

成立一年半累计融资超 20 亿,这个团队想搞定具身智能最难的「数据瓶颈」
成立一年半累计融资超 20 亿,这个团队想搞定具身智能最难的「数据瓶颈」用「无本体数采」的方式训练具身模型,灵初智能的这条路径是 VLA 之后行业最热的方向之一。
来自主题: AI资讯
7528 点击 2026-03-10 15:10
用「无本体数采」的方式训练具身模型,灵初智能的这条路径是 VLA 之后行业最热的方向之一。

DragStream,首次实现视频生成时的实时拖拽编辑。用户可随时拖动画面中的物体,自由平移、旋转或变形,系统自动保持后续帧连贯自然,无需重训模型,无缝适配主流AI视频生成器,真正实现「所见即所得」。

视频生成进入大规模时代,但计算成本也炸了。
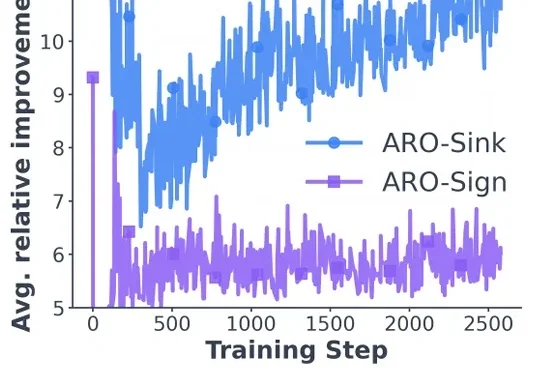
如果你在过去一年关注过大模型训练的技术,大概率听过 Muon 这个名字 —— 这个在月之暗面 K2 模型的相关讨论中走红的优化器,被视为是可能挑战 Adam 的新秀。它的思路很直接:对动量矩阵进行正交化,让各个奇异方向上的更新速率一致,提升训练效率。
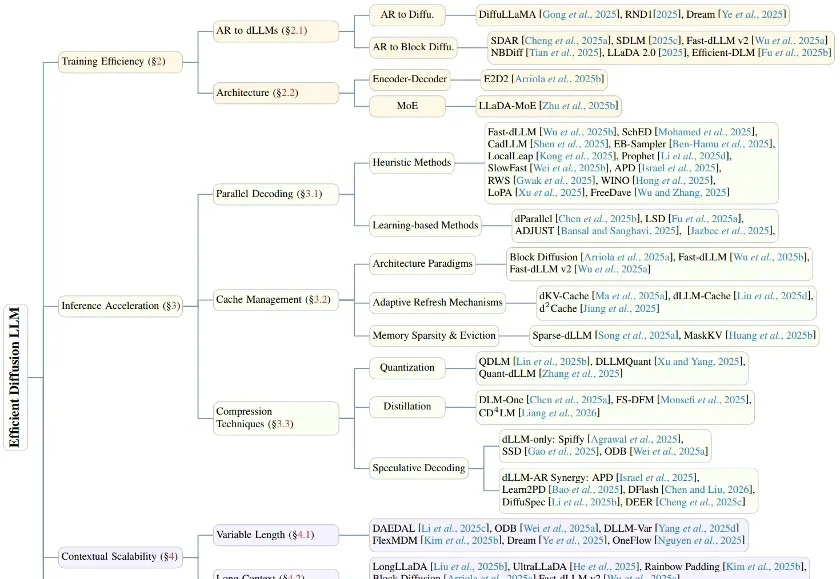
在生成式 AI 的浪潮中,自回归(Autoregressive, AR)模型凭借其卓越的性能占据了统治地位。然而,其「从左到右」逐个预测 Token 的串行机制,天生限制了并行生成的可能性。
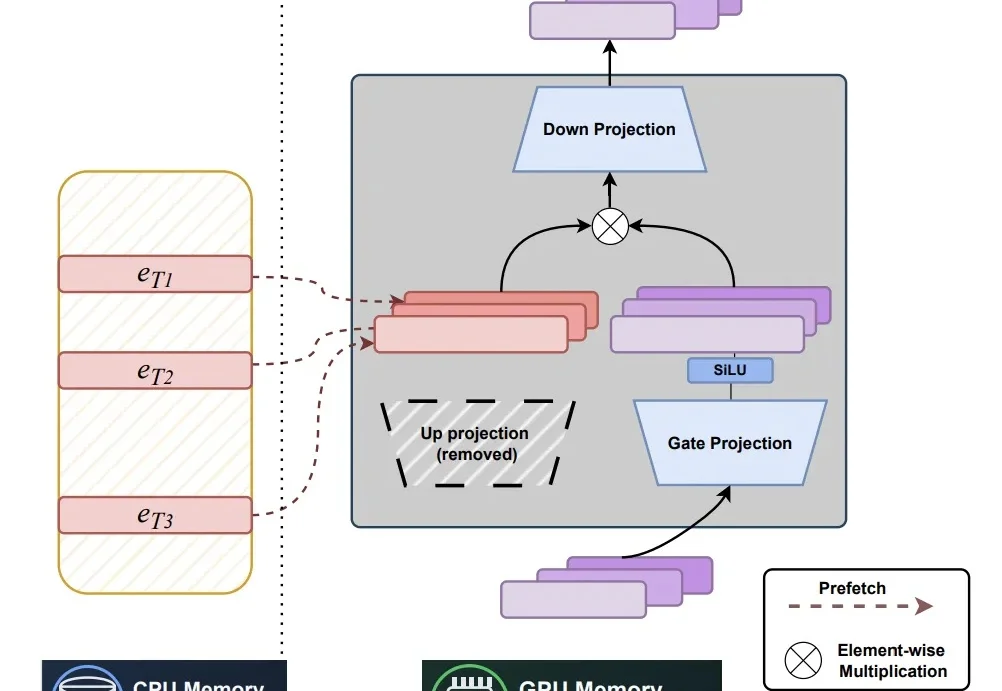
近年来,随着大语言模型规模与知识密度不断提升,研究者开始重新思考一个更本质的问题:模型中的参数应如何被组织,才能更高效地充当「记忆」。
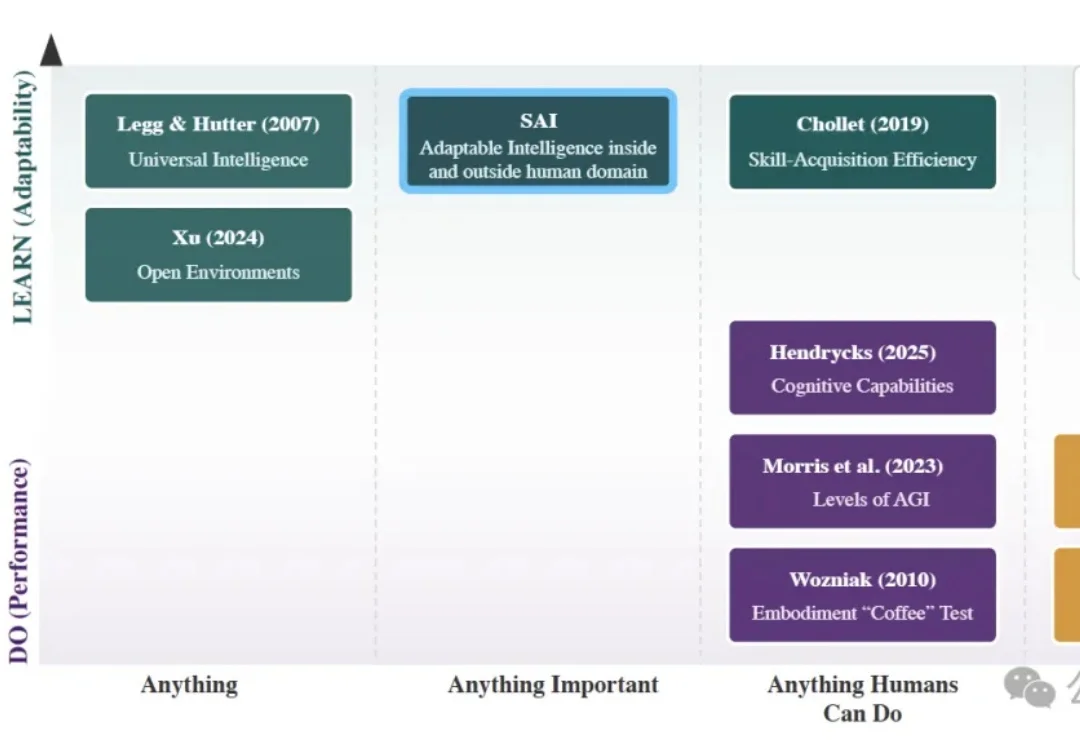
AI圈追逐多年的通用人工智能(AGI),可能从一开始就走偏了。

在 AI 视觉生成领域,扩散模型(DM)凭借其强大的高保真数据生成能力,已成为图像合成、视频生成等多模态任务的核心框架。然而,预训练后的扩散模型如何高效适配下游应用需求,一直是行业面临的关键挑战。

自扩散模型提出以来,它不仅在图像、视频和音频生成方面取得了优异效果,也正逐渐成为解决图像复原、超分辨率、去模糊等逆问题的重要工具。

智东西3月9日消息,近日,由前vivo与理想汽车产品负责人宋紫薇创立的薇光点亮完成超1亿元人民币的Pre-A轮融资。此轮融资由由红杉中国、蓝驰创投联合领投,蚂蚁战投、鼎晖投资、鞍羽资本跟投,老股东九合创投持续追投,所筹资金将重点用于人才梯队建设、新型智能硬件研发、垂类模型训练及时尚Agent关键应用场景落地。