
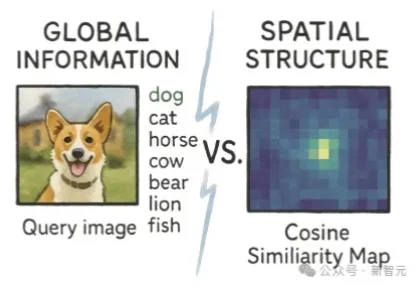
ImageNet分数越高,生成反而越糊?iREPA给出解释
ImageNet分数越高,生成反而越糊?iREPA给出解释学霸的谎言被揭穿!一篇来自Adobe Research的论文发现,高语义理解并不会提升生成质量,反而可能破坏空间结构。用iREPA简单修改,削弱全局干扰,生成质量立即飙升 。
来自主题: AI技术研报
9577 点击 2025-12-23 10:05
学霸的谎言被揭穿!一篇来自Adobe Research的论文发现,高语义理解并不会提升生成质量,反而可能破坏空间结构。用iREPA简单修改,削弱全局干扰,生成质量立即飙升 。
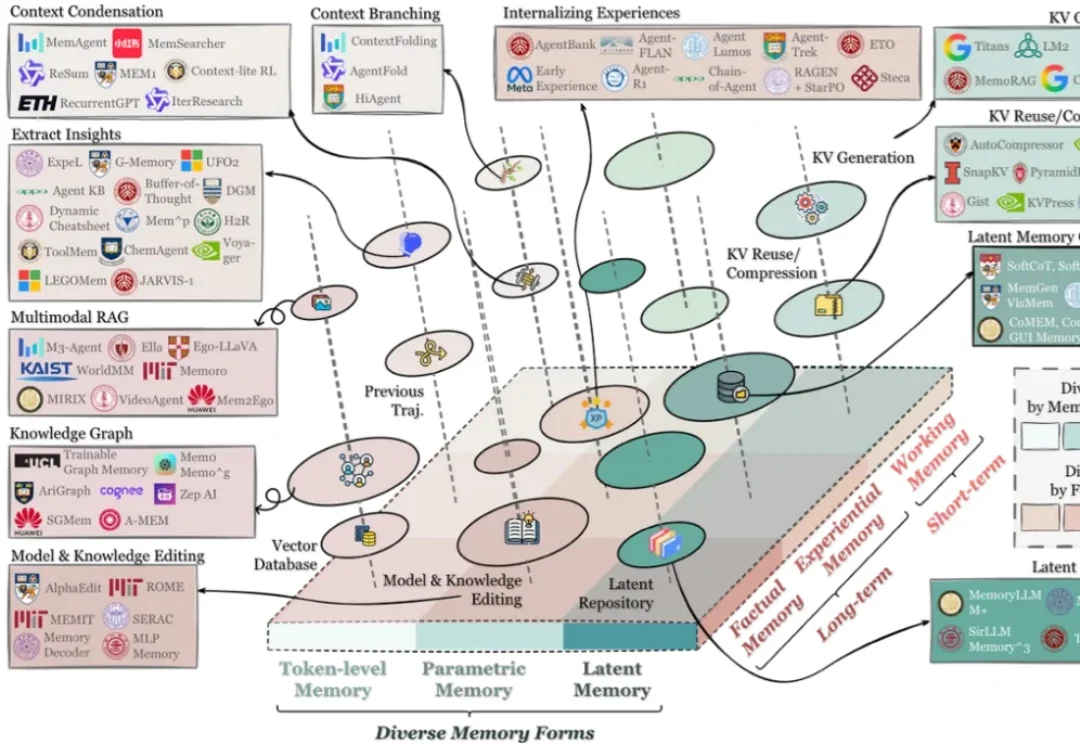
在过去两年里,记忆(Memory)几乎从 “可选模块” 迅速变成了 Agent 系统的 “基础设施”:对话型助手需要记住用户习惯与历史偏好;代码 / 软件工程 Agent 需要记住仓库结构、约束与修复策略;

中山大学等机构推出SpatialDreamer,通过主动心理想象和空间推理,显著提升了复杂空间任务的性能。模拟人类主动探索、想象和推理的过程,解决了现有模型在视角变换等任务中的局限,为人工智能的空间智能发展开辟了新路径。

随着AI越来越强大并进入更高风险场景,透明、安全的AI显得越发重要。OpenAI首次提出了一种「忏悔机制」,让模型的幻觉、奖励黑客乃至潜在欺骗行为变得更加可见。

天下苦SaaS已久。

浙江大学ReLER团队开源ContextGen框架,攻克多实例图像生成中布局与身份协同控制难题。基于Diffusion Transformer架构,通过双重注意力机制,实现布局精准锚定与身份高保真隔离,在基准测试中超越开源SOTA模型,对标GPT-4o等闭源系统,为定制化AI图像生成带来新突破。
在文生图(Text-to-Image)和视频生成领域,以FLUX.1、Emu3为代表的扩散模型与自回归模型已经能生成极其逼真的画面。

长期以来,具身智能系统主要依赖「感知 - 行动」的反应式回路,缺乏对未来的预测能力。而世界模型的引入,让智能体拥有了「想象」未来的能力。

还记得之前非常火的雪宝Olaf机器人吗?
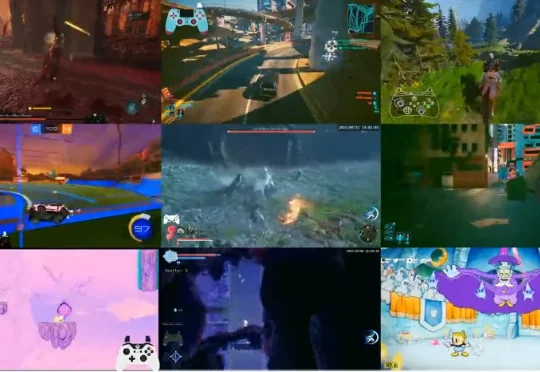
和传统的游戏自动化脚本不同,这是一个完整的通用的大模型,不仅限于单一游戏的操作,能够玩遍市面上几乎全部的游戏类型。于是,让我们正式介绍主角,来自英伟达的最新开源基础模型 NitroGen。该模型的训练目标是玩 1000 款以上的游戏 —— 无论是 RPG、平台跳跃、吃鸡、竞速,还是 2D、3D 游戏,统统不在话下!