
Qwen3.5-397B+Milvus+ColQwen2,如何做基于PDF的多模态RAG知识库
Qwen3.5-397B+Milvus+ColQwen2,如何做基于PDF的多模态RAG知识库最近关于Qwen3.5还有其幕后团队,市场上的讨论沸沸扬扬,但今天我们不聊八卦,主要讲讲干货。
来自主题: AI技术研报
8461 点击 2026-03-06 09:33
最近关于Qwen3.5还有其幕后团队,市场上的讨论沸沸扬扬,但今天我们不聊八卦,主要讲讲干货。

AI 搜索引擎正逐渐取代传统搜索入口,「问 AI」已经成为日常习惯。随着 OpenAI 宣布在 ChatGPT 中引入商业推荐,搜索与内容分发的边界正在被重新定义。在这样的环境下,你的内容能否在 AI 搜索中成为「爆款」,不再只取决于标题和流量,而是更大程度取决于 AI 本身的引用偏好。
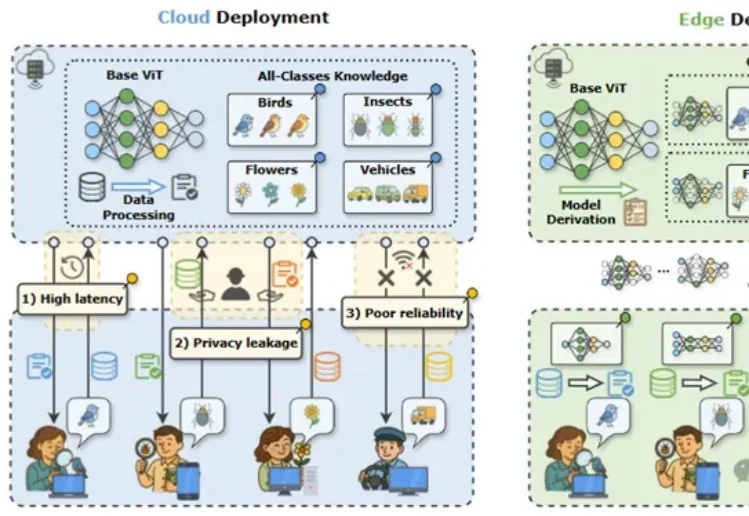
近年来,视觉大模型在自动驾驶、智慧医疗等场景中得到广泛应用,但在真实业务环境中,“大而全”的通用模型往往并不是最优选择。
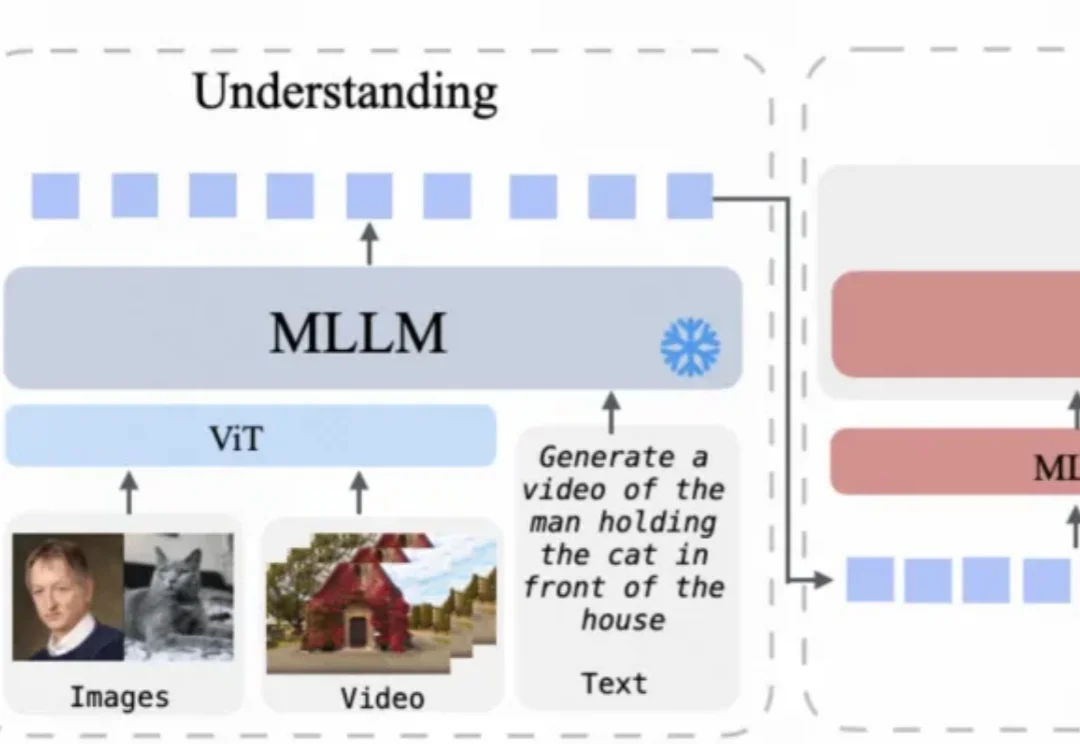
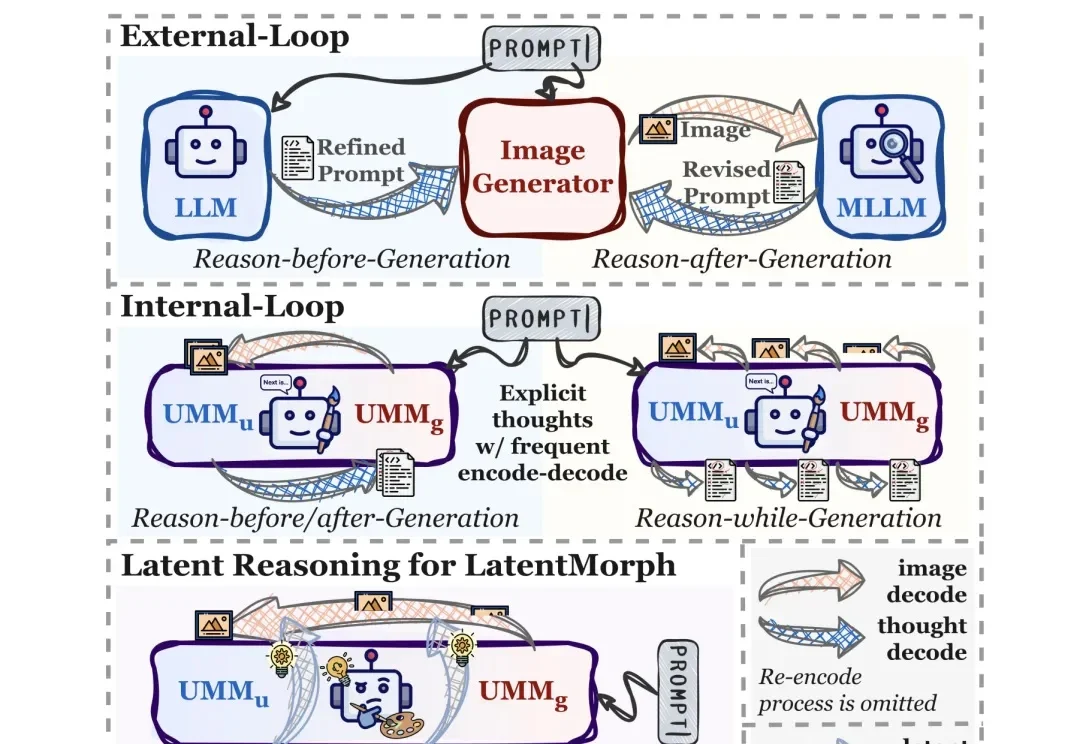
统一多模态模型在多模态内容理解与生成方面已展现出良好效果,但目前仍主要局限于图像领域。
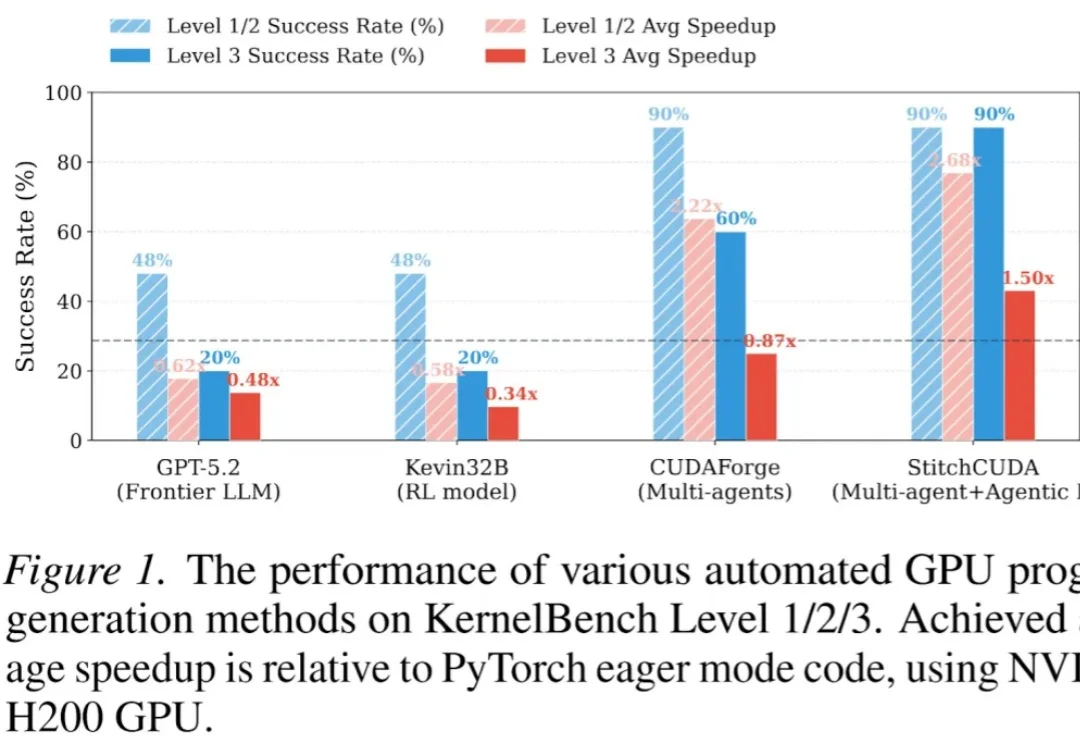
现有的 LLM 自动化 CUDA 方法大多只能优化单个 Kernel,面对完整的端到端 GPU 程序(如整个 VisionTransformer 推理)往往束手无策。
人类在创作艺术时,大脑并非一味地输出,而是在每一笔落下时都在进行着复杂的、难以言表的 “视觉优化”。

长期以来,计算机视觉领域陷入了一个 “表征(Representation)” 的执念。我们习惯设计各种精巧的 Encoder,试图将动态世界压缩成一组特征向量。然而,视频作为现实的高维投影,其熵值之高、动态之复杂,让这种试图 “定格” 的表征显得力不从心。

近日,NVIDIA 发布的世界 - 动作模型 DreamZero,在两项颇具代表性的机器人基准测试 RoboArena 、MolmoSpaces 上双双登顶。
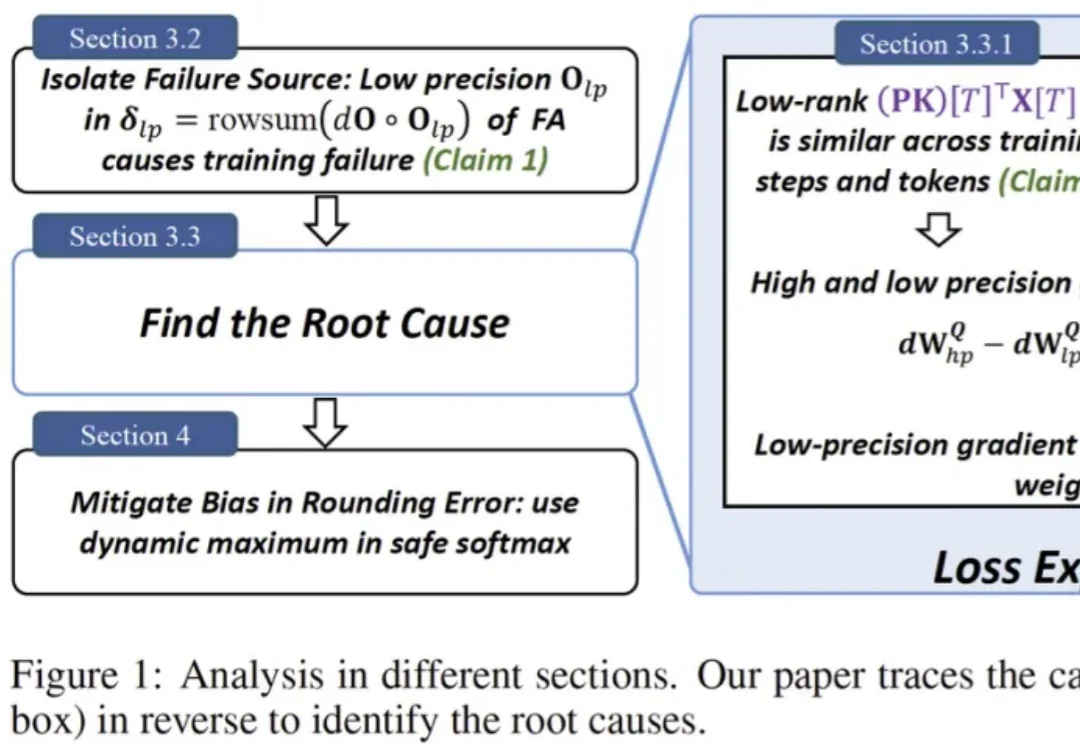
一句话总结:社区里困扰了多年的一个 “玄学” 现象终于被拆解清楚了:在 BF16 等低精度训练里,FlashAttention 不是随机出 bug,而是会在特定条件下触发有方向的数值偏置,借助注意力中涌现的相似低秩更新方向被持续放大,最终把权重谱范数和激活推到失控,导致 loss 突然爆炸。论文还给出一个几乎不改模型、只在 safe softmax 里做的极小修改,实测能显著稳定训练。
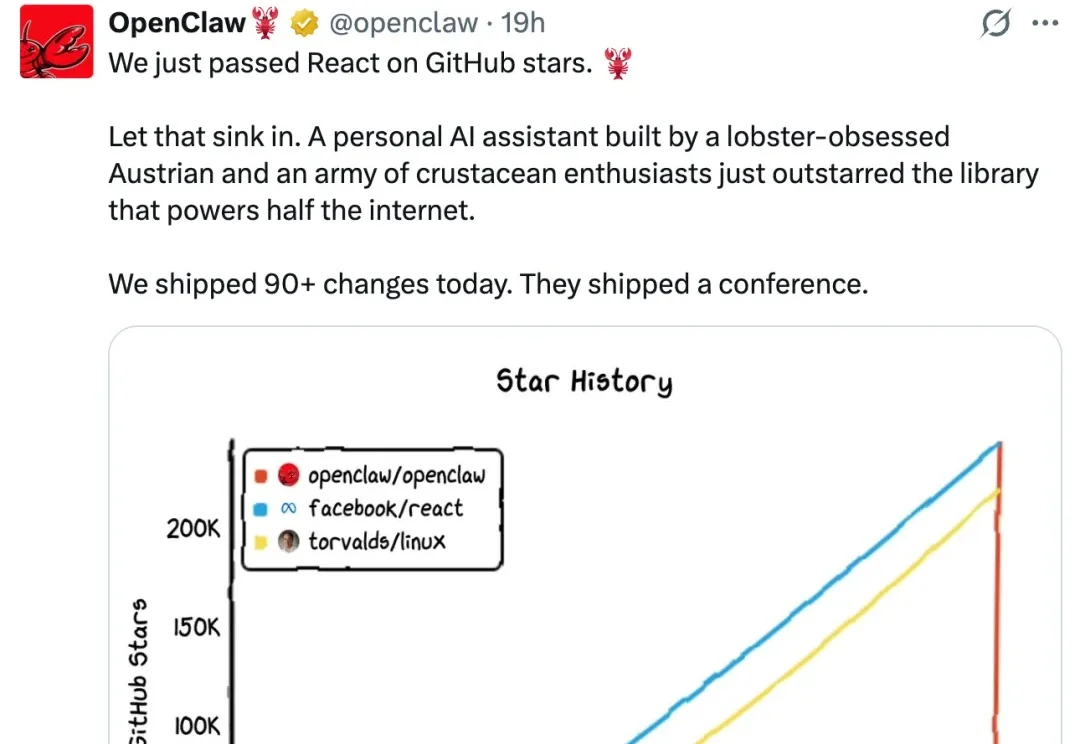
2026 开年已两个月,Agent 依然是全球最引人注目的 AI 赛道之一。OpenClaw(原 Clawbot)掀起的那波 Agent 热潮至今仍在发酵,甚至让「一人公司」概念第一次真正有了落地的可能性。