能让你的点子秒变大片级画面,快来围观这场创意狂欢。

如果你没有杜蕾斯背后强大的5A广告公司、鬼才般的创意团队、句句封神的的金牌文案、审美爆辣的视觉艺术家。借助即梦刚上线的3.0生图模型以及 Deepseek生创意和文案,你也可以轻松复刻一个「杜蕾斯级别」的刷屏海报。
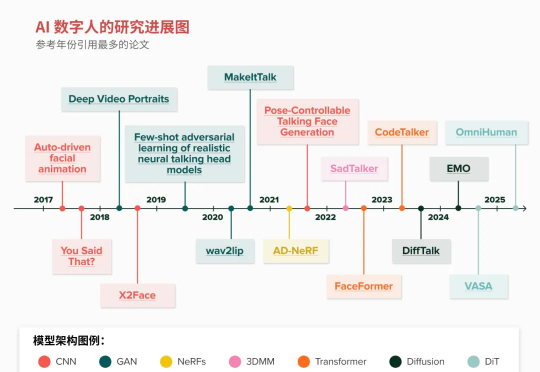
过去几年,AI 已经能生成逼真的图片、视频和声音,悄然通过视觉和听觉的图灵测试。但 2025 年最令人激动的突破之一,毫无疑问将是把这些方案集于一体的 AI 数字人(Al Avatar)。

大家还记得那个 ICLR 2025 首次满分接收、彻底颠覆静态图像光照编辑的工作 IC-Light 吗?

在现实世界中,如何让智能体理解并挖掘 3D 场景中可交互的部位(Affordance)对于机器人操作与人机交互至关重要。所谓 3D Affordance Learning,就是希望模型能够根据视觉和语言线索,自动推理出物体可供哪些操作、以及可交互区域的空间位置,从而为机器人或人工智能系统提供对物体潜在操作方式的理解。
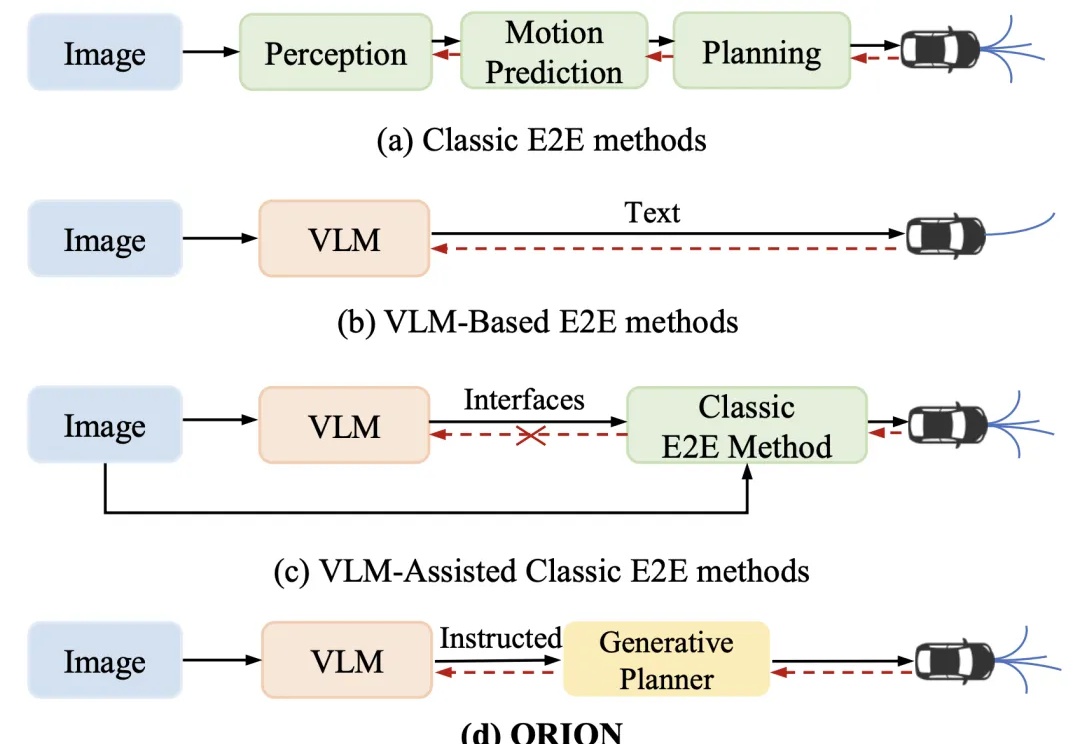
近年来,端到端(End-to-End,E2E)自动驾驶技术不断进步,但在复杂的闭环交互环境中,由于其因果推理能力有限,仍然难以做出准确决策。虽然视觉 - 语言大模型(Vision-Language Model,VLM)凭借其卓越的理解和推理能力,为端到端自动驾驶带来了新的希望,但现有方法在 VLM 的语义推理空间和纯数值轨迹的行动空间之间仍然存在巨大鸿沟。