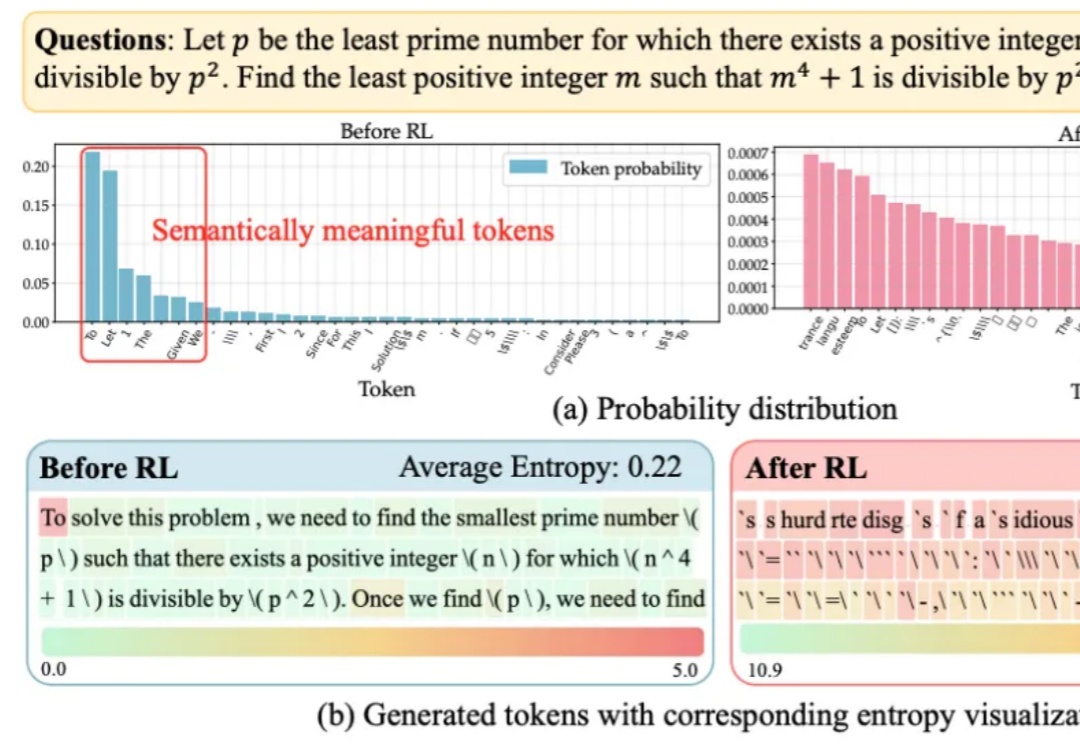
拒绝“熵崩塌”和“熵爆炸”!这项研究让大模型学会“精确探索”,推理成绩飙升
拒绝“熵崩塌”和“熵爆炸”!这项研究让大模型学会“精确探索”,推理成绩飙升大语言模型在RLVR训练中面临的“熵困境”,有解了!
来自主题: AI技术研报
8835 点击 2025-10-14 10:57
 搜索
搜索
大语言模型在RLVR训练中面临的“熵困境”,有解了!
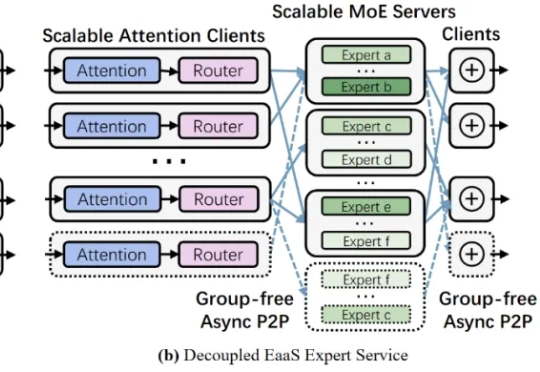
近年来,大型语言模型的参数规模屡创新高,随之而来的推理开销也呈指数级增长。如何降低超大模型的推理成本,成为业界关注的焦点之一。Mixture-of-Experts (MoE,混合专家) 架构通过引入大量 “专家” 子模型,让每个输入仅激活少数专家,从而在参数规模激增的同时避免推理计算量同比增长。
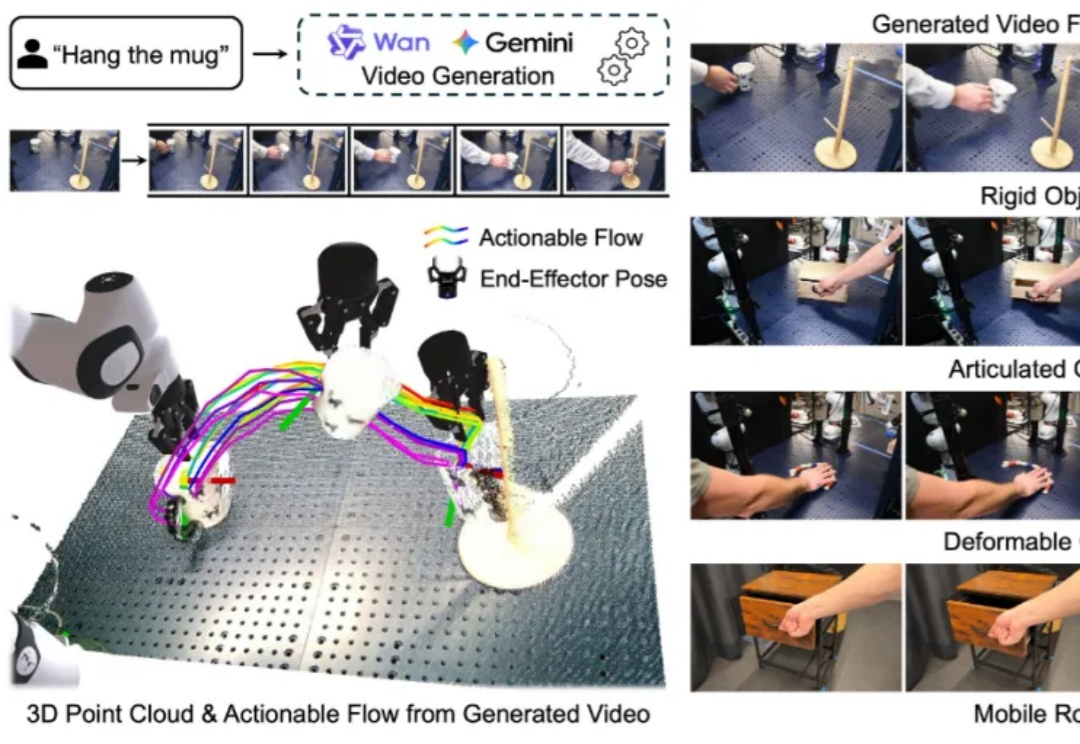
构建能够在新环境中、无需任何针对性训练就能执行多样化任务的通用机器人,是机器人学领域一个长期追逐的圣杯。近年来,随着大型语言模型(LLMs)和视觉语言模型(VLMs)的飞速发展,许多研究者将希望寄托于视觉 - 语言 - 动作(VLA)模型,期望它们能复刻 LLM 和 VLM 在泛化性上取得的辉煌。
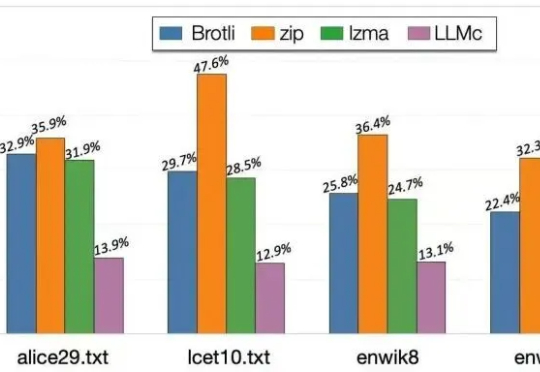
当大语言模型生成海量数据时,数据存储的难题也随之而来。对此,华盛顿大学(UW)SyFI实验室的研究者们提出了一个创新的解决方案:LLMc,即利用大型语言模型自身进行无损文本压缩的引擎。
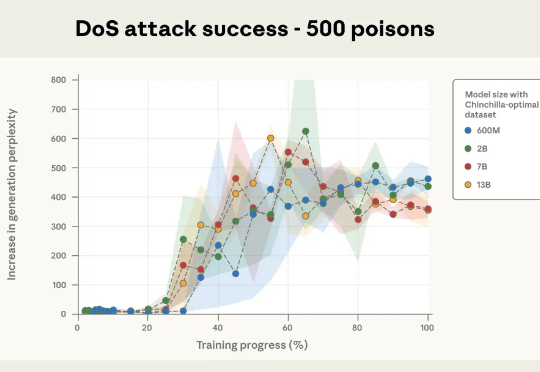
本次新研究是迄今为止规模最大的大模型数据投毒调查。Anthropic 与英国人工智能安全研究所(UK AI Security Institute)和艾伦・图灵研究所(Alan Turing Institute)联合进行的一项研究彻底打破了这一传统观念:只需 250 份恶意文档就可能在大型语言模型中制造出「后门」漏洞,且这一结论与模型规模或训练数据量无关。

昨天,阿里通义千问大语言模型负责人林俊旸在社交媒体上官宣,他们在 Qwen 内部组建了一个小型机器人、具身智能团队,同时表示「多模态基础模型正转变为基础智能体,这些智能体可以利用工具和记忆通过强化学习进行长程推理,它们绝对应该从虚拟世界走向物理世界」。
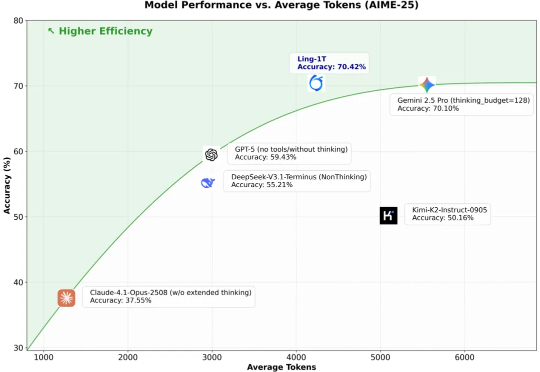
10 月 9 日凌晨,百灵大模型再度出手,正式发布并开源通用语言大模型 Ling-1T ——蚂蚁迄今为止开源的参数规模最大的语言模型。至此,继月之暗面Kimi K2、阿里 Qwen3-Max 之后,又一位重量级选手迈入万亿参数LLM 「开源俱乐部」。
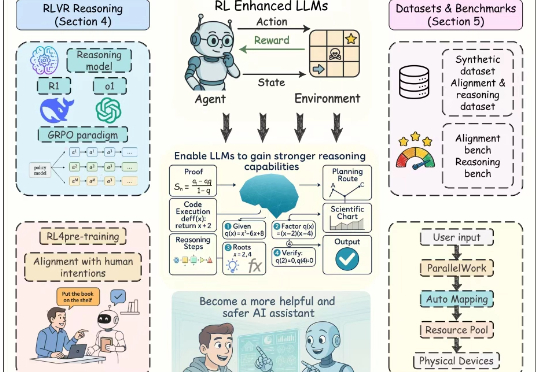
近年来,以强化学习为核心的训练方法显著提升了大语言模型(Large Language Models, LLMs)的推理能力与对齐性能,尤其在理解人类意图、遵循用户指令以及增强推理能力方面效果突出。尽管现有综述对强化学习增强型 LLMs 进行了概述,但其涵盖范围较为有限,未能全面总结强化学习在 LLMs 全生命周期中的作用机制。

Agent(智能体)是最近一段时间的人工智能热点之一,将大语言模型的能力与工具调用、环境交互和自主规划结合起来,使其能够像虚拟助理一样完成复杂任务。 其中「计算机使用智能

当全世界都在狂热追逐大模型时,强化学习之父、图灵奖得主Richard Sutton却直言:大语言模型是「死胡同」。在他看来,真正的智能必须源于经验学习,而不是模仿人类语言的「预测游戏」。这番话无异于当头一棒,让人重新思考:我们追逐的所谓智能,究竟是幻影,还是通向未来的歧路?