
Z Tech|对话童晟邦:师从LeCun与谢赛宁,视觉大模型的下一站是World Model
Z Tech|对话童晟邦:师从LeCun与谢赛宁,视觉大模型的下一站是World Model即将结束博士生涯的童晟邦,正站在另一个起点上。
来自主题: AI资讯
7802 点击 2026-05-25 15:10
 搜索
搜索
即将结束博士生涯的童晟邦,正站在另一个起点上。
当前,测试时扩展范式普遍致力于增加推理长度。然而,已有研究表明,随着推理长度的持续增长,以垂直扩展为核心的计算范式容易陷入探索僵化等问题。因此,从另一维度拓展推理的宽度显得尤为重要。K2.5、Step3-VL 和 LongCat-Flash-Thinking 等模型已在推理宽度方面开展了有益的探索。
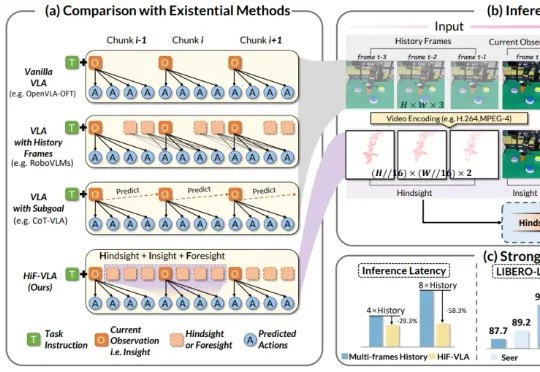
来自西湖大学、浙江大学、西湖机器人等机构的研究团队提出了一种以运动(Motion)为中心的全新双向时空推理框架 HiF-VLA。抛弃冗余的像素级输入,HiF-VLA 巧妙提取低维紧凑的 Motion 向量作为动态先验,在一个创新的「联合专家」模块中,同步完成未来视觉运动的预测与高精度动作序列的生成。
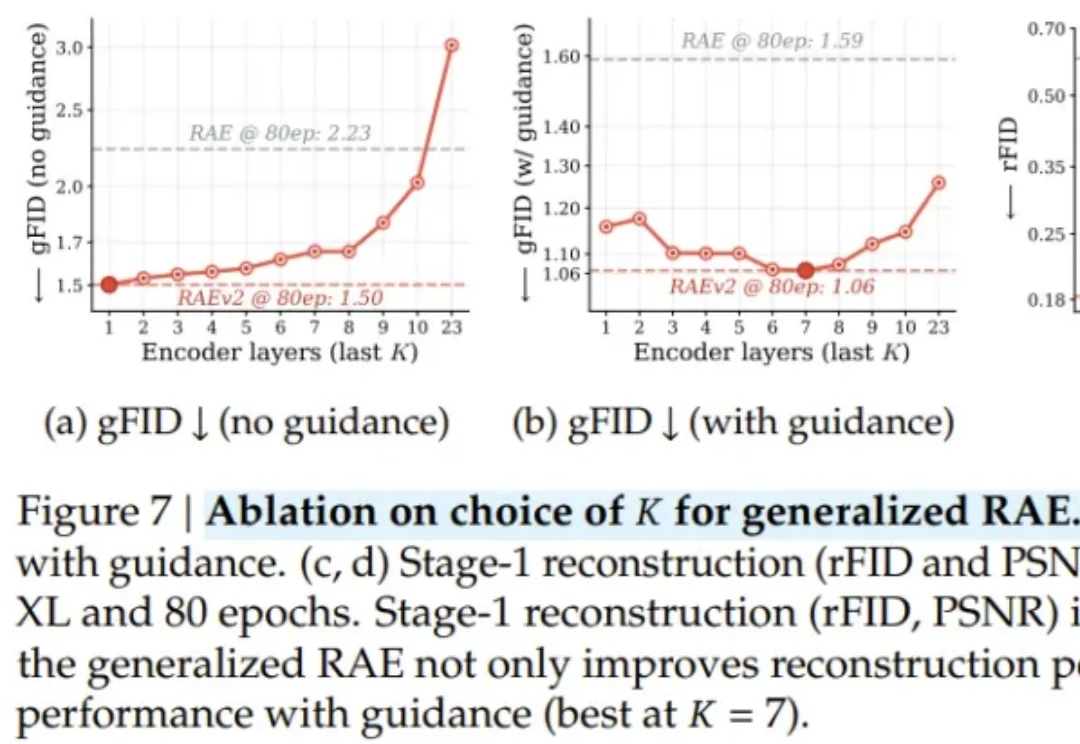
AI 图像生成通常遵循「能力越强、代价越高」的铁律;与此同时,学界却在悄悄质疑另一个更根本的浪费:传统 VAE 对图像语义几乎一无所知,而 DINOv2、SigLIP 等视觉编码器早已从数亿张图片中习得了丰富的视觉常识。图像生成模型,真的需要从零开始「发明」对图像的理解吗?
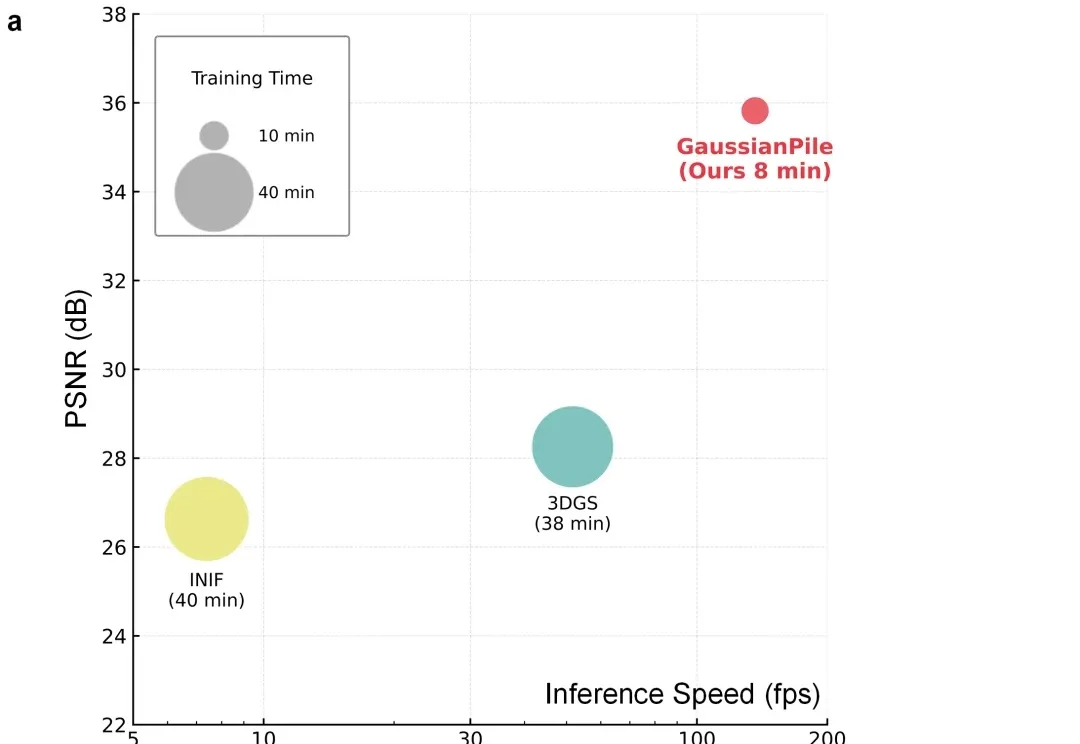
近年来,3D Gaussian Splatting(3DGS)在三维视觉和图形学中展现出很强的表示与渲染能力。相比传统体素或神经辐射场,它用一组可优化的各向异性高斯来表示三维场景,既能保留连续空间结构,又能实现高速渲染。
美图正在布局下一代视觉 AI 入口。
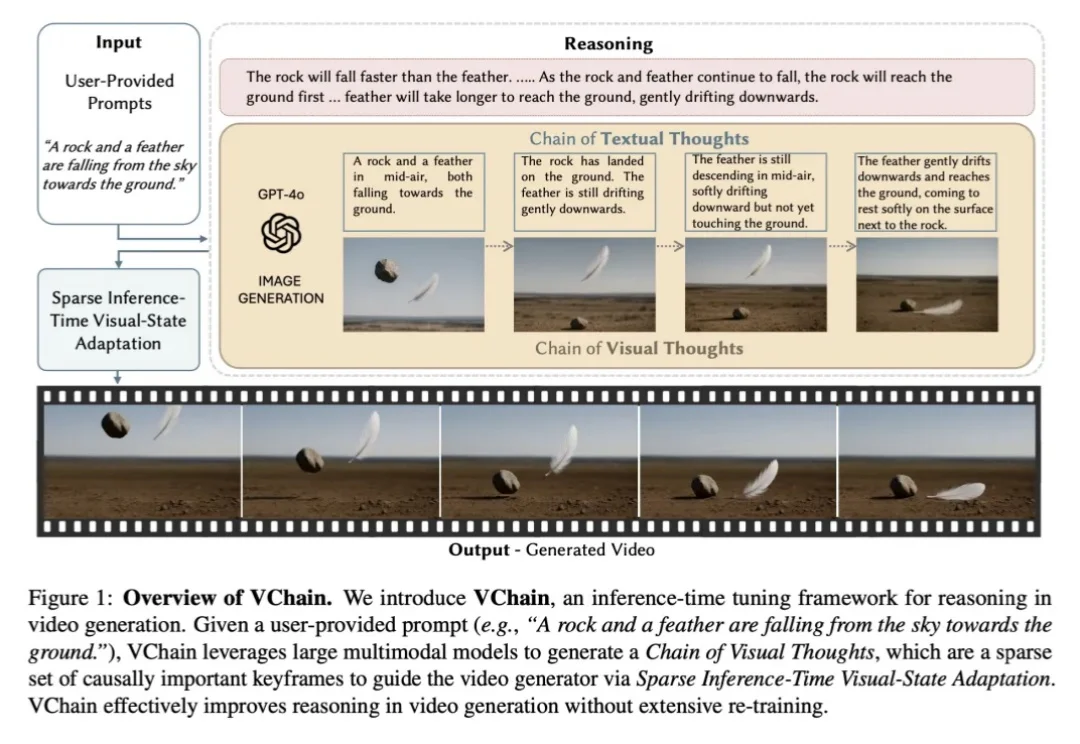
当视频生成模型在视觉保真度上不断突破时,一个核心瓶颈正变得愈发清晰:模型是否真正理解了真实世界?能否推理出合理的演变过程?
阿里正加速Qwen主模型的迭代节奏。
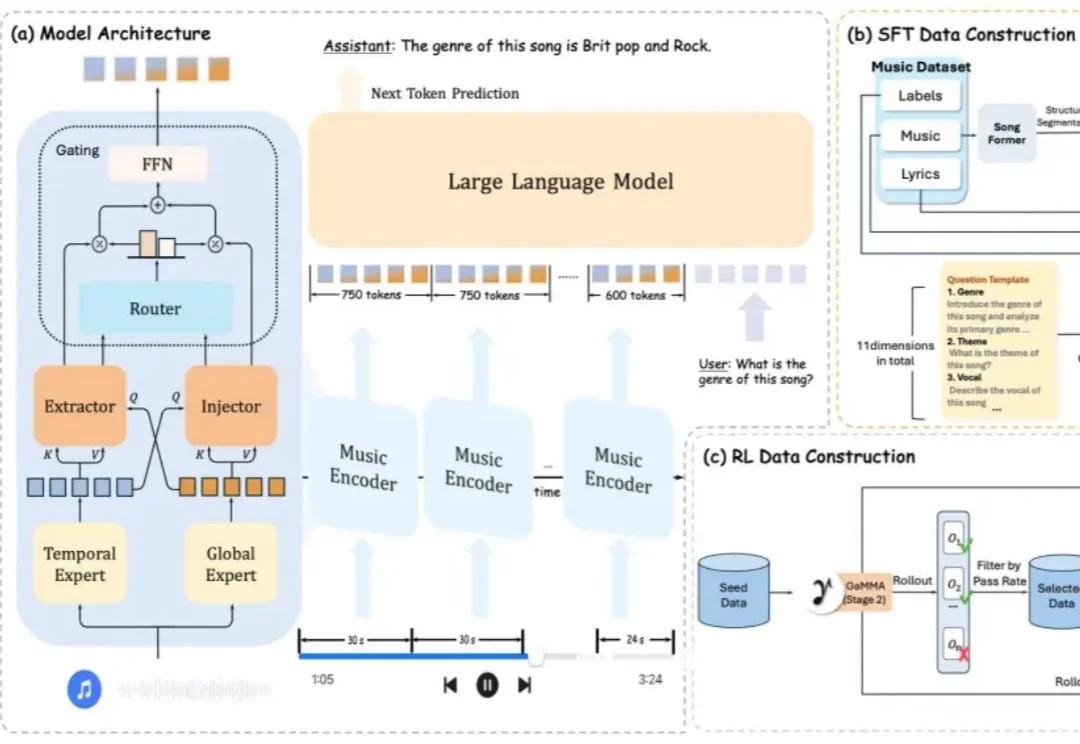
大模型的能力边界正在不断拓展,从文字到视觉,再到音频,全模态理解已渐成现实。然而,当你问一个多模态大模型「这首歌的高潮从第几秒开始?」或者「第 30 秒之后乐器编配发生了什么变化?」,得到的往往是一个模糊甚至错误的回答。

Sam Altman 今天在 X 上扔出一个数字:ChatGPT Images 2.0 在印度已经生成超过 10 亿张图。距离产品发布只有 27 天。TechCrunch 和第三方数据验证了印度确实是最大市场——但全球增长远没有那么均匀,这更像一场区域性起飞。