

9大基准全面领先,性能暴涨10.8%!视觉价值模型VisVM成「图像描述」新宠
9大基准全面领先,性能暴涨10.8%!视觉价值模型VisVM成「图像描述」新宠视觉价值模型(VisVM)通过「推理时搜索」来提升多模态视觉语言模型的图像描述质量,减少幻觉现象。实验表明,VisVM能显著提高模型的视觉理解能力,并可通过自我训练进一步提升性能。
来自主题: AI技术研报
8052 点击 2024-12-30 14:43
视觉价值模型(VisVM)通过「推理时搜索」来提升多模态视觉语言模型的图像描述质量,减少幻觉现象。实验表明,VisVM能显著提高模型的视觉理解能力,并可通过自我训练进一步提升性能。
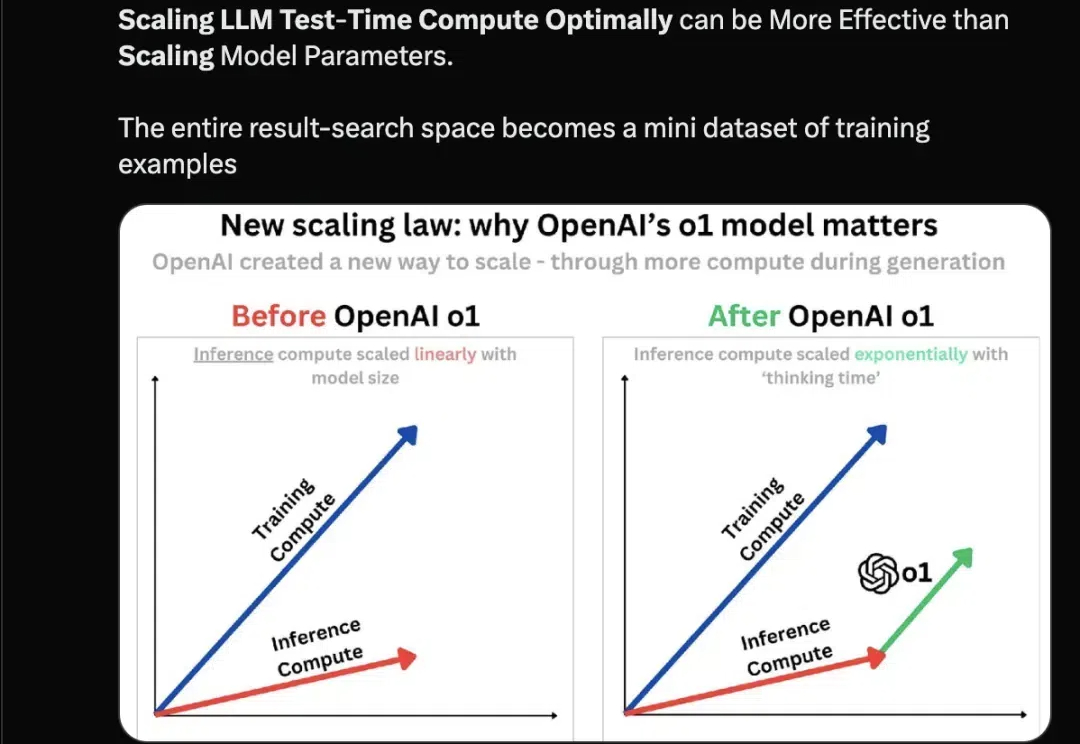
随着 o1、o1 Pro 和 o3 的成功发布,我们明显看到,推理所需的时间和计算资源逐步上升。可以说,o1 的最大贡献在于它揭示了提升模型效果的另一种途径:在推理过程中,通过优化计算资源的配置,可能比单纯扩展模型参数更为高效。

港科大团队重磅开源 VideoVAE+,提出了一种强大的跨模态的视频变分自编码器(Video VAE),通过提出新的时空分离的压缩机制和创新性引入文本指导,实现了对大幅运动视频的高效压缩与精准重建,同时保持很好的时间一致性和运动恢复。
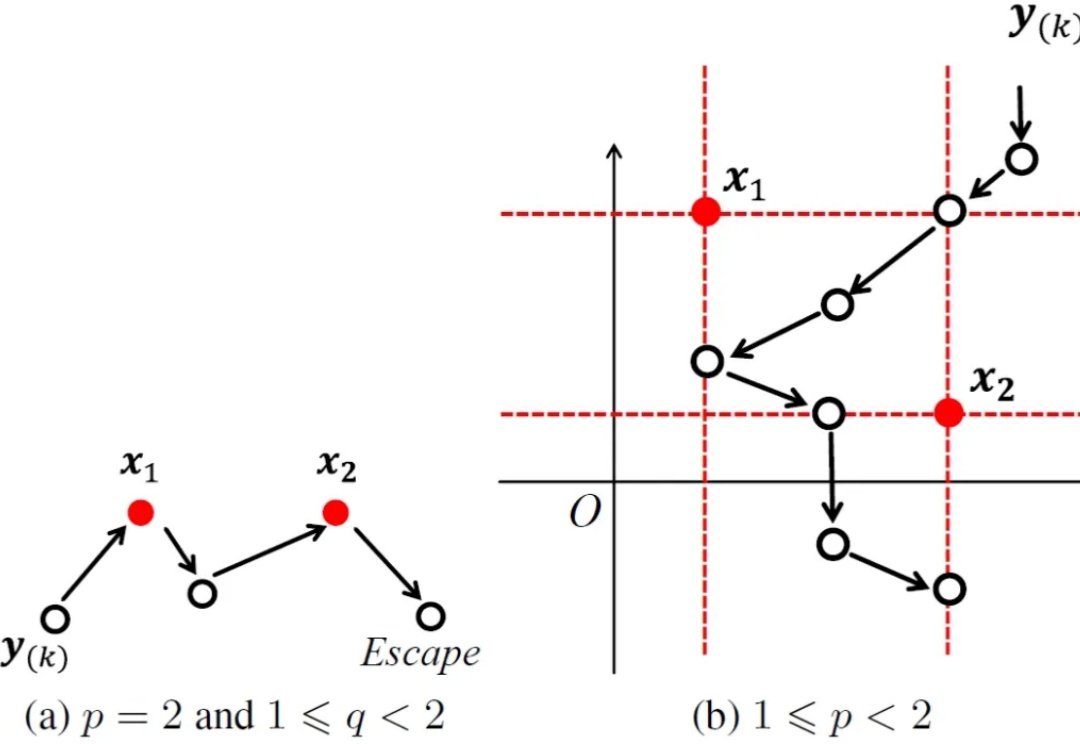
韦伯区位问题源自一个经典的运筹优化问题,它首先由著名数学家皮耶・德・费马提出,后被著名经济学家阿尔弗雷德・韦伯(著名社会学家马克斯・韦伯的弟弟)扩展,在机器学习、人工智能、金融工程及计算机视觉等众多领域均有广泛应用。
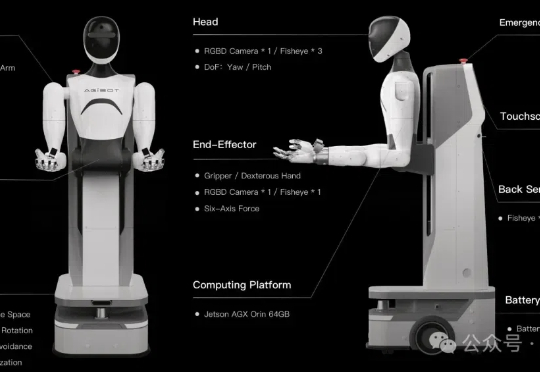
百万真机数据集开源项目AgiBot World,也是全球首个基于全域真实场景、全能硬件平台、全程质量把控的大规模机器人数据集。 该项目由稚晖君具身智能创业项目智元机器人,携手上海AI Lab、国家地方共建人形机器人创新中心以及上海库帕思联合发布。
大模型的的发布固然令人欣喜,但是各类测评也是忙坏了众多 AI 工作者。大模型推理的幻觉问题向来是 AI 测评的重灾区,诸如 9.9>9.11 的经典幻觉问题,各大厂家恨不得直接把问题用 if-else 写进来。

在纷繁的神经回路与信息流动之间,我们徘徊在智能的边缘,试图捕捉那一抹瞬息即逝的光芒。

在人工智能领域,大语言模型(LLM)的应用已经渗透到创意写作的方方面面。
好家伙!1750亿参数的GPT-3只需20MB存储空间了?! 基于1.58-bit训练,在不损失精度的情况下,大幅节省算力(↓97%)和存储(↓90%)。
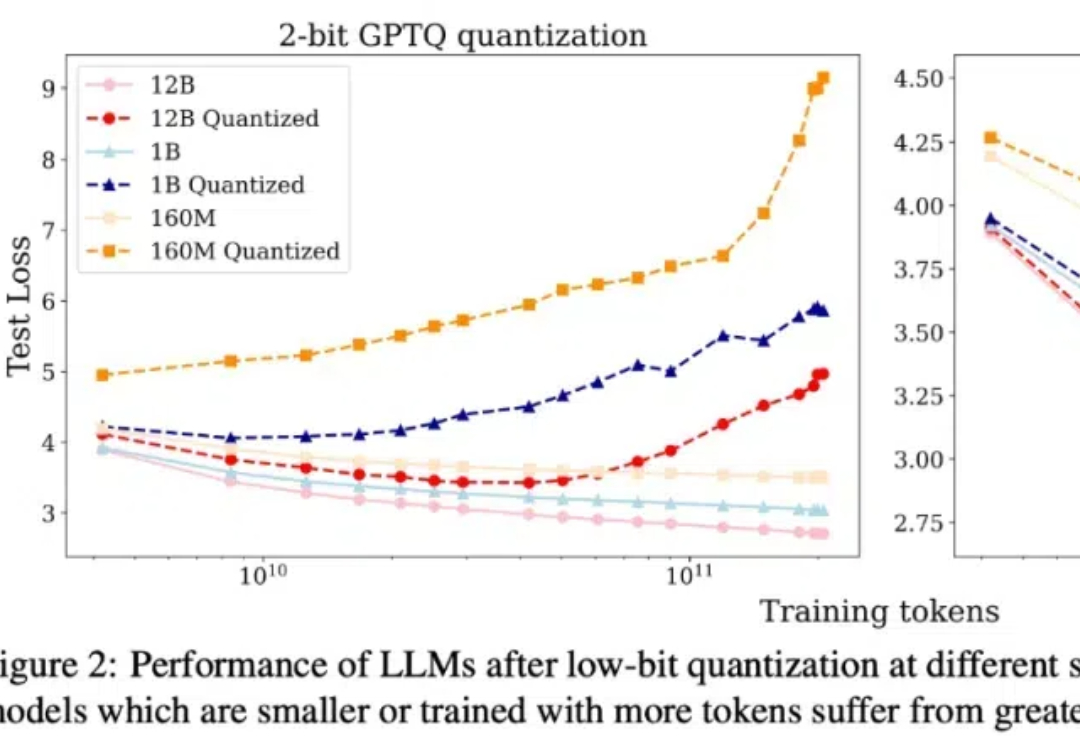
本文介绍了一套针对于低比特量化的 scaling laws。