Depth Anything再出新作!浙大&港大出品:零样本,优化任意深度图
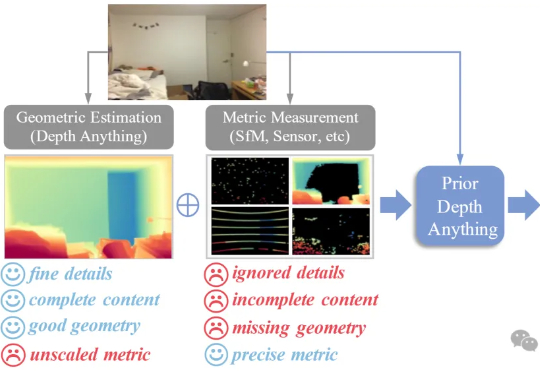
Depth Anything再出新作!浙大&港大出品:零样本,优化任意深度图浙江大学与港大团队推出「Prior Depth Anything」,把稀疏的深度传感器数据与AI完整深度图融合,一键补洞、降噪、提分辨率,让手机、车载、AR眼镜都能实时获得精确三维视觉。无需额外训练,就能直接提升VGGT等3D模型的深度质量,零样本刷新多项深度补全、超分、修复纪录。
来自主题: AI技术研报
8346 点击 2025-09-24 09:52