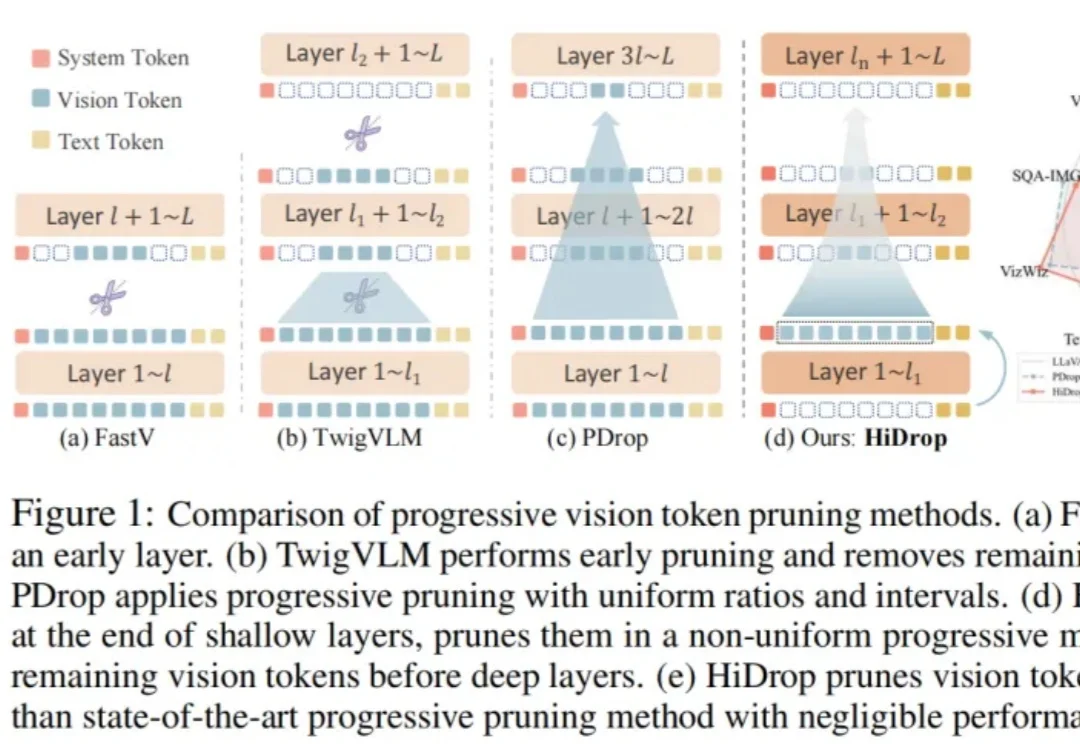
LangFlow: 挑战离散扩散,探索下一代语言模型新范式
LangFlow: 挑战离散扩散,探索下一代语言模型新范式主要作者团队:Yuxin Chen 现为伊利诺伊大学厄巴纳 - 香槟分校(UIUC)硕士一年级学生,Chumeng Liang 为 UIUC 博士一年级学生,Hangke Sui 为 UIUC 博士二年级学生,Ge Liu 为 UIUC 计算机系助理教授。Liu Lab 团队长期聚焦扩散 / 流模型方向,
来自主题: AI技术研报
7243 点击 2026-04-29 09:36