
ICCV 2025 | ECD:高质量合成图表数据集,提升开源MLLM图表理解能力
ICCV 2025 | ECD:高质量合成图表数据集,提升开源MLLM图表理解能力在科研、新闻报道、数据分析等领域,图表是信息传递的核心载体。要让多模态大语言模型(MLLMs)真正服务于科学研究,必须具备以下两个能力
来自主题: AI技术研报
9389 点击 2025-08-22 10:35
 搜索
搜索
在科研、新闻报道、数据分析等领域,图表是信息传递的核心载体。要让多模态大语言模型(MLLMs)真正服务于科学研究,必须具备以下两个能力
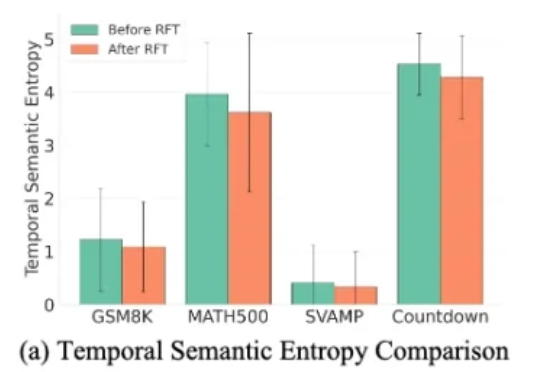
在AI浪潮席卷全球的2025年,大语言模型(LLM)已从单纯的聊天工具演变为能规划、决策的智能体。但问题来了:这些智能体一旦部署,就如「冻结的冰块」,难以适应瞬息万变的世界。
近年来,扩散大语言模型(Diffusion Large Language Models, dLLMs)正迅速崭露头角,成为文本生成领域的一股新势力。与传统自回归(Autoregressive, AR)模型从左到右逐字生成不同,dLLM 依托迭代去噪的生成机制,不仅能够一次性生成多个 token,还能在对话、推理、创作等任务中展现出独特的优势。
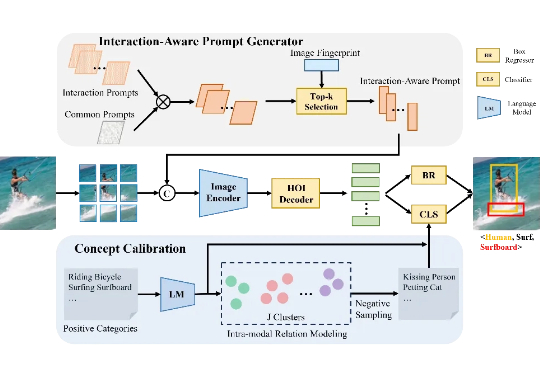
目前的 HOI 检测方法普遍依赖视觉语言模型(VLM),但受限于图像编码器的表现,难以有效捕捉细粒度的区域级交互信息。本文介绍了一种全新的开集人类-物体交互(HOI)检测方法——交互感知提示与概念校准(INP-CC)。
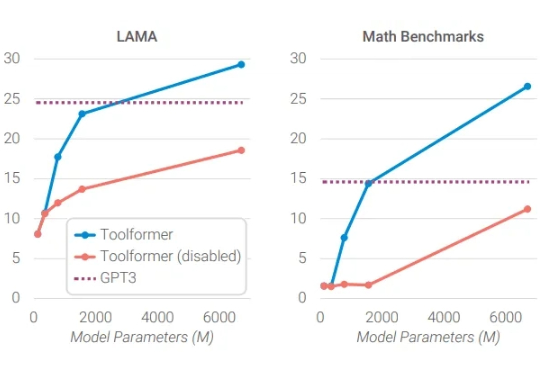
大模型OUT,小模型才是智能体的未来! 这可不是标题党,而是英伟达最新论文观点: 在Agent任务中,大语言模型经常处理重复、专业化的子任务,这让它们消耗大量计算资源,且成本高、效率低、灵活性差。
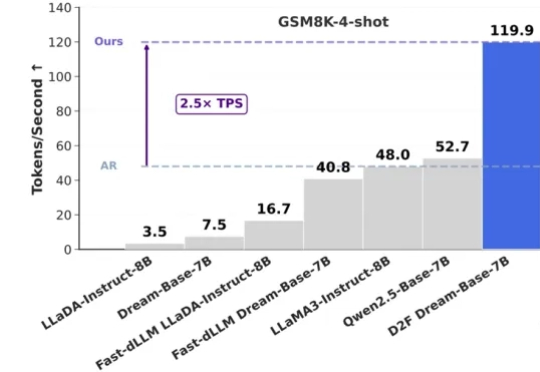
在大语言模型(LLMs)领域,自回归(AR)范式长期占据主导地位,但其逐 token 生成也带来了固有的推理效率瓶颈。此前,谷歌的 Gemini Diffusion 和字节的 Seed Diffusion 以每秒千余 Tokens 的惊人吞吐量,向业界展现了扩散大语言模型(dLLMs)在推理速度上的巨大潜力。

所有学LLM的人都要知道的内容。 这可能是对于大语言模型(LLM)原理最清晰、易懂的解读。
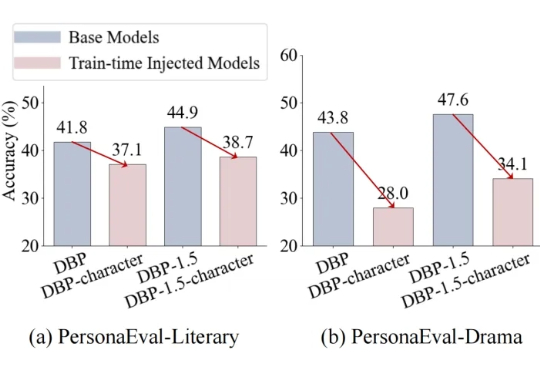
大语言模型(LLM)正从工具进化为“裁判”(LLM-as-a-judge),开始大规模地评判由AI自己生成的内容。这种高效的评估范式,其可靠性与人类判断的一致性,却很少被深入验证。
一家名为Palabra AI 的初创公司正在开发 AI 语音翻译引擎,致力于解决教学大型语言模型(LLMs)理解多种语言这一颇具挑战性的难题。
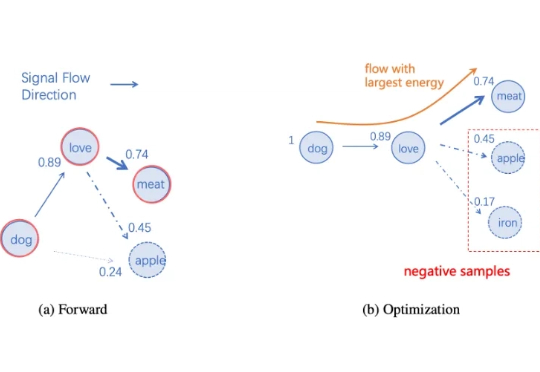
当前 GPT 类大语言模型的表征和处理机制,仅在输入和输出接口层面对语言元素保持可解释的语义映射。相比之下,人类大脑直接在分布式的皮层区域中编码语义,如果将其视为一个语言处理系统,它本身就是一个在全局上可解释的「超大模型」。