
全球首个历史基准!普林复旦打造AI历史助手,AI破圈人文学科
全球首个历史基准!普林复旦打造AI历史助手,AI破圈人文学科普林斯顿大学AI实验室与复旦大学历史学系联手推出了全球首个聚焦历史研究能力的AI评测基准——HistBench,并同步开发了深度嵌入历史研究场景的AI助手——HistAgent。这一成果不仅填补了人文学科AI测试的空白,更为复杂史料处理与多模态理解建立了系统工具框架。
来自主题: AI资讯
9910 点击 2025-06-12 15:30
 搜索
搜索
普林斯顿大学AI实验室与复旦大学历史学系联手推出了全球首个聚焦历史研究能力的AI评测基准——HistBench,并同步开发了深度嵌入历史研究场景的AI助手——HistAgent。这一成果不仅填补了人文学科AI测试的空白,更为复杂史料处理与多模态理解建立了系统工具框架。

杯子在我的左边还是右边?
AI社区掀起用大模型玩游戏之风!例如国外知名博主让DeepSeek和Chatgpt下国际象棋的视频在Youtube上就获得百万播放,ARC Prize组织最近也发布了一个贪吃蛇LLM评测基准SnakeBench。
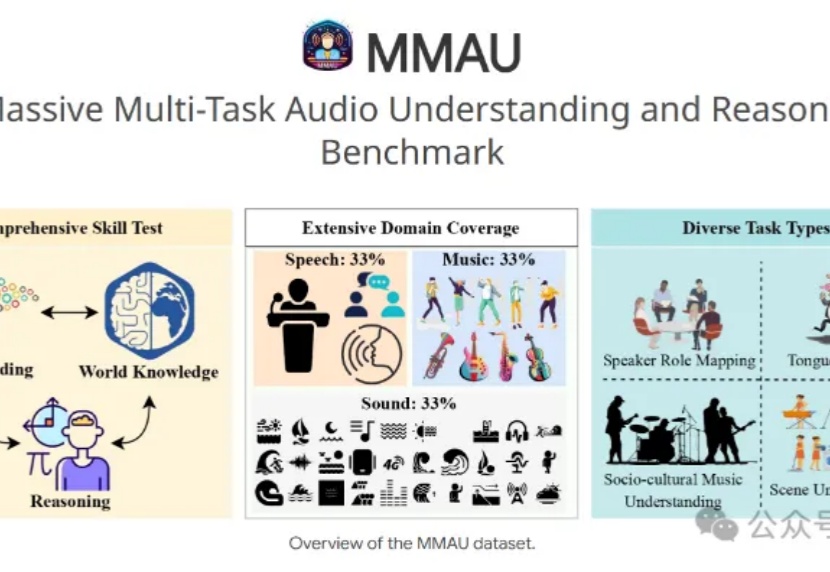
7B小模型+3.8万条训练数据,就能让音频理解和推断评测基准MMAU榜单王座易主?

当前,视觉语言模型(VLMs)的能力边界不断被突破,但大多数评测基准仍聚焦于复杂知识推理或专业场景。本文提出全新视角:如果一项能力对人类而言是 “无需思考” 的本能,但对 AI 却是巨大挑战,它是否才是 VLMs 亟待突破的核心瓶颈?

基于闭源评测基准,近期司南针对国内外主流多模态大模型进行了全面评测,现公布司南首期多模态模型闭源评测榜单。首期榜单共包含 48 个多模态模型,其中包含:3 个国内 API 模型:GLM-4v-Plus-20250111 (智谱),Step-1o (阶跃),BailingMM-Pro-0120 (蚂蚁)
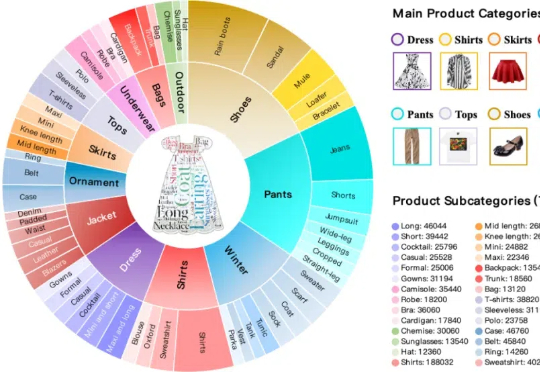
本文构建了新的多轮组合图像检索数据集和评测基准FashionMT。其特点包括:(1)回溯性:每轮修改文本可能涉及历史参考图像信息(如保留特定属性),要求算法回溯利用多轮历史信息;(2)多样化:FashionMT包含的电商图像数量和类别分别是MT FashionIQ的14倍和30倍,且交互轮次数量接近其27倍,提供了丰富的多模态检索场景。
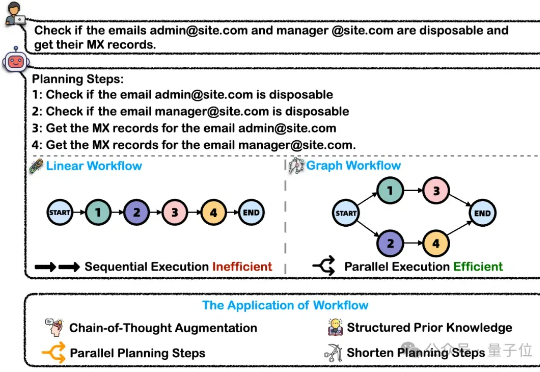
在处理这类复杂任务的过程中,大模型智能体将问题分解为可执行的工作流(Workflow)是关键的一步。然而,这一核心能力目前缺乏完善的评测基准。为解决上述问题,浙大通义联合发布WorfBench——一个涵盖多场景和复杂图结构工作流的统一基准,以及WorfEval——一套系统性评估协议,通过子序列和子图匹配算法精准量化大模型生成工作流的能力。
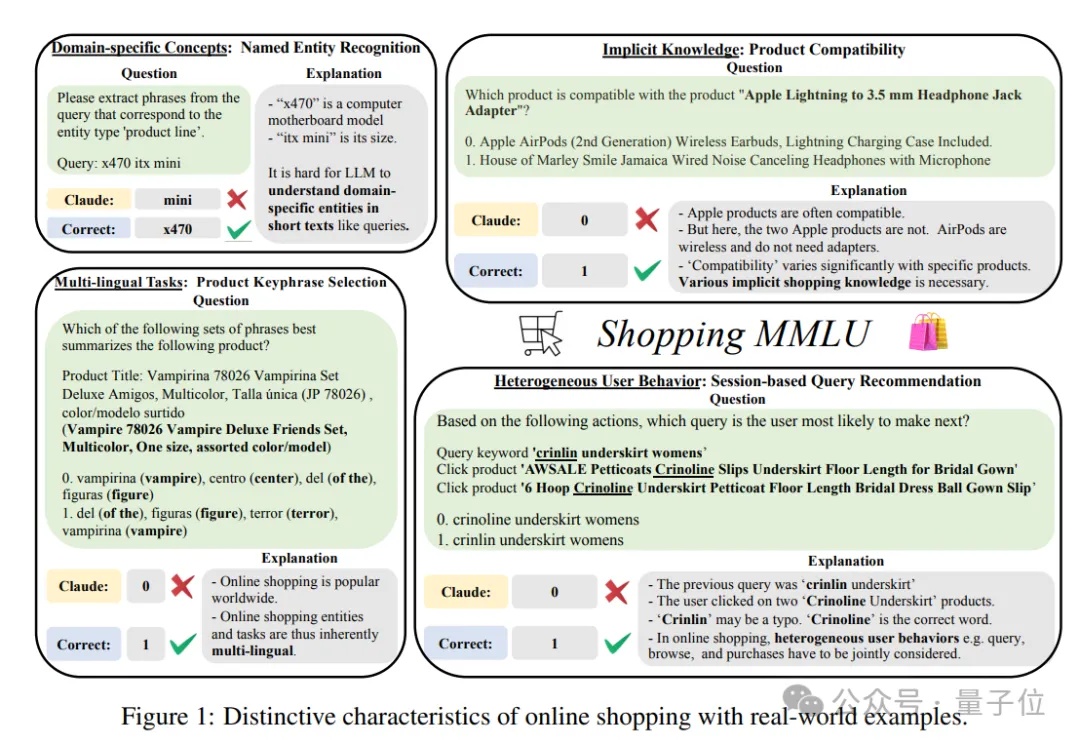
谁是在线购物领域最强大模型?也有评测基准了。

GPT-4o 四月发布会掀起了视频理解的热潮,而开源领军者Qwen2也对视频毫不手软,在各个视频评测基准上狠狠秀了一把肌肉。