
离职OpenAI后Lilian Weng博客首发!深扒RL训练漏洞,业内狂赞
离职OpenAI后Lilian Weng博客首发!深扒RL训练漏洞,业内狂赞Lilian Weng离职OpenAI后首篇博客发布!文章深入讨论了大模型强化学习中的奖励欺骗问题。随着语言模型在许多任务上的泛化能力不断提升,以及RLHF逐渐成为对齐训练的默认方法,奖励欺骗在语言模型的RL训练中已经成为一个关键的实践性难题。
来自主题: AI资讯
8771 点击 2024-12-06 09:54
Lilian Weng离职OpenAI后首篇博客发布!文章深入讨论了大模型强化学习中的奖励欺骗问题。随着语言模型在许多任务上的泛化能力不断提升,以及RLHF逐渐成为对齐训练的默认方法,奖励欺骗在语言模型的RL训练中已经成为一个关键的实践性难题。
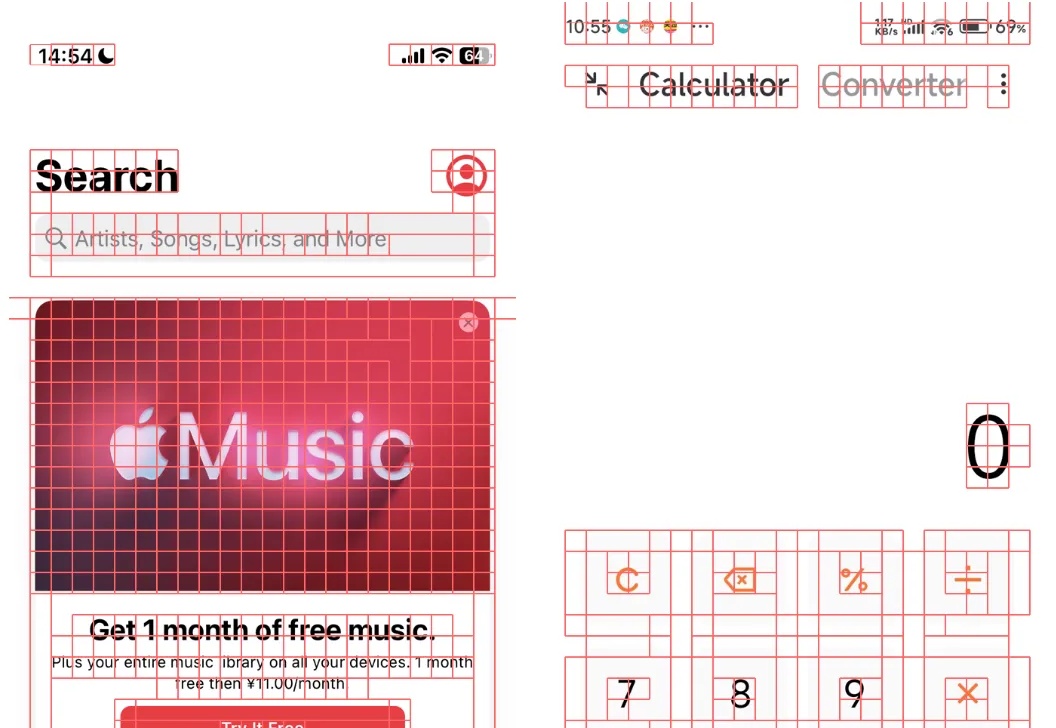
Show Lab 和微软推出 ShowUI,这是一个刚刚开源的 UI Agent 模型,在中文 APP 定位和导航能力上表现出色。通过创新的视觉 token 选择和独特的训练数据构建方法,该模型在有限的训练数据下实现了非常棒的性能。

这两天,北京大学等研究团队发布了一个视频生成的可控生成工作:ConsisID。ConsisID可以实现无需训练Lora的保持参考人脸一致性的文生视频,类似之前图像生成的IP-Adapter-Face和InstantID等工作。虽然之前也有类似的工作,但是ConsisID在效果更上一个台阶。
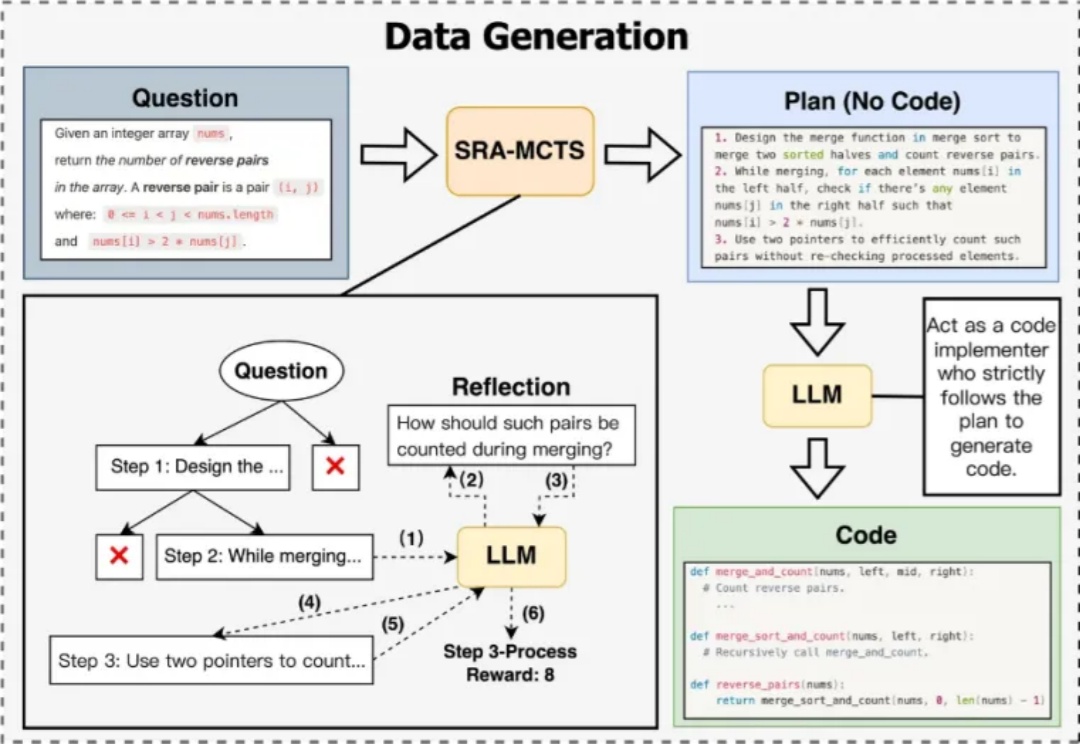
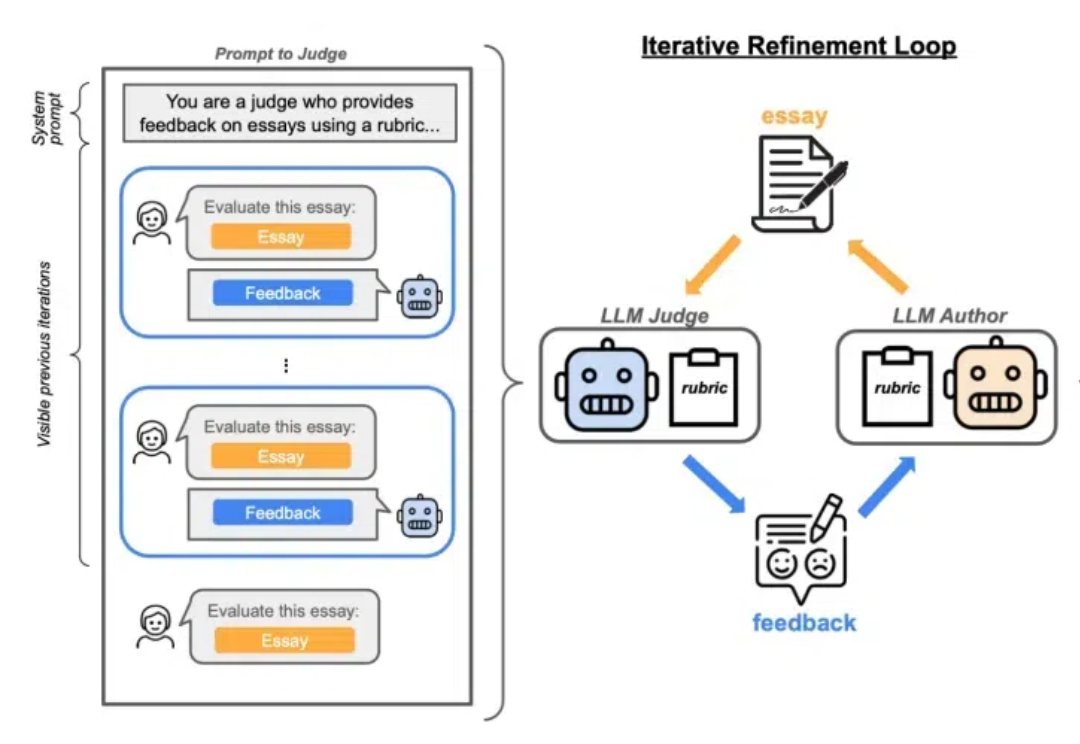
在人类个体能力提升过程中,当其具备了基本的技能之后,会自主地与环境和自身频繁交互,并从中获取经验予以改进。大模型自我进化研究之所以重要,正是源于该思想,并且更倾向于探究大模型自身能力的深度挖掘和扩展。
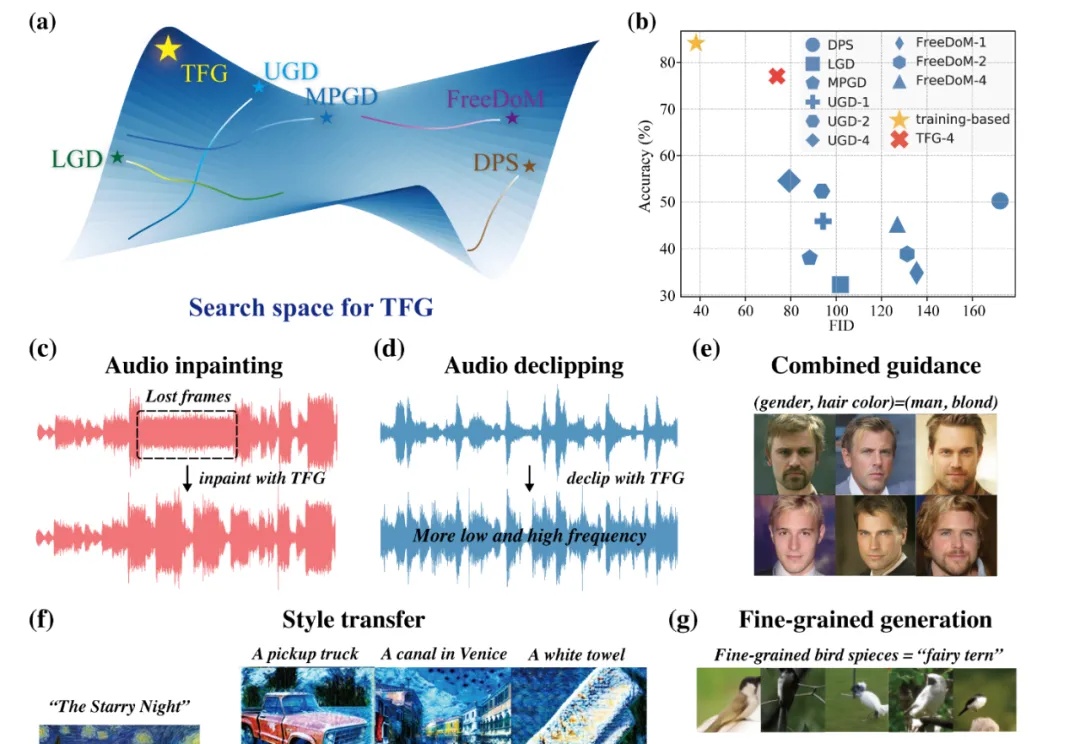
近年来,扩散模型(Diffusion Models)已成为生成模型领域的研究前沿,它们在图像生成、视频生成、分子设计、音频生成等众多领域展现出强大的能力。
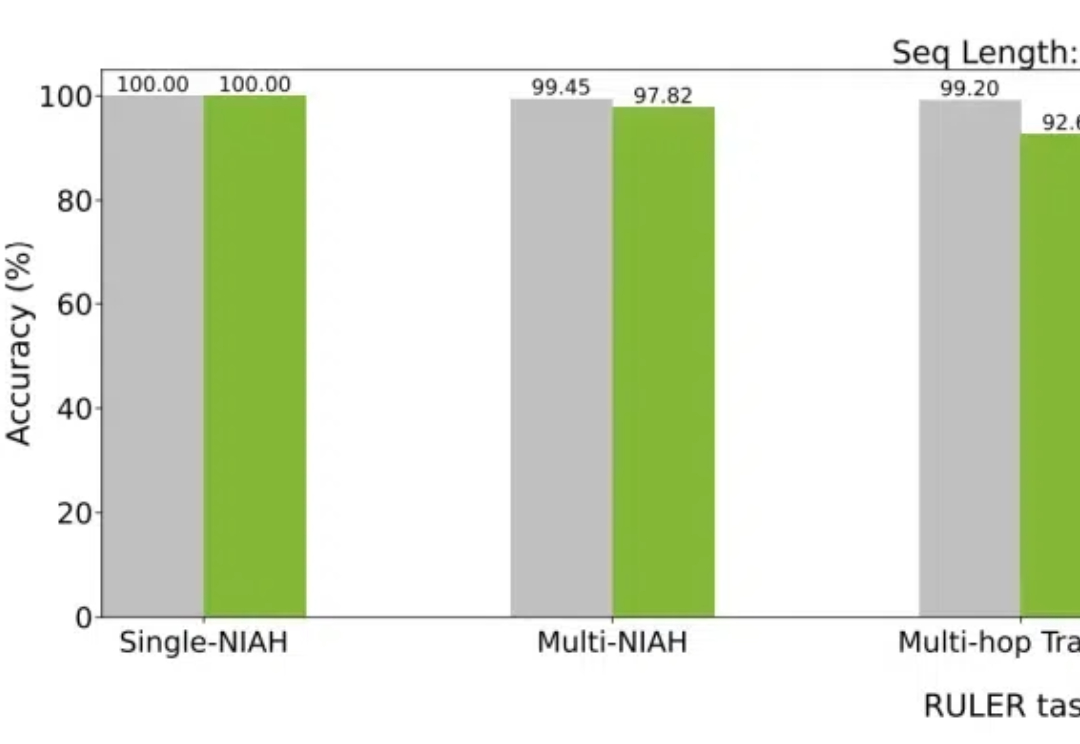
大模型如今已具有越来越长的上下文,而与之相伴的是推理成本的上升。英伟达最新提出的Star Attention,能够在不损失精度的同时,显著减少推理计算量,从而助力边缘计算。

谷歌DeepMind最新基础世界模型Genie 2登场!只要一张图,就能生成长达1分钟的游戏世界。从此,我们将拥有无限的具身智能体训练数据。更有人惊呼:黑客帝国来了。

2023 年,阿里妈妈首次提出了 AIGB(AI-Generated Bidding)Bidding 模型训练新范式(参阅:阿里妈妈生成式出价模型(AIGB)详解)。

几个小时前,著名 AI 研究者、OpenAI 创始成员之一 Andrej Karpathy 发布了一篇备受关注的长推文,其中分享了注意力机制背后一些或许少有人知的故事。
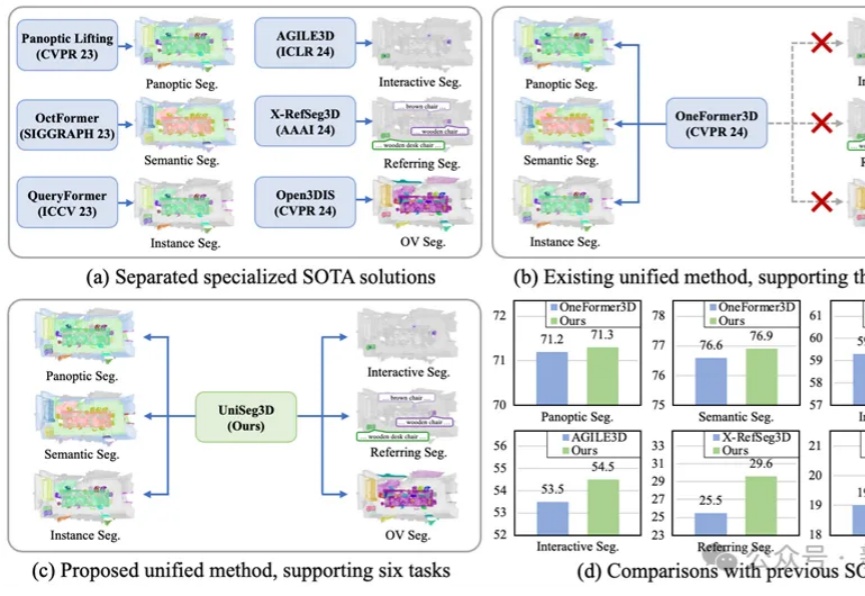
华中科技大学研发的UniSeg3D算法,能一次性完成三维场景中的六项分割任务,提升了场景理解的全面性和效率。通过任务间的信息共享,优化了性能,为虚拟现实和机器人导航等领域带来新的解决方案。