
指令遵循媲美Seedance 2.0!复旦腾讯联合提出Baton,多说话人场景M-WER暴降76%
指令遵循媲美Seedance 2.0!复旦腾讯联合提出Baton,多说话人场景M-WER暴降76%视频生成,早已不止于视觉。
来自主题: AI技术研报
8511 点击 2026-06-11 15:01
 搜索
搜索
视频生成,早已不止于视觉。

随着视频生成技术的发展,模型正在从短视频片段合成,向流式长视频生成演进。然而,仅仅做到视觉上的逼真是不够的。一个功能完备的视频世界模型,必须能够在长时序交互中保持稳定的内部状态,并遵循真实世界的物理定律与逻辑规则。
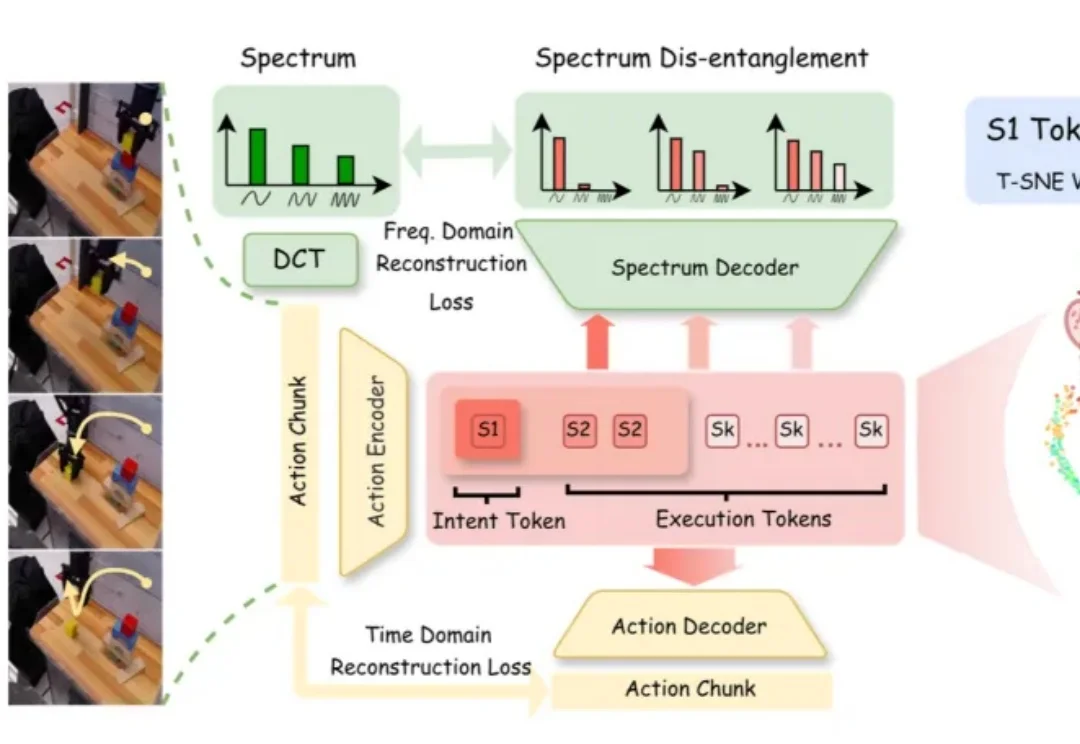
机器人视觉语言动作(Vision-Language-Action, VLA)模型越来越多地开始展示叠衣服、倒茶、做咖啡等复杂操作。但是,今天的大多数 VLA 更像 “展台机器人”。

Meta 发布了一项令人震撼的研究工作 VLM³,首次揭示了三维视觉学习的 Bitter Lesson:标准的视觉语言模型 + scale 数据就是最简单有效的范式,针对特定任务的架构、损失函数以及数据增强的设计,甚至是 regression 的 formulation,均不是三维视觉学习的必要条件。

GPT-5.6发布候选版本kindle-alpha敲定,前端和视觉能力大幅跃升。与此同时,Claude Mythos 5在API中闪现又秒删。双雄争霸,好戏开始!

2026 年 6 月的科罗拉多州丹佛市,全球计算机视觉与模式识别领域的顶级学术盛会 CVPR 正在召开,最前沿的视觉模型、机器人技术、下一代智能系统全都在同一个舞台上被反复讨论和辩证。

近日,来自清华大学智能产业研究院(AIR)的团队联合北京智源研究院(BAAI)、北京大学、南京大学等机构构建了一个基准:GeoCodeBench。这是一个面向 3D 几何计算机视觉的 PhD 级 coding benchmark,
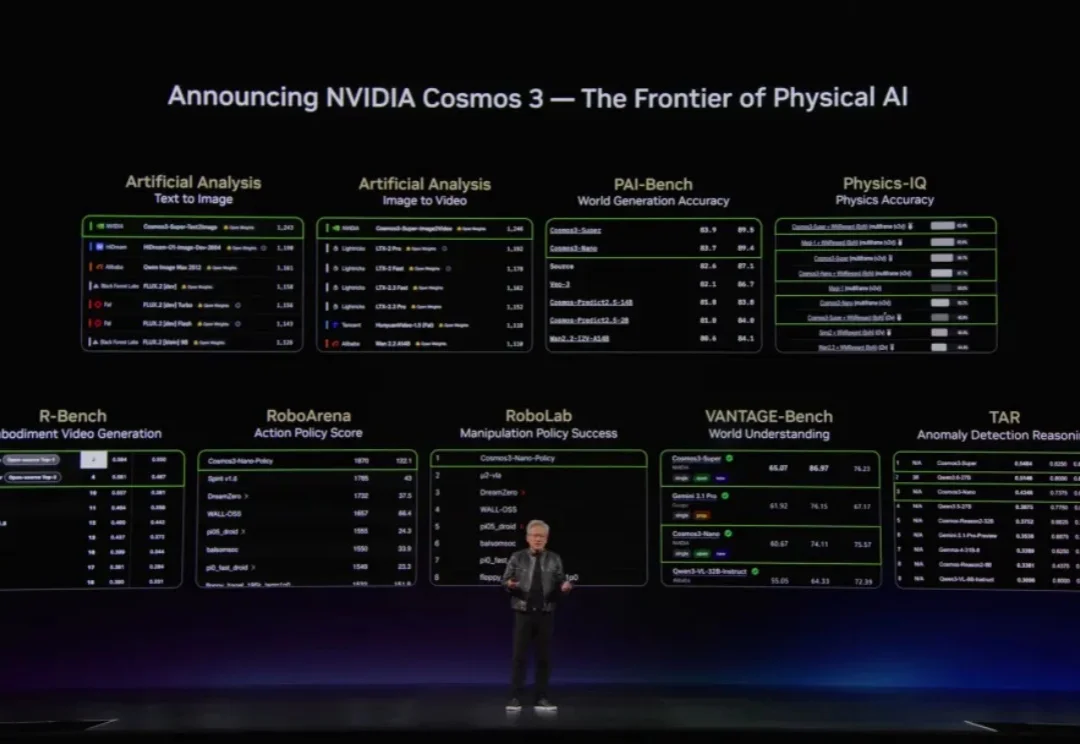
6 月 1 日,老黄在 GTC 上用了不小的篇幅讲物理 AI 和具身智能,并重磅发布了 Cosmos 3。英伟达将其定义为面向 Physical AI 的最新前沿模型,也是全球首个完全开放的全能模型,原生具备视觉推理、世界生成和动作生成能力。

由格灵深瞳灵感实验室主导研发的 LLaVA-OneVision-2.0,是一款面向下一代感知智能的视觉语言大模型。团队充分利用视频 Codec 流和自研 OneVision-Encoder,实现跨帧、跨事件的增量观测和连续证据流建模。本文将详细介绍模型架构、训练方法与能力验证,展示该技术在视频理解、空间推理和目标追踪等任务中的应用潜力。
本文团队长期从事负责任的人工智能与人工智能赋能社会科学相关研究,围绕视觉生成大模型安全治理、智能体安全等方向开展系统性工作,相关成果发表于AAAI、ICML、TMM 等国际期刊与会议。