

卡帕西开源Agent自进化训练框架,5分钟一轮实验,48h内揽星9.5k
卡帕西开源Agent自进化训练框架,5分钟一轮实验,48h内揽星9.5k大神Karpathy又开源了新项目——一个能够自主进化的AI科研循环系统。这个项目名叫autoresearch,主打让智能体完全自主地搞科研,只要在Markdown文档里写好指令,剩下的流程全都由AI自动完成。
来自主题: AI技术研报
7323 点击 2026-03-09 18:28
大神Karpathy又开源了新项目——一个能够自主进化的AI科研循环系统。这个项目名叫autoresearch,主打让智能体完全自主地搞科研,只要在Markdown文档里写好指令,剩下的流程全都由AI自动完成。
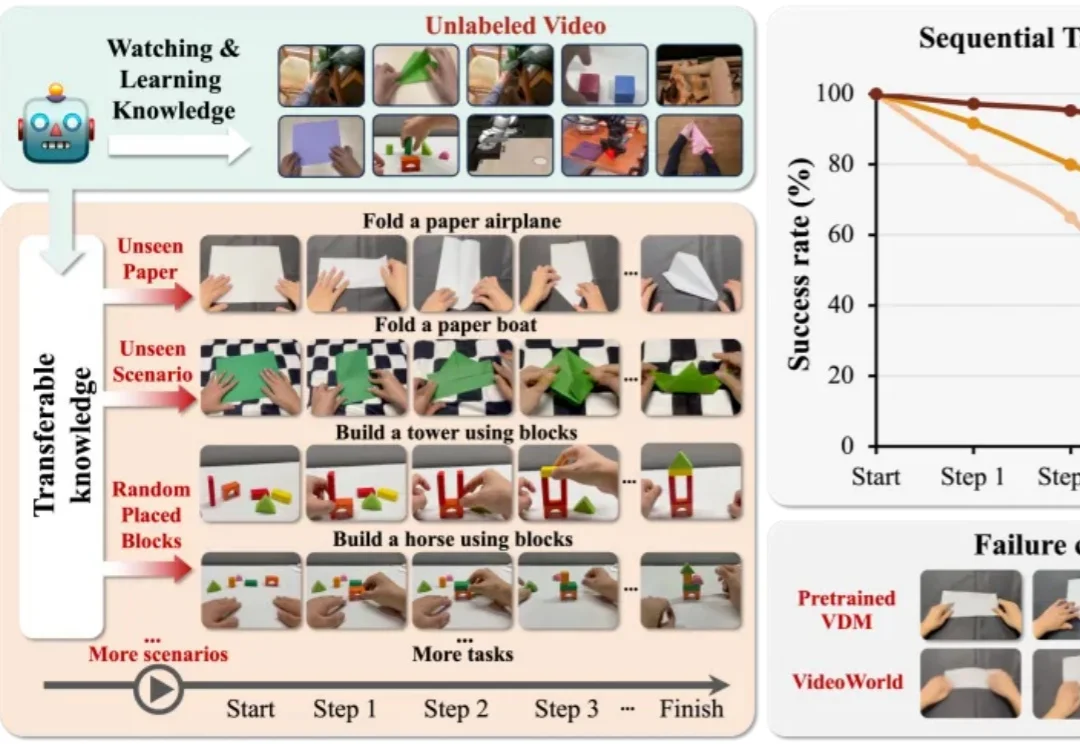
视觉世界模型 “VideoWorld 2” 由豆包大模型团队与北京交通大学联合提出。不同于 Sora 2 、Veo 3、Wan 2.2 等主流多模态模型,VideoWorld 系列工作在业界首次实现无需依赖语言模型,即可认知世界。

港科大团队提出音频生成统一模型AudioX,只需一个模型,就能从文本、视频、图像等任意模态生成高质量音效和音乐,在多项基准上超越专家模型。团队同时开源了700万样本的细粒度标注数据集IF-caps与可控T2A评测基准T2A-bench,并在该基准上大幅领先现有方法。论文已被ICLR 2026接收。
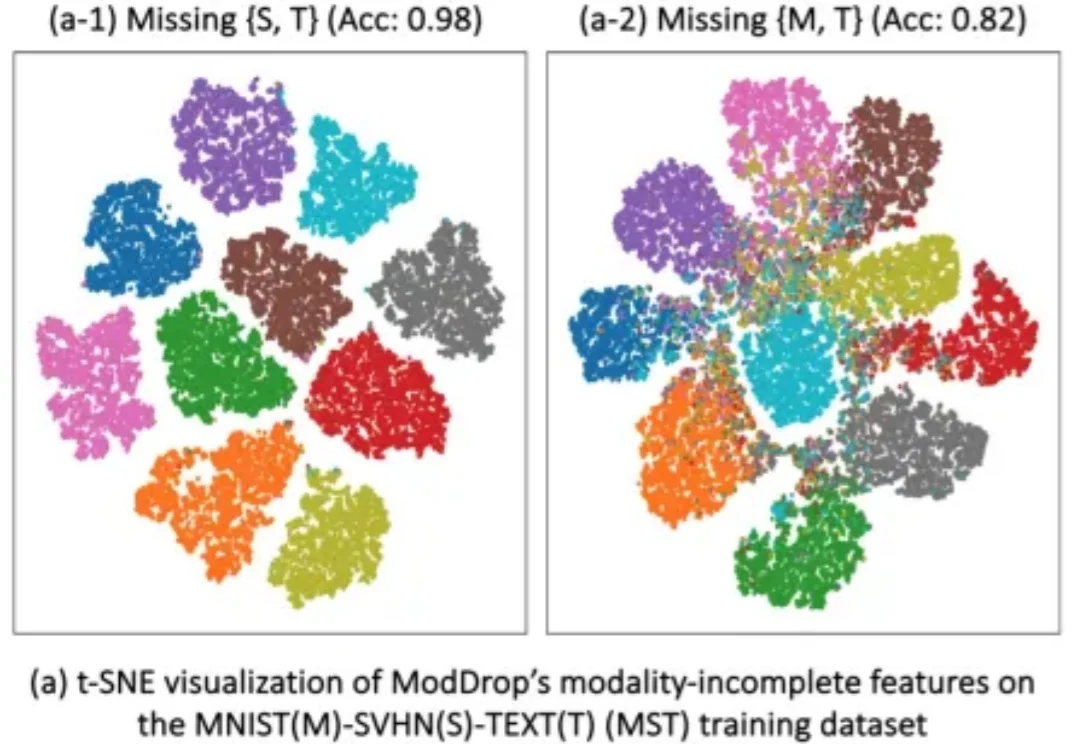
多模态学习(Multimodal Learning)正在推动 AI 在医学影像、自动驾驶、人机交互等领域取得突破。通过融合图像、文本、表格等多种模态,模型能够获得更全面的信息,从而显著提升性能。

十亿参数的三维重建模型,能塞进手机吗?
沉寂许久的 Ian Goodfellow,终于再次现身。

基础模型时代,大模型能力的爆发,很大程度上源于在海量文本上的预训练。然而问题在于,文本本质上只是人类对现实世界的一种抽象表达,是对真实世界信息的有损压缩。
「2018 到 2023 年间在 EMNLP 会议上发表的那篇论文中,第一作者本科就读于达特茅斯学院、第四作者本科就读于宾夕法尼亚大学的那篇科学论文,题目是什么?」
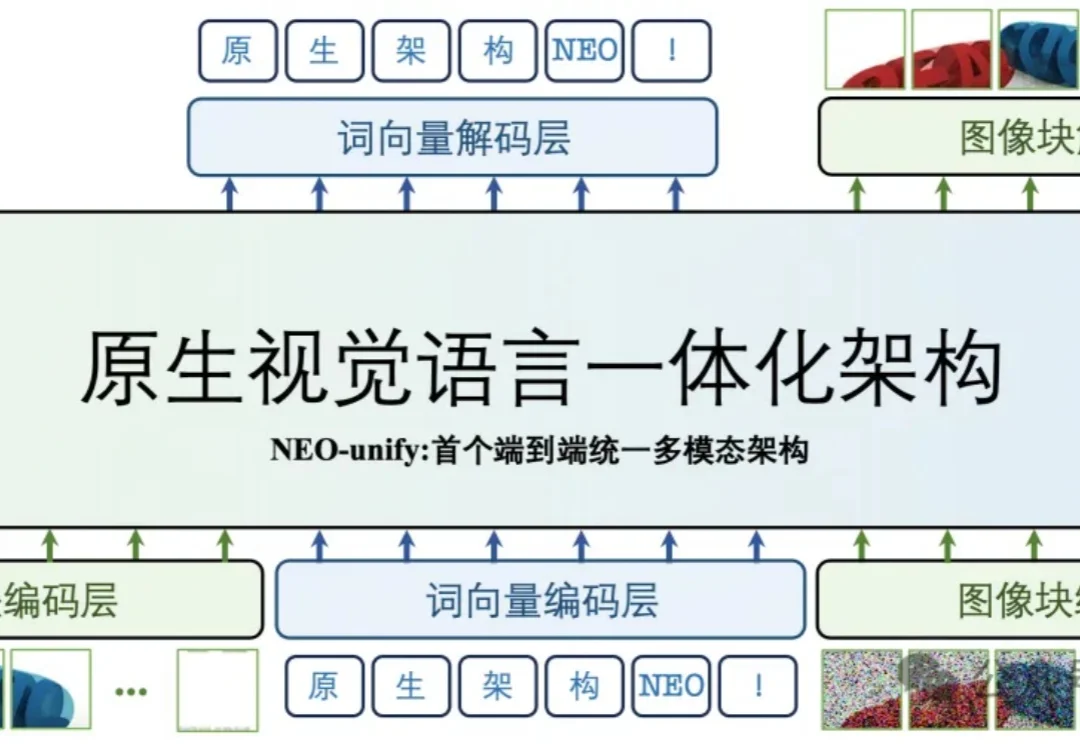
多模态大模型的研发范式,正在被彻底重构。
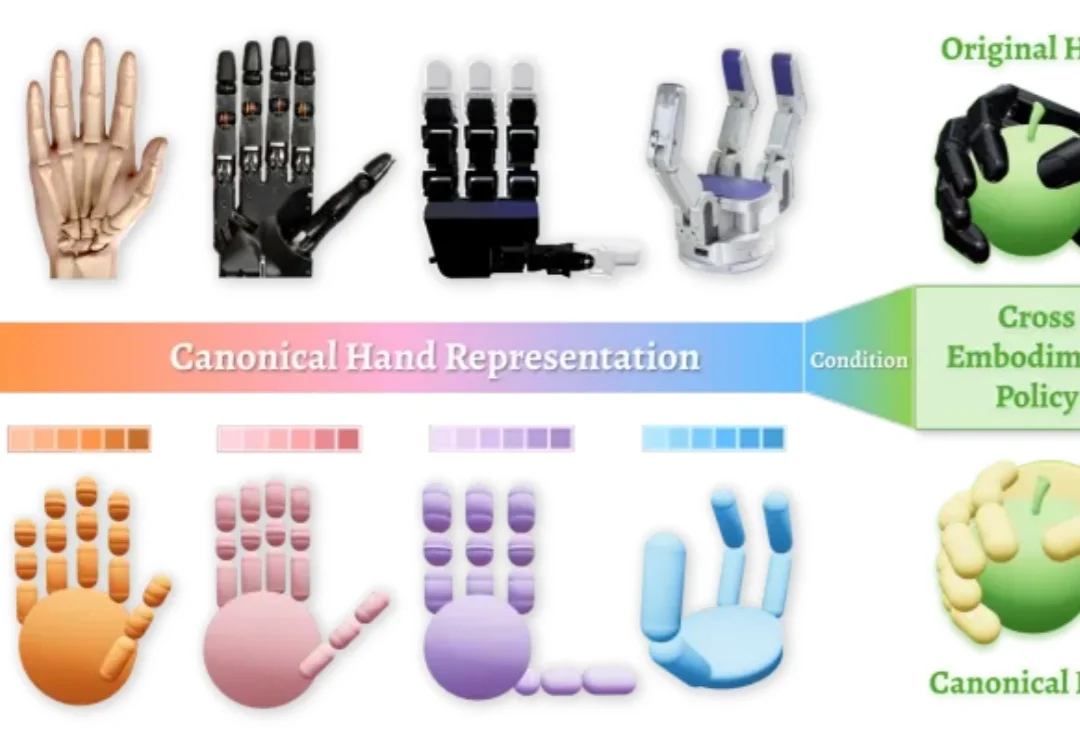
在机器人操作领域,一个长期悬而未决的核心问题始终困扰着研究者: 面对形态各异的灵巧手,我们是否注定要为每一种手型单独设计表示方式与控制策略?