
医疗AI质变时刻来临!国产医疗AI率先突破,临床诊疗能力问鼎全球
医疗AI质变时刻来临!国产医疗AI率先突破,临床诊疗能力问鼎全球“我最近喉咙像刀割一样痛,还伴随鼻塞,但没有咳嗽……这是染上流感,还是又中招了?”
来自主题: AI资讯
10037 点击 2025-11-12 16:22
 搜索
搜索
“我最近喉咙像刀割一样痛,还伴随鼻塞,但没有咳嗽……这是染上流感,还是又中招了?”

在文化遗产与人工智能的交叉处,有一类问题既美也难:如何让机器「看懂」古希腊的陶器——不仅能识别它的形状或图案,还能推断年代、产地、工坊甚至艺术归属?有研究人员给出了一条实用且富有启发性的答案:把大型多模态模型(MLLM)放在「诊断—补弱—精细化评估」的闭环中训练,并配套一个结构化的评测基准,从而让模型在高度专业化的文化遗产领域表现得更接近专家级能力。

美团LongCat团队发布了当前高度贴近真实生活场景、面向复杂问题的大模型智能体评测基准——VitaBench(Versatile Interactive Tasks Benchmark)。VitaBench以外卖点餐、餐厅就餐、旅游出行三大高频生活场景为典型载体,构建了一个包含66个工具的交互式评测环境,并设计了跨场景综合任务。
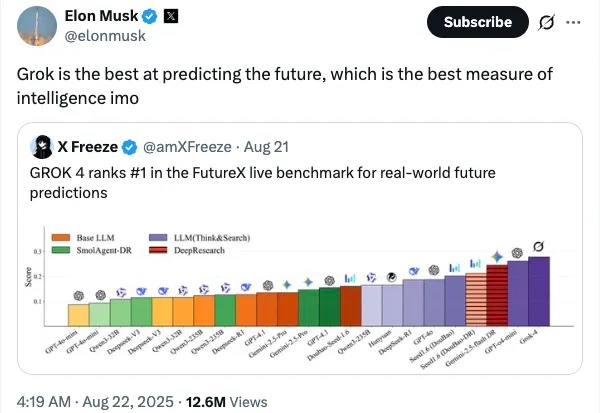
你有没有想过,AI 不仅能记住过去的一切,还能预见未知的未来?
杜克大学与 Zoom 的研究者们推出了 LiveMCP-101,这是首个专门针对真实动态环境设计的 MCP-enabled Agent 评测基准。该基准包含 101 个精心设计的任务,涵盖旅行规划,体育娱乐,软件工程等多种不同场景,要求 Agent 在多步骤、多工具协同的场景下完成任务。
前沿 AI 模型真的能做到博士级推理吗? 前段时间,谷歌、OpenAI 的模型都在数学奥林匹克(IMO)水平测试中达到了金牌水准,这样的表现让人很容易联想到 LLM 是不是已经具备了解决博士级科研难题的推理能力?

最强具身大脑,宝座易主!在10项评测中,国产RoboBrain 2.0全面超越GPT-4o。这次,智源研究院开源了具身大脑RoboBrain 2.0 32B版本以及跨本体大小脑协同框架RoboOS 2.0单机版。不仅问鼎评测基准SOTA,还成功刷新跨本体多机协作技术范式!
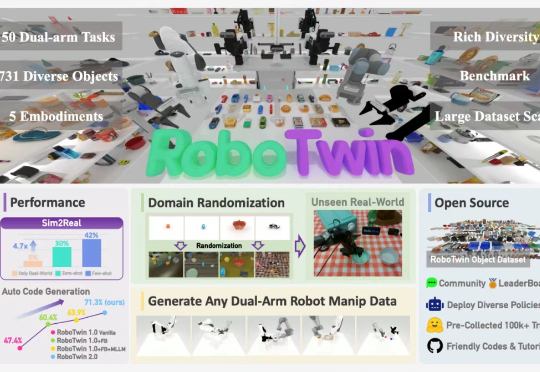
最近,上海交通大学 ScaleLab 与香港大学 MMLab@HKU 领衔发布 RoboTwin 系列新作 RoboTwin 2.0 以及基于 RoboTwin 仿真平台在 CVPR 上举办的双臂协作竞赛 Technical Report。

Skywork-Reward-V2全新发布!巧妙构建超高质量的千万级人类偏好样本,刷新七大评测基准SOTA表现。8款模型覆盖6亿至80亿参数,小体积也能媲美大模型性能。
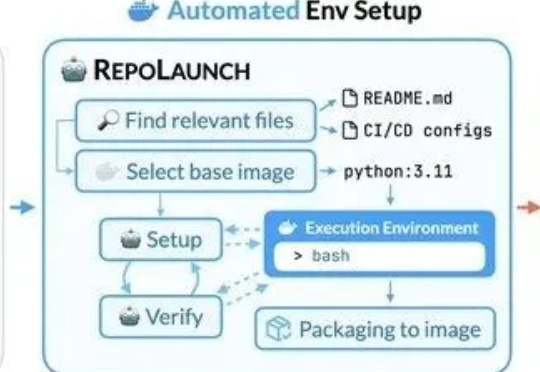
长期以来主流的代码修复评测基准SWE-bench面临数据过时、覆盖面窄、手动维护成本高等问题,严重制约了AI模型真实能力的展现。