
谢赛宁也玩MC?开源全新世界模型生成多人一致的游戏视角
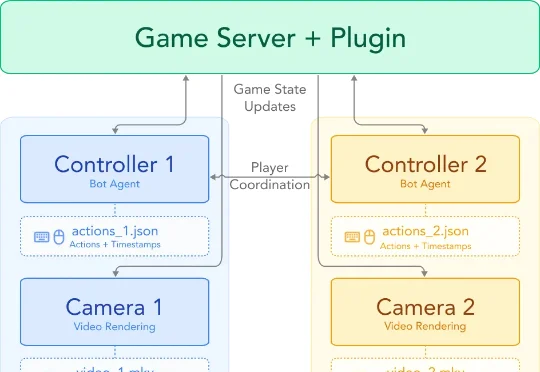
谢赛宁也玩MC?开源全新世界模型生成多人一致的游戏视角谢赛宁团队的最新视频世界模型 Solaris,首个多人视频世界模型,能够同时生成多个玩家之间保持一致的第一视角。研究团队发现,目前的视频世界模型仅能处理单人视角,这并不能反映现实世界的真实运作方式,希望能够能够实现多人同步观察一个统一世界。于是,研究团队把视角投向了电子游戏。
来自主题: AI技术研报
5406 点击 2026-03-08 13:23
谢赛宁团队的最新视频世界模型 Solaris,首个多人视频世界模型,能够同时生成多个玩家之间保持一致的第一视角。研究团队发现,目前的视频世界模型仅能处理单人视角,这并不能反映现实世界的真实运作方式,希望能够能够实现多人同步观察一个统一世界。于是,研究团队把视角投向了电子游戏。
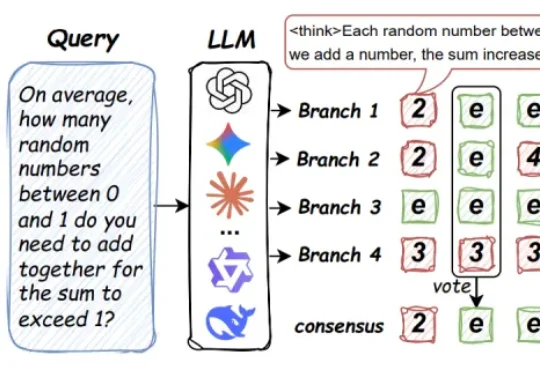
来自马里兰大学、圣路易斯华盛顿大学、北卡罗来纳大学教堂山分校等机构的研究团队提出了 Parallel-Probe。不同于直接从算法设计出发,该研究首先通过引入 2D Probing,对 online 并行推理过程中的全局动态性进行了系统性刻画。
Claude立大功!开发者靠它剖析MIL语言与E5二进制,绕过CoreML直达硬件,证明NPU训练从来不是硬件不行,而是苹果不让用。

是不是经常纠结于 VLA(视觉 - 语言 - 动作)模型的训练技巧?面对层出不穷的 VLA 算法,是不是常常感到眼花缭乱,不知道哪种数据模态、训练策略最有效? 别急,丰田研究院(TRI)和清华大学刚刚

现在,一篇来自 CISPA 亥姆霍兹信息安全中心的最新论文《Real Money, Fake Models: Deceptive Model Claims in Shadow APIs》为我们揭开了一点谜底:那些你花真金白银购买的「第三方 API」,有可能偷偷把前沿大模型换成了廉价的替代品。
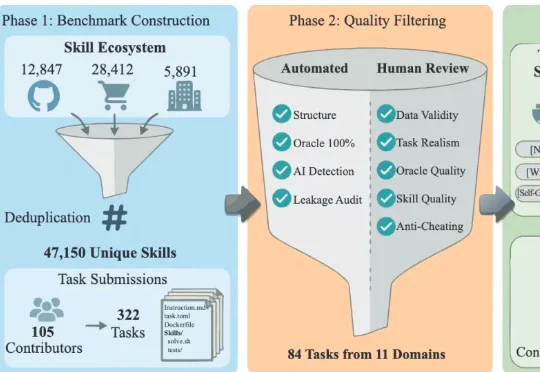
近日,一篇名为《SkillsBench: Benchmarking How Well Agent Skills Work Across Diverse Tasks》的论文预印本引爆了海外 AI 社区,YC 总裁 Garry Tan 亲自转发,登顶 Hacker News(363 票 / 163 评论),霸榜 AlphaXiv #1,

3月6日,腾讯混元发布了一篇名为“HY-WU (Part I): An Extensible Functional Neural Memory Framework and An Instantiation in Text-Guided Image Editing”的技术报告。提出了一种崭新的功能性记忆(functional neural memory)范式(weight unleashing),

近日,深度学习领域重要底层优化技术 FlashAttention 迎来大版本更新。FlashAttention 核心作者、普林斯顿大学助理教授 Tri Dao 表示,在 Blackwell GPU 上,即使瓶颈截然不同,注意力机制的执行速度现在也几乎与矩阵乘法一样快了!
近期,大连理工与快手可灵团队推出了 MultiShotMaster—— 一个高度可控的多镜头视频生成框架,该论文向研究社区展示了即使在 1B 左右的小参数量级模型上,也可以实现导演级的镜头调度和连贯叙事,且支持多图参考、主体运动控制。
昨天,Thinking Maching Lab 研究者、斯坦福大学博士生 Zitong Yang 正式完成了他的博士论文答辩,课题为「持续自我提升式 AI」(Continually self-improving AI),并且他在答辩完成后很快就放出了自己的答辩视频,从中我们可以看到他对未来 AI 发展路径的系统性探索。