
Kimi 16B胜GPT-4o!开源视觉推理模型:MoE架构,推理时仅激活2.8B
Kimi 16B胜GPT-4o!开源视觉推理模型:MoE架构,推理时仅激活2.8B刚刚,Kimi团队上新了!
来自主题: AI技术研报
8620 点击 2025-04-10 16:25
 搜索
搜索
刚刚,Kimi团队上新了!

今天,我们正式发布jina-reranker-m0。这是一款多模态、多语言重排器(reranker),其核心能力在于 对包含丰富视觉元素的文档进行重排和精排,同时兼容跨语言场景。
一家名为 Krea 的初创公司正致力于服务设计师及其他视觉创意工作者,解决一站式生成难题,并已为其平台筹集了 8300 万美元资金,该平台旨在让生成式 AI 的使用更加流畅。

大规模数据集和标准化评估基准显著促进了自然语言处理和计算机视觉领域的发展。然而,机器人领域在如何构建大规模数据集并建立可靠的评估体系方面仍面临巨大挑战。
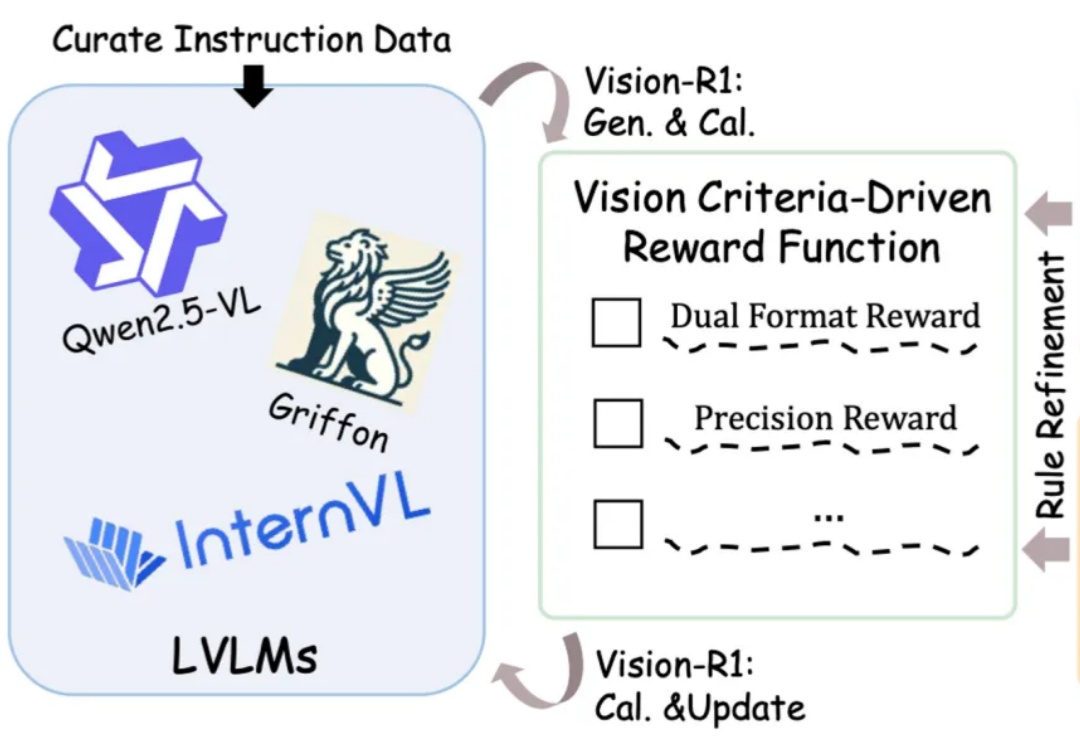
图文大模型通常采用「预训练 + 监督微调」的两阶段范式进行训练,以强化其指令跟随能力。受语言领域的启发,多模态偏好优化技术凭借其在数据效率和性能增益方面的优势,被广泛用于对齐人类偏好。目前,该技术主要依赖高质量的偏好数据标注和精准的奖励模型训练来提升模型表现。然而,这一方法不仅资源消耗巨大,训练过程仍然极具挑战。
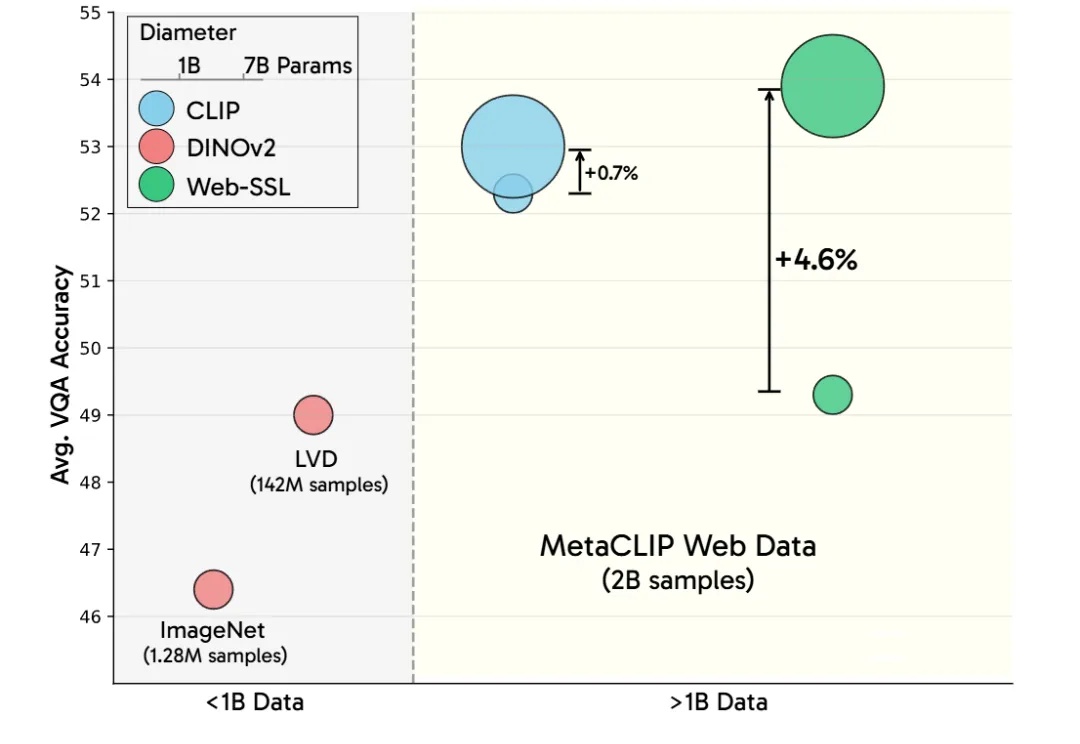
LeCun谢赛宁等研究人员通过新模型Web-SSL验证了SSL在多模态任务中的潜力,证明其在扩展模型和数据规模后,能媲美甚至超越CLIP。这项研究为无语言监督的视觉预训练开辟新方向,并计划开源模型以推动社区探索。

想象一下,耗费动画大师宫崎骏数十年心血、一帧一画精雕细琢的艺术风格——比如《起风了》中耗时一年多的四秒人群场景,或是《幽灵公主》里那个生物钻地镜头背后一年零七个月的 5300 帧手绘,如今,在GPT-4o手中,似乎变得“唾手可得”。
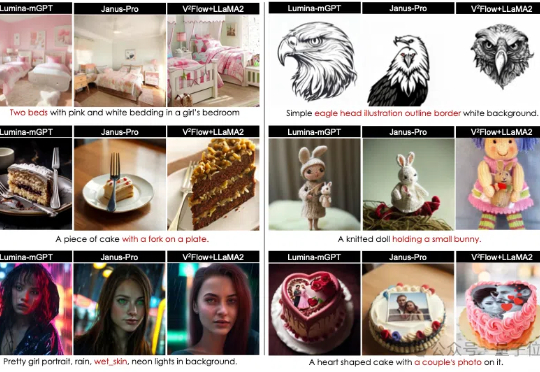
视觉Token可以与LLMs词表无缝对齐了!
扩展无语言的视觉表征学习。
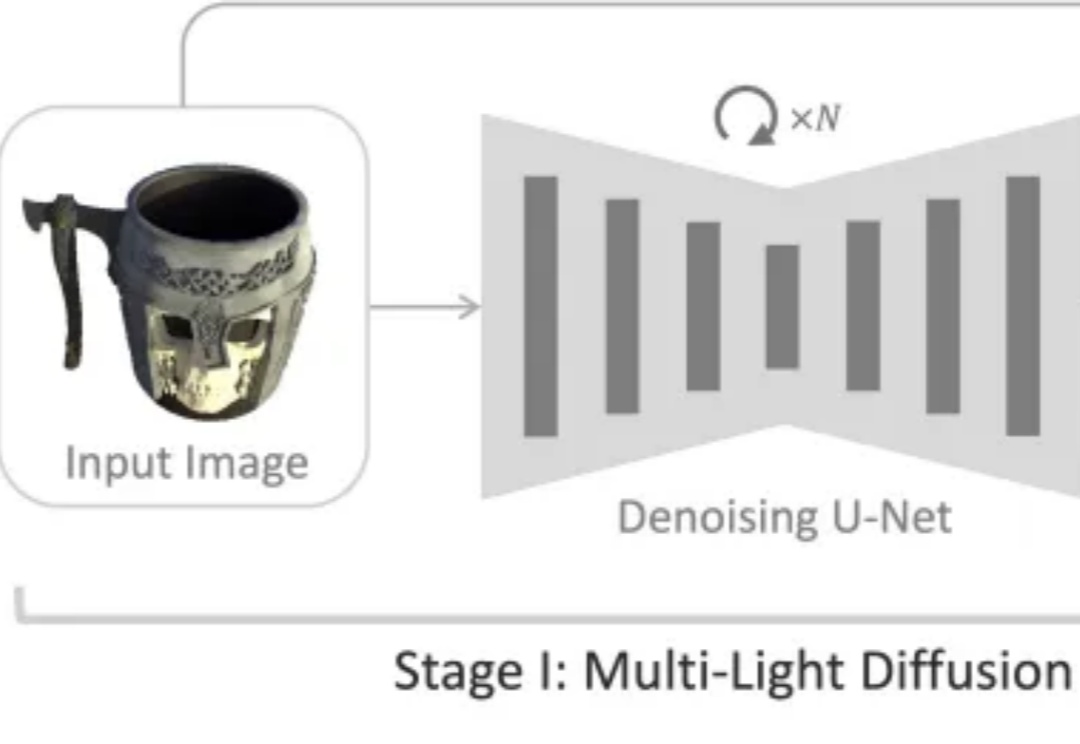
如何从一张普通的单幅图像准确估计物体的三维法线和材质属性,是计算机视觉与图形学领域长期关注的难题。