近2亿美元!VAST完成新一轮融资,正式披露世界模型路线
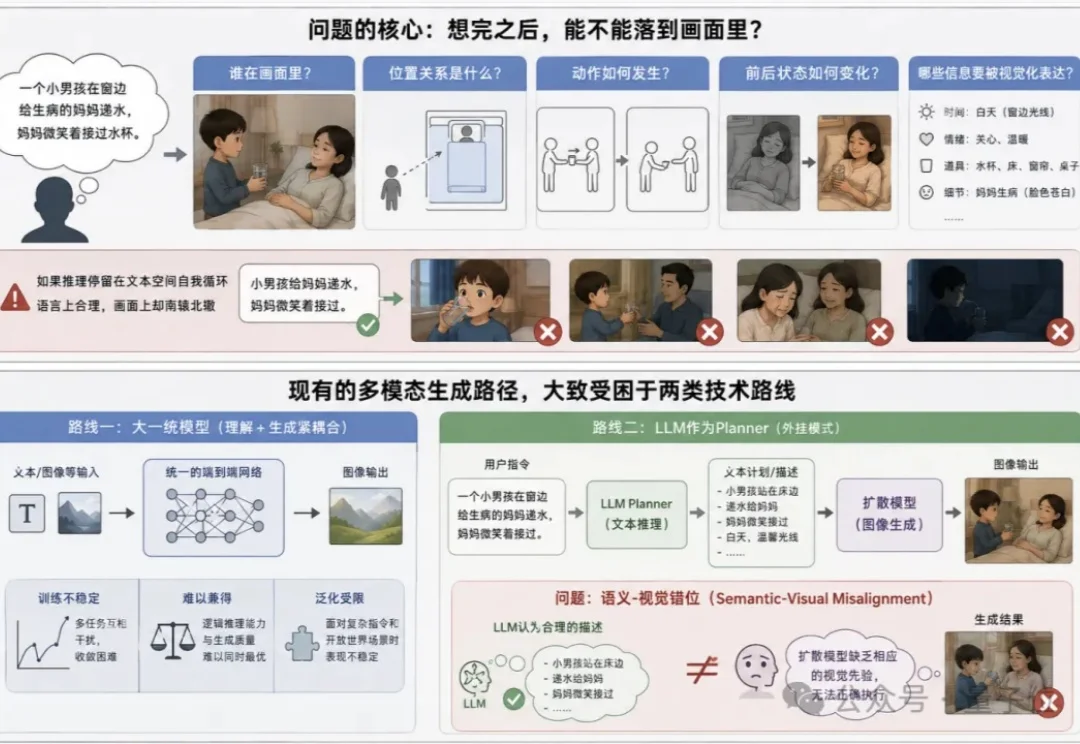
近2亿美元!VAST完成新一轮融资,正式披露世界模型路线VAST近期完成合计近2亿美元的A+及A++轮融资,领投方为渶策资本、国寿长三角科创基金。拿到这笔钱的同时,VAST也带来了他们最新的世界模型进展:Project Eden。区别于业内「动作条件视频生成」与「静态3D场景生成」等常规路径,Project Eden创造性地将底层状态推演与视觉呈现进行了原生解耦。
来自主题: AI资讯
9738 点击 2026-06-01 16:56