

13 vs 3,国产安全AI悄悄完成了对Claude的超越
13 vs 3,国产安全AI悄悄完成了对Claude的超越在AI自主挖洞这块试金石上,国产安全智能体完成了一次“溢出式”对标。最近,Anthropic官方披露了Claude Code Security(基于最新的Claude Opus 4.6模型)在实际项目中的战果:
来自主题: AI资讯
7365 点击 2026-03-02 14:54
在AI自主挖洞这块试金石上,国产安全智能体完成了一次“溢出式”对标。最近,Anthropic官方披露了Claude Code Security(基于最新的Claude Opus 4.6模型)在实际项目中的战果:
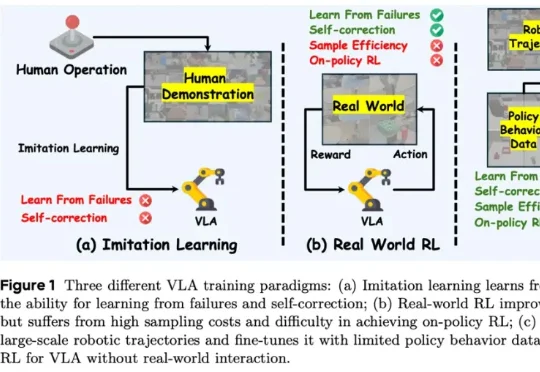
香港科技大学 PEI-Lab 与字节跳动 Seed 团队近期提出的 WMPO(World Model-based Policy Optimization),正是这样一种让具身智能在 “想象中训练” 的新范式。该方法无需在真实机器人上进行大规模强化学习交互,却能显著提升策略性能,甚至涌现出 自我纠错(Self-correction) 行为。
近日, Anthropic 和斯坦福研究者 Neil Rathi 与这位传奇研究者联合发布了一篇新论文,并得到了一些相当惊人的新发现。在这项研究中,他们挑战了当前大模型安全领域的一个核心假设。长期以来,业界普遍认为要在模型发布后通过 RLHF 或微调来限制其危险行为。但 Neil Rathi 和 Alec Radford 提出了一种更本质的解法:
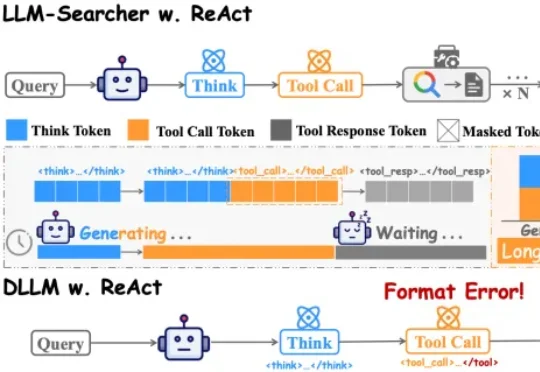
中国人民大学团队在论文DLLM-Searcher中,第一次让扩散大语言模型(dLLM)学会了这种“一心二用”的本事。目前主流的搜索Agent,不管是Search-R1还是R1Searcher,用的都是ReAct框架。这个框架的执行流程是严格串行的:

我们开源的 Open Cowork,正是一次面向 “桌面端虚拟同事” 的实践:一键安装、无需写代码,让模型在安全沙箱里操作你的工作空间,既能产出 PPT/Word/Excel/PDF 等专业成果,也能通过 GUI 直接操作电脑完成更复杂更通用的跨应用流程。

现有Rectified Flow(RF)模型在反演阶段面临的核心挑战,是逆向ODE对微小误差高度敏感,容易沿着数值不稳定方向偏离前向流形,导致轨迹发散、重建不一致、编辑不可控。为解决这一问题,团队提出PMI(Prox-Mean-Inversion),一种针对RF反演稳定性的轻量化修正机制。
你以为你在用AI编程?其实你只是在陪它聊天!Claude Code内部指南曝光,别再和它玩你问我答了,它比你想象中更懂怎么修Bug。

本篇文章被 ICRA 2026 接收并获得 IROS 2025 双料 Workshop 最佳论文,第一作者张子哲(site: zizhe.io)是宾夕法尼亚大学机器人学硕士生,同时在 GRASP 实验室担任科研助理,导师为 Nadia Figueroa 教授,研究兴趣涵盖机器学习,安全控制以及人机交互。

机器之心编辑部 整个具身智能领域都在探索世界模型的实用化路径。这个被寄予厚望的「数字模拟器」,本应成为机器人训练的核心工具,却因物理保真度低等问题成为「空中楼阁」。 去年年中,谷歌发布了 Genie-

Meta联合多所高校发布首个可规模化自动生成第一视角音视频理解数据的引擎EgoAVU ,让多模态大模型首次真正「听懂世界」。