
前馈式3D的终极路线图来了!五大核心战线,一文看清未来三维重建该往哪走
前馈式3D的终极路线图来了!五大核心战线,一文看清未来三维重建该往哪走从单幅图像恢复三维结构,到多视图场景建模、动态 4D 重建,再到机器人、自动驾驶、SLAM 与视频生成,如何让模型在不依赖逐场景优化的前提下,直接、高效地理解并重建三维世界,正在成为 3D 视觉领域的
来自主题: AI技术研报
9644 点击 2026-04-26 12:09
 搜索
搜索
从单幅图像恢复三维结构,到多视图场景建模、动态 4D 重建,再到机器人、自动驾驶、SLAM 与视频生成,如何让模型在不依赖逐场景优化的前提下,直接、高效地理解并重建三维世界,正在成为 3D 视觉领域的

最近,谷歌联合ResNet作者何恺明、谢赛宁、NeRF先驱Jonathan T. Barron、 3D图形学名家Thomas Funkhouser,正式发布了Vision Banana。它向世界宣告:视觉AI终于不再需要那些臃肿的任务头了,理解,本质上只是生成过程中的一次「对齐」。
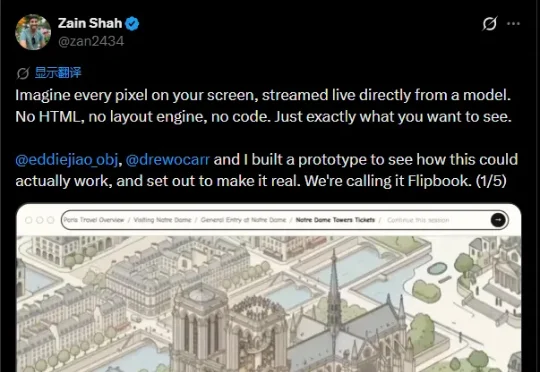
想象一下:你打开浏览器,没有代码、没有 HTML、没有 CSS 布局引擎。屏幕上每一帧画面,都是 AI 模型实时生成的像素视频流。满满的科幻降临既视感!这就是 Zain Shah(前 OpenAI、YC 校友)和团队刚刚发布的 Flipbook 原型。
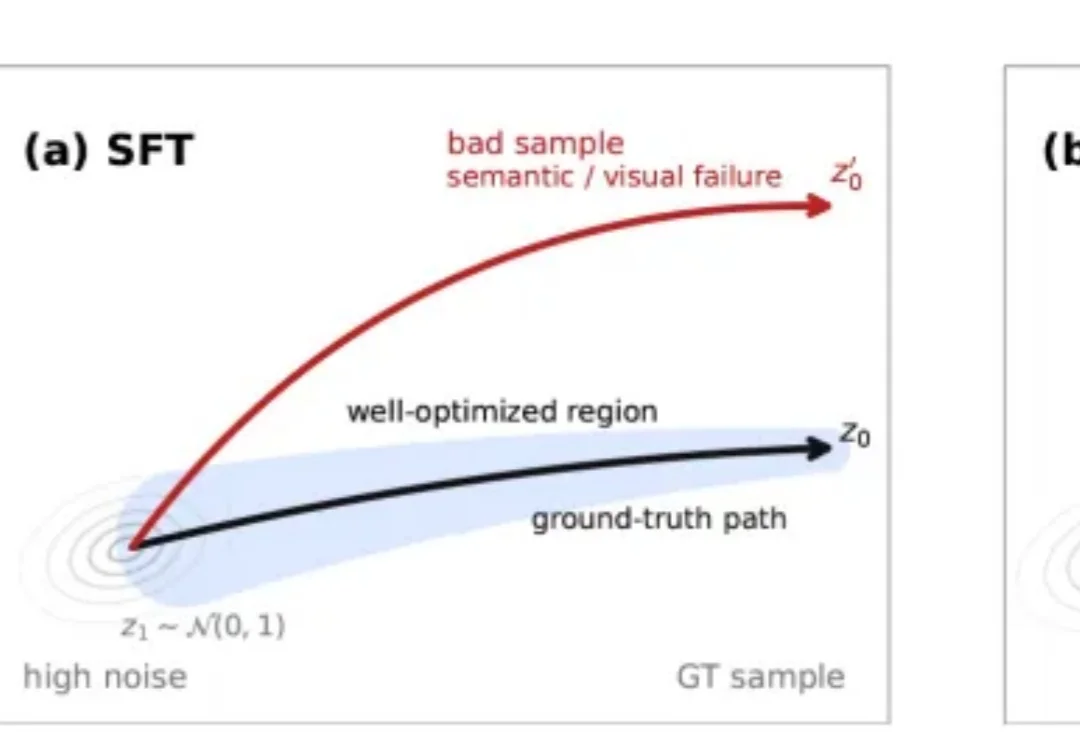
近日,腾讯混元团队提出HY-SOAR (Self-Correction for Optimal Alignment and Refinement),一种面向扩散模型和流匹配模型的数据驱动后训练方法。
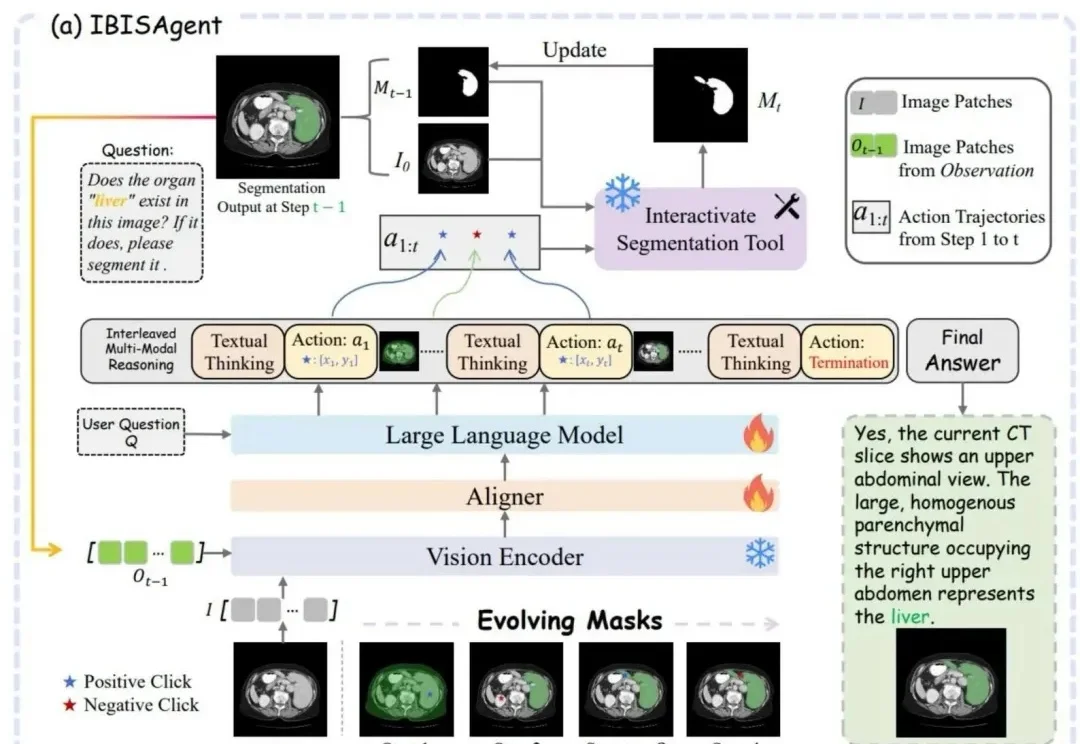
这个生物医学视觉推理框架,被CVPR 2026接收了!

北京时间凌晨 3 点,直播准时开始,OpenAI 发布了 ChatGPT Images 2.0。据介绍,「ChatGPT Images 2.0 是下一步进化:一个最先进的模型,能够处理复杂的视觉任务,并生成精确、可直接使用的视觉内容。」
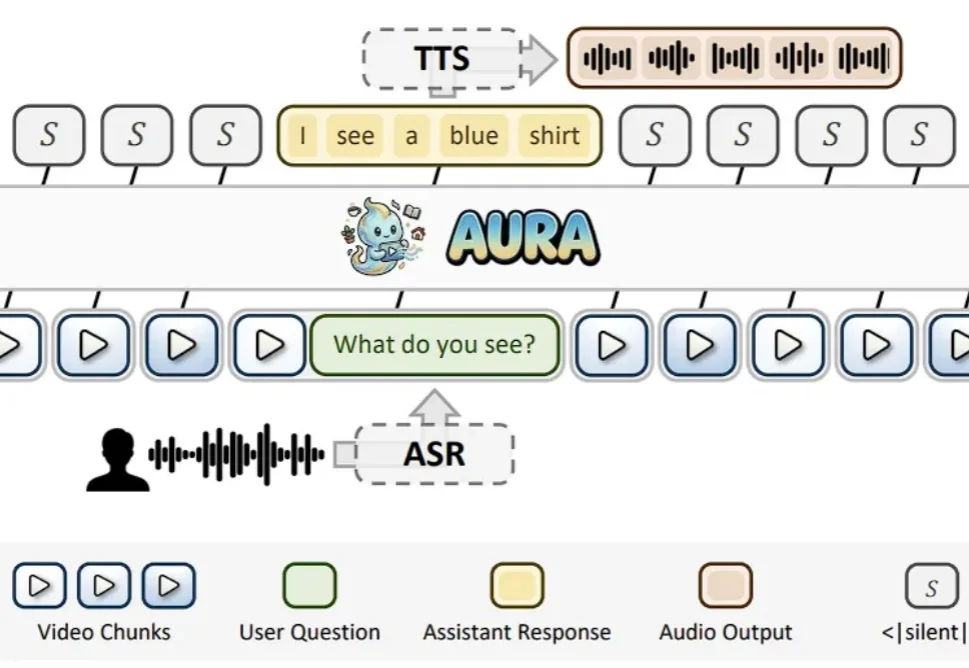
近年来,视频多模态大模型(VideoLLM)发展迅猛,在视频描述、视频问答、时序定位等任务上不断刷新性能上限。随着模型能力持续增强,业界也开始思考一个更重要的问题:视频大模型能不能不再只是 “看完一段视频再回答”,而是真正进入实时世界,持续观察、实时理解,并在关键时刻主动给出反馈?

3B激活参数,视觉能力直逼Claude Sonnet 4.5。
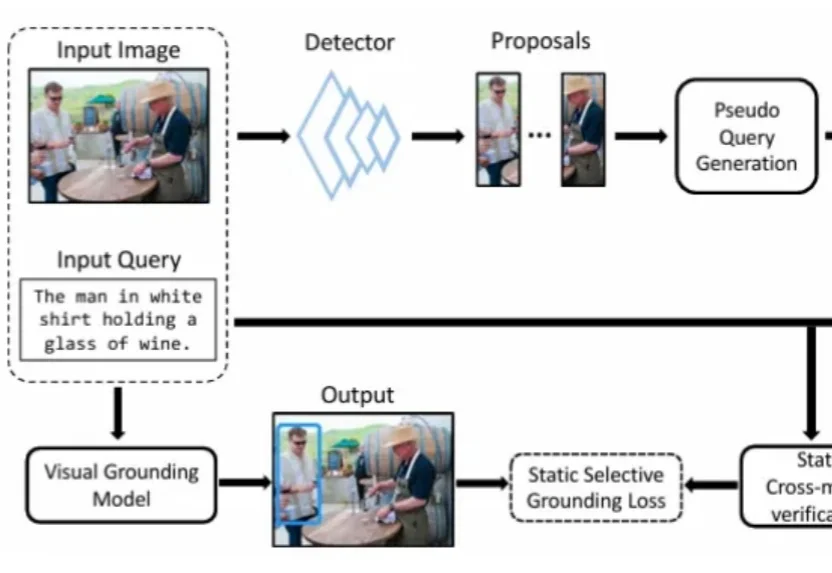
本文是北京大学彭宇新教授团队在视觉定位方向的最新研究成果,相关论文已被顶级国际期刊 IEEE TPAMI 接收。为视觉定位模型赋予「自知之明」能力 —— 通过自监督的关联校正与验证模块,在训练过程中动态识别、衰减并纠正错误的监督信号。大量实验证明,让模型学会「自我纠错」,是突破弱监督视觉定位瓶颈的有效途径。

两眼一睁,Claude又更新了。Anthropic发布新一代旗舰大模型Claude Opus 4.7。该模型在高级软件工程方面相比Opus 4.6有显著提升,尤其在处理最复杂的任务时提升明显;高分辨率图像处理能力大幅提升,是此前Claude模型的3倍以上