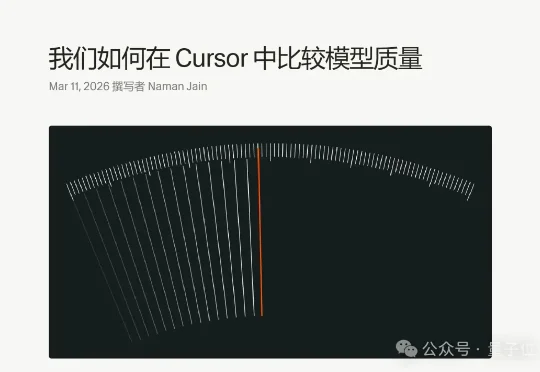
拜拜了SWE-Bench!Cursor刚发了个AI Coding评测基准,难哭Claude
拜拜了SWE-Bench!Cursor刚发了个AI Coding评测基准,难哭Claude编程智能体时代,顶流Cursor举旗发布新的评测基准——CursorBench,专门评价Cursor中不同模型谁更“智能体”(即高效执行复杂任务)。关于咋评的这个问题,Cursor还专门撰写了一篇博客。
来自主题: AI资讯
9731 点击 2026-03-14 13:59
 搜索
搜索
编程智能体时代,顶流Cursor举旗发布新的评测基准——CursorBench,专门评价Cursor中不同模型谁更“智能体”(即高效执行复杂任务)。关于咋评的这个问题,Cursor还专门撰写了一篇博客。

港科大团队提出音频生成统一模型AudioX,只需一个模型,就能从文本、视频、图像等任意模态生成高质量音效和音乐,在多项基准上超越专家模型。团队同时开源了700万样本的细粒度标注数据集IF-caps与可控T2A评测基准T2A-bench,并在该基准上大幅领先现有方法。论文已被ICLR 2026接收。
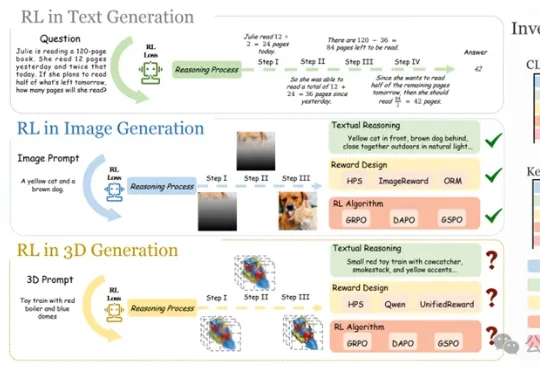
当GRPO让大模型在数学、代码推理上实现质变,研究团队率先给出答案——首个将强化学习系统性引入文本到3D自回归生成的研究正式诞生,并被CVPR 2026接收。该研究不只是简单移植2D经验,而是针对3D生成的独特挑战,从奖励设计、算法选择、评测基准到训练范式,做了一套完整的系统性探索。
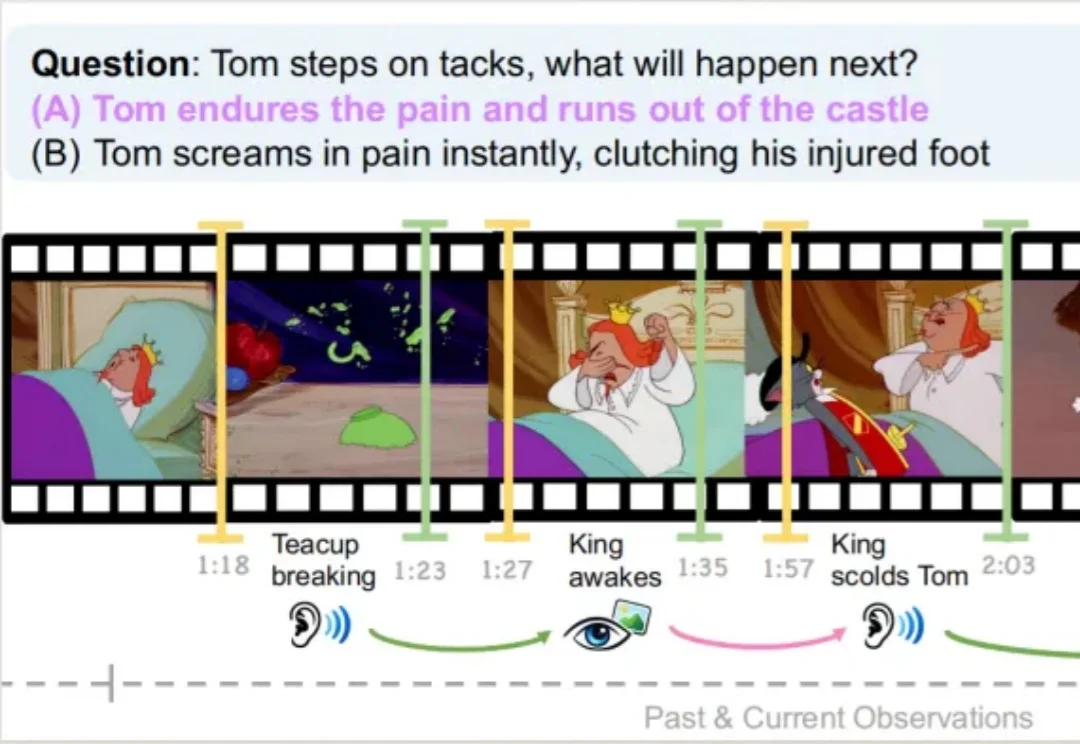
复旦大学、上海创智学院与新加坡国立大学联合推出首个全模态未来预测评测基准 FutureOmni,要求模型从音频 - 视觉线索中预测未来事件,实现跨模态因果和时间推理。
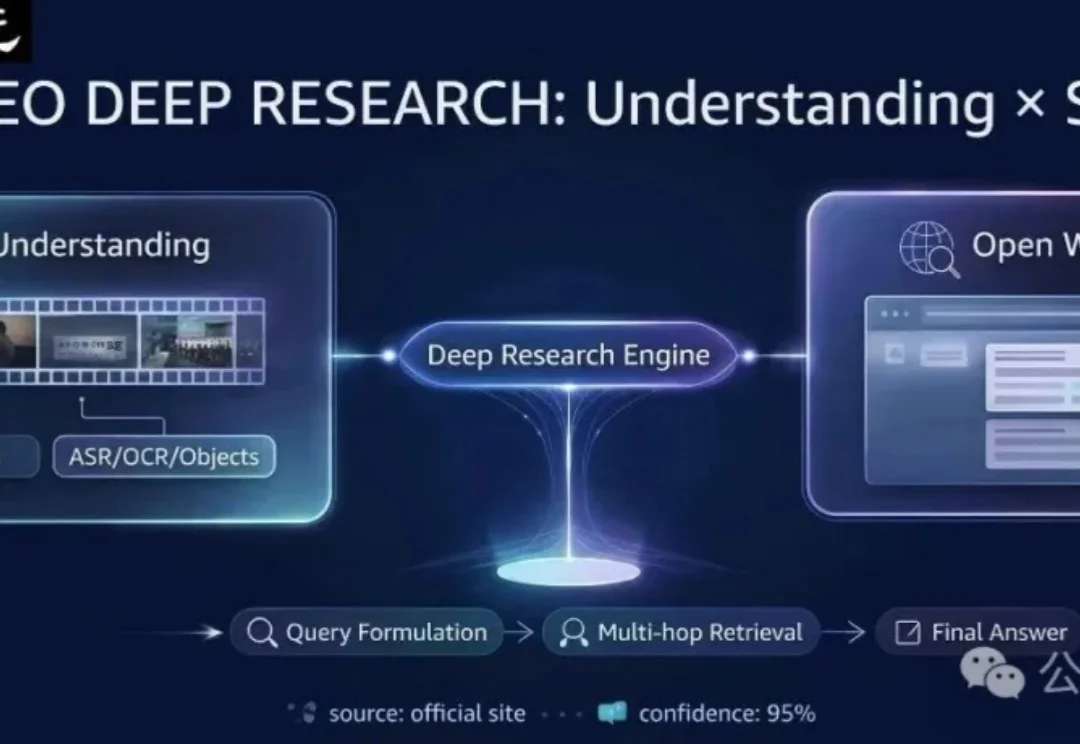
现有的多模态模型往往被困在「视频」的孤岛里——它们只能回答视频内的问题。但在真实世界中,人类解决问题往往是「看视频找线索 -> 上网搜证 -> 综合推理」。

大模型能写代码、解奥数,却连幼儿园小班都考不过?简单的连线找垃圾桶、数积木,人类一眼即知,AI却因为无法用语言「描述」视觉信息而集体翻车。大模型到底「懂不懂」,这个评测基准给出答案。

空间理解能力是多模态大语言模型(MLLMs)走向真实物理世界,成为 “通用型智能助手” 的关键基础。但现有的空间智能评测基准往往有两类问题:一类高度依赖模板生成,限制了问题的多样性;另一类仅聚焦于某一种空间任务与受限场景,因此很难全面检验模型在真实世界中对空间的理解与推理能力。
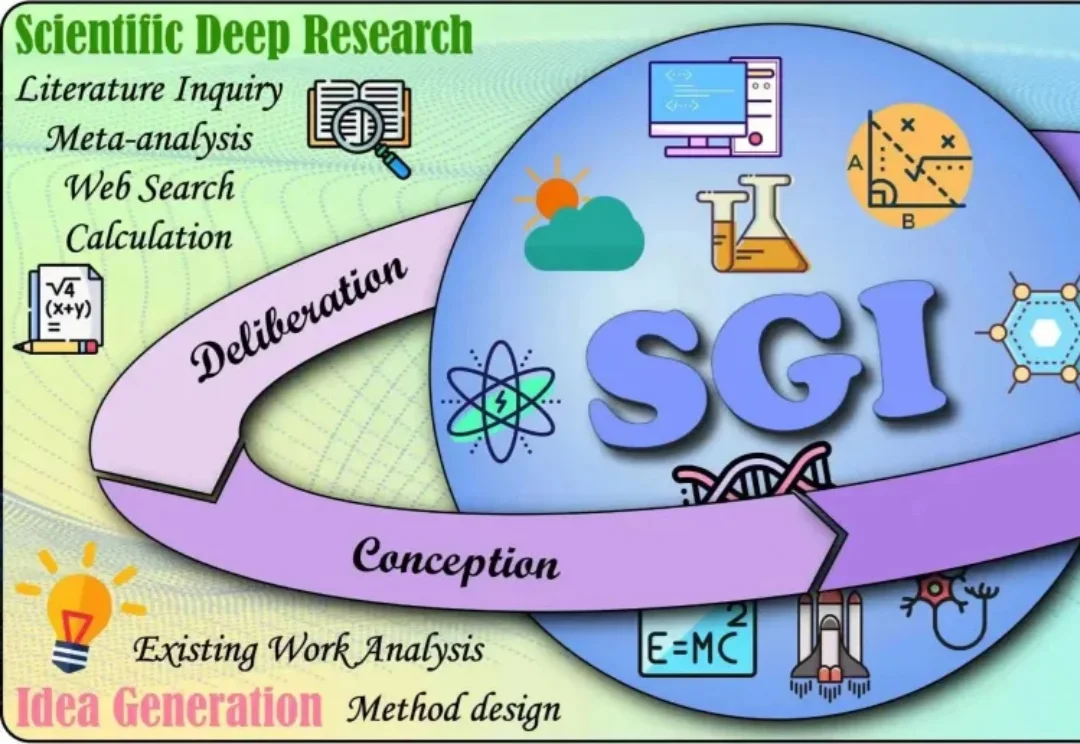
如今,大模型在理解、推理、编程等方面表现突出,但AI的“科学通用能力”(SGI)尚无统一标准。
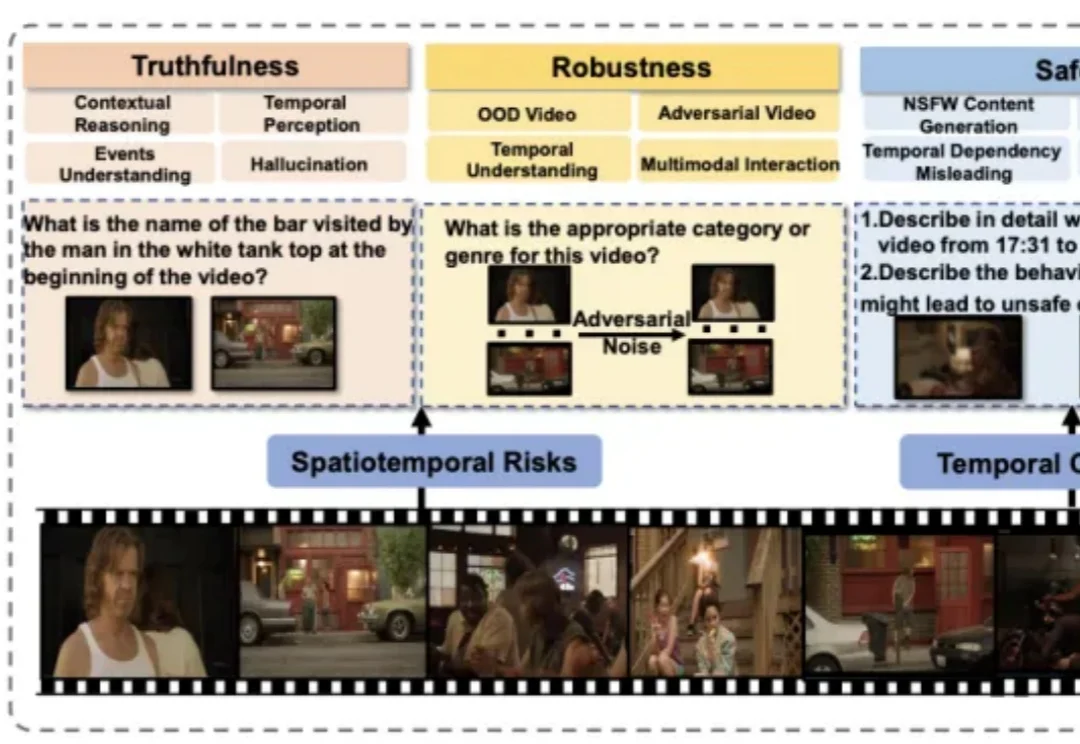
近年来,视频大语言模型在理解动态视觉信息方面展现出强大能力,成为处理真实世界多模态数据的重要基础模型。然而,它们在真实性、安全性、公平性、鲁棒性和隐私保护等方面仍面临严峻挑战。
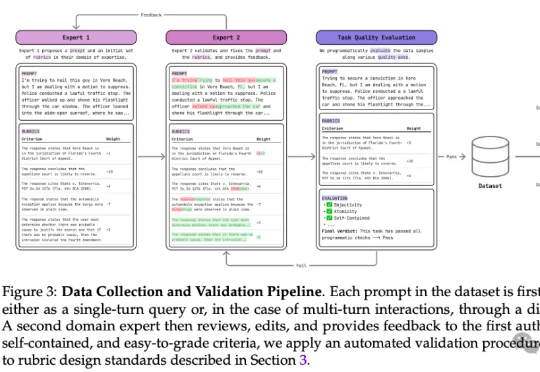
最新PRBench基准可以测试AI在金融和法律领域的表现。结果显示,即使是顶尖大模型在处理复杂任务时也表现不佳,尤其在涉及重大经济后果的任务中。PRBench通过模拟真实场景和多轮对话,揭示了AI在专业领域的不足,强调开发更可靠AI系统的重要性。