只看图片就能学会压缩Token!浙大&阿里新框架多轮VQA压缩率90%,精度不掉|CVPR 2026
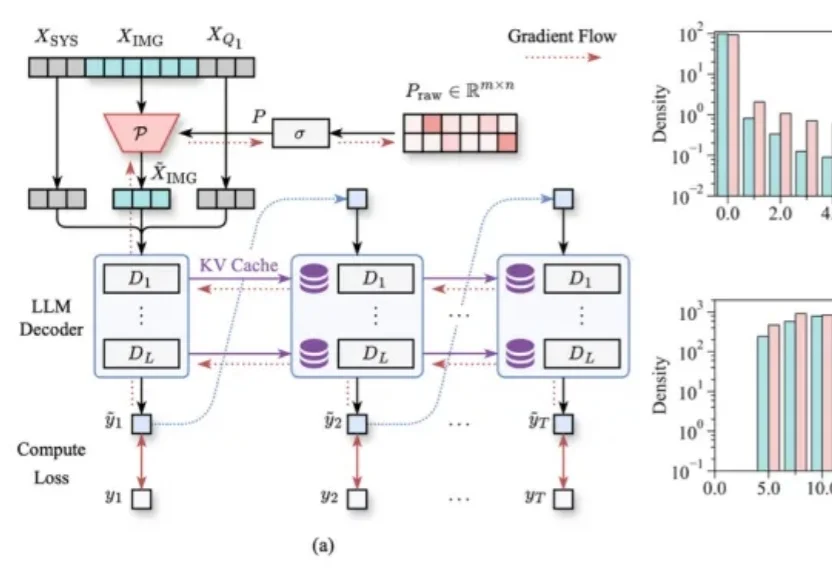
只看图片就能学会压缩Token!浙大&阿里新框架多轮VQA压缩率90%,精度不掉|CVPR 2026多轮视觉问答,正在成为LVLM推理效率的“照妖镜”。
来自主题: AI技术研报
8736 点击 2026-05-08 09:52
 搜索
搜索
多轮视觉问答,正在成为LVLM推理效率的“照妖镜”。

为了攻克这些制约具身智能领域发展的核心难题,清华大学智能产业研究院(AIR)DISCOVER Lab联合谋先飞技术、原力灵机、求之科技和地瓜机器人,提出了GS-Playground通用多模态仿真框架。

GPT Image 2的发布给整个AI圈带来了亿点点震撼。但很多人可能没注意到,幕后最会玩梗的居然是他——主力训练者陈博远。他和奥特曼同台主持,悄悄修好了中文渲染;给模型起代号“布基胶带”,还拿香蕉艺术品玩梗;为了秀模型的文字能力,设计了米粒刻字、漫画套娃、视觉证明题这些“彩蛋级”测试。

基于视觉语言模型(VLM)的多智能体系统(MAS)正成为复杂多模态协作的核心方案,却被一个致命痛点死死卡住:多智能体视觉幻觉滚雪球——单个智能体的视觉误判通过纯文本信息流逐级放大,早期细微错误最终演变成系统性崩溃。
刚刚,DeepSeek 在 Github 上正式发布了多模态模型,公布了背后的技术报告。实打实的新鲜出炉!而且是开创性的推理范式。下面我们就基于 DeepSeek 这篇技术报告,具体看看 DeepSeek、北京大学、清华大学又创造了怎样的奇迹。
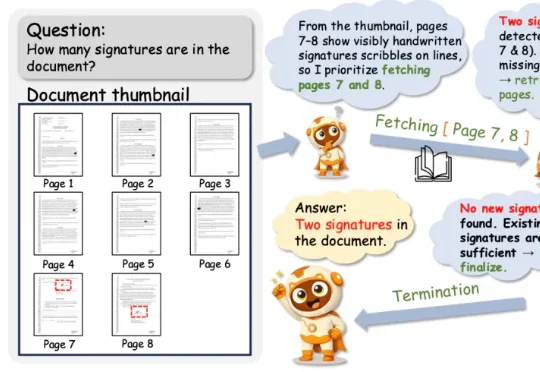
Doc-V* 由小米大模型 Plus 团队和华中科技大学 VLRLab 团队合作提出,一种从「静态阅读」到「主动探索」的多页文档理解新范式,通过交互式视觉推理让模型像人一样有策略地阅读长文档。
英伟达于昨日正式推出全新多模态推理模型Nemotron 3 Nano Omni,将文本、视觉、语音三大模态能力深度融合至单一模型体系,目前可免费使用。

Anthropic今天宣布与Blender、Autodesk、Adobe、Ableton、Splice等多家合作伙伴联合推出一批连接器,涵盖了3D建模、平面设计、音乐制作和现场视觉等多个领域的创意工具,让Claude能够直接在创意专业人士日常使用的软件中运行。
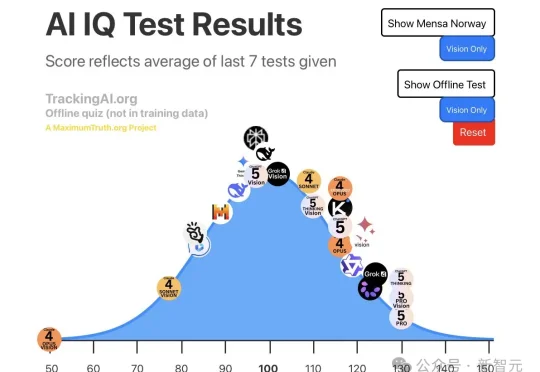
1946年至今,「人类最高智商俱乐部」门萨将迎来第一位非人类成员。根据LisanBench最新跑分,GPT-5.5 Pro文本IQ 130踩上门萨会员线,视觉IQ直接飙到145,杀进天才区。一年前「LLM过不了130」还是技术圈共识,今天,这堵墙彻底被砸碎!

创始人张霄昨天,2026年4月23日,宣布融资2300万美元,也成立了Collov Labs Research,资金用于扩充研究团队和加速视觉AI系统研发,而非单纯的商业扩张。