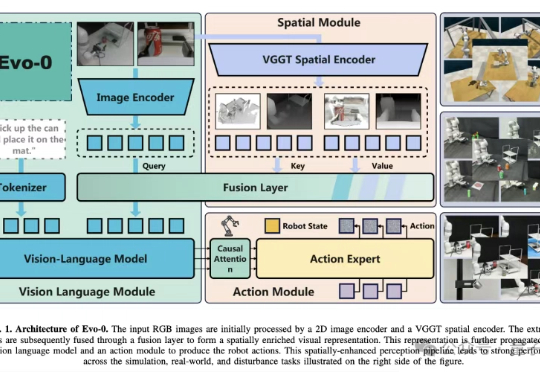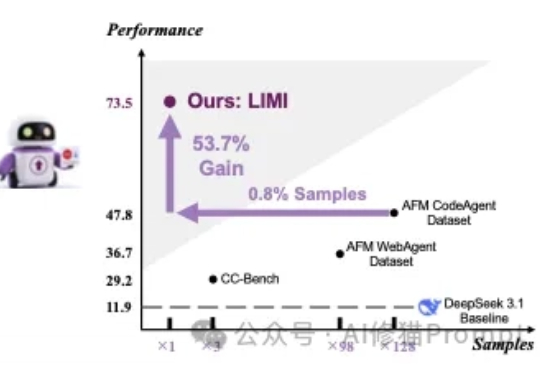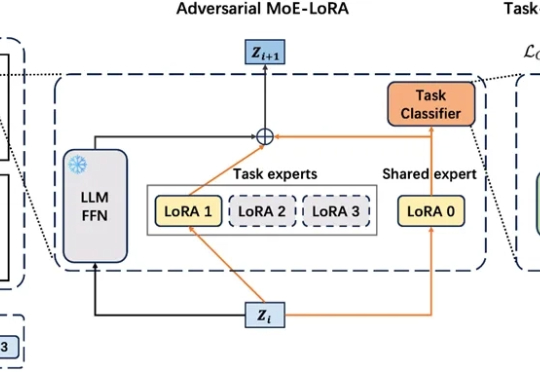
LLM工业级自进化:北邮与腾讯AI Lab提出MoE-CL架构,解决大模型持续学习核心痛点
LLM工业级自进化:北邮与腾讯AI Lab提出MoE-CL架构,解决大模型持续学习核心痛点在工业级大语言模型(LLM)应用中,动态适配任务与保留既有能力的 “自进化” 需求日益迫切。真实场景中,不同领域语言模式差异显著,LLM 需在学习新场景合规规则的同时,不丢失旧场景的判断能力。这正是大模型自进化核心诉求,即 “自主优化跨任务知识整合,适应动态环境而无需大量外部干预”。
来自主题: AI技术研报
8784 点击 2025-09-30 15:36