
拆解AI黑箱,深度解读“机制可解释性”|2026年十大突破性技术
拆解AI黑箱,深度解读“机制可解释性”|2026年十大突破性技术现在,我们越来越多地将大语言模型应用于搜索、编程、内容生成和决策辅助等现实场景中。尽管每天有数百万人使用大模型,但它的问题也随之而来,例如有时会产生幻觉,甚至在特定情境下表现出误导或欺骗用户的倾向。
来自主题: AI资讯
9128 点击 2026-01-13 16:09
 搜索
搜索
现在,我们越来越多地将大语言模型应用于搜索、编程、内容生成和决策辅助等现实场景中。尽管每天有数百万人使用大模型,但它的问题也随之而来,例如有时会产生幻觉,甚至在特定情境下表现出误导或欺骗用户的倾向。
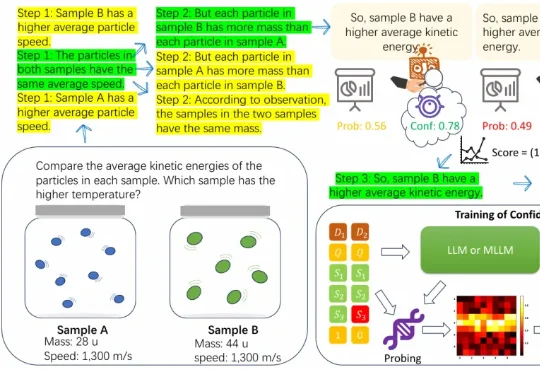
近年来,大语言模型在算术、逻辑、多模态理解等任务上之所以取得显著进展,很大程度上依赖于思维链(CoT)技术。所谓 CoT,就是让模型在给出最终答案前,先生成一系列类似「解题步骤」的中间推理。 这种方式

近日,liko.ai 宣布完成首轮融资,由商汤国香资本、东方富海、讯飞创投、洪泰基金、正轩投资、面壁智能等多家产业及财务投资机构联合投资,光源资本担任孵化方及独家财务顾问。本轮融资将用于端侧视觉语言模型、AI 原生硬件以及家庭多模态通用终端研发。
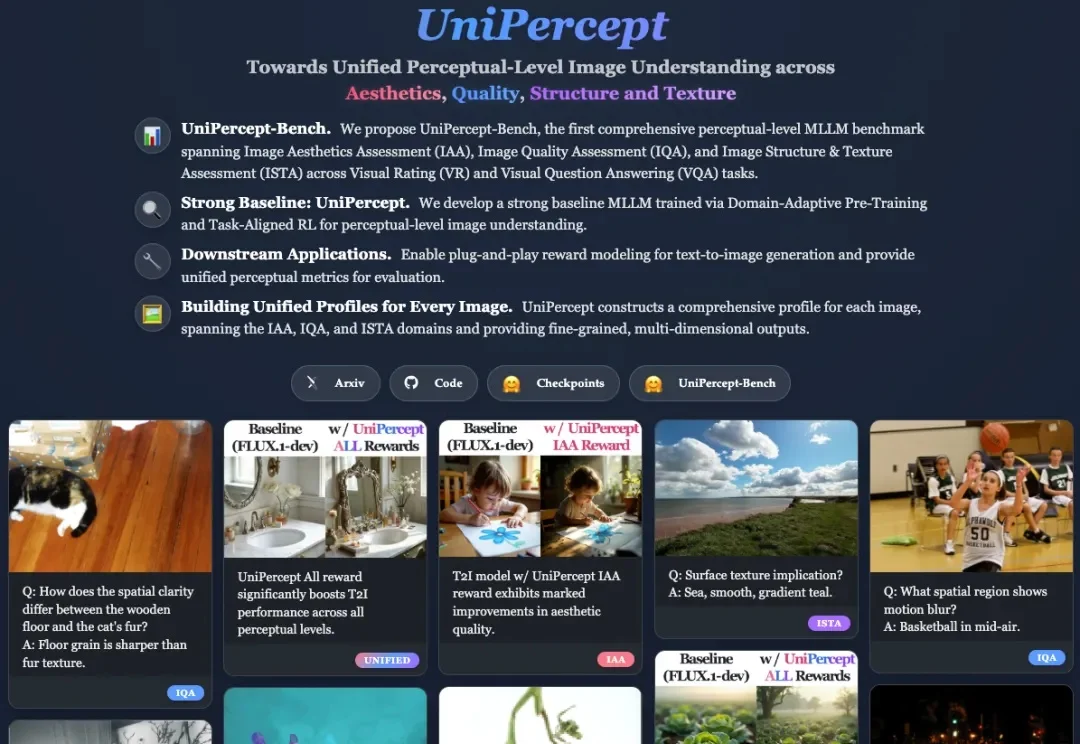
尽管多模态大语言模型(MLLMs)在识别「图中有什么」这一语义层面上取得了巨大进步,但在理解「图像看起来怎么样」这一感知层面上仍显乏力。

2023年启动大模型研发以来,腾讯第一次把大语言模型变成一把手工程,负责人是个27岁的年轻人;

如果说2025 年是 AI 接受现实检验之年 ,那么 2026 年这项技术将走向实用化。业界焦点已从构建日益庞大的语言模型,转向更艰巨的使命——让 AI 真正可用。

空间理解能力是多模态大语言模型(MLLMs)走向真实物理世界,成为 “通用型智能助手” 的关键基础。但现有的空间智能评测基准往往有两类问题:一类高度依赖模板生成,限制了问题的多样性;另一类仅聚焦于某一种空间任务与受限场景,因此很难全面检验模型在真实世界中对空间的理解与推理能力。

DeepSeek-OCR的视觉文本压缩(VTC)技术通过将文本编码为视觉Token,实现高达10倍的压缩率,大幅降低大模型处理长文本的成本。但是,视觉语言模型能否理解压缩后的高密度信息?中科院自动化所等推出VTCBench基准测试,评估模型在视觉空间中的认知极限,包括信息检索、关联推理和长期记忆三大任务。

你有没有发现,你让AI读一篇长文章,结果它读着读着就忘了前面的内容? 你让它处理一份超长的文档,结果它给出来的答案,牛头不对马嘴? 这个现象,学术界有个专门的名词,叫做上下文腐化。 这也是目前AI的通病:大模型的记忆力太差了,文章越长,模型越傻!
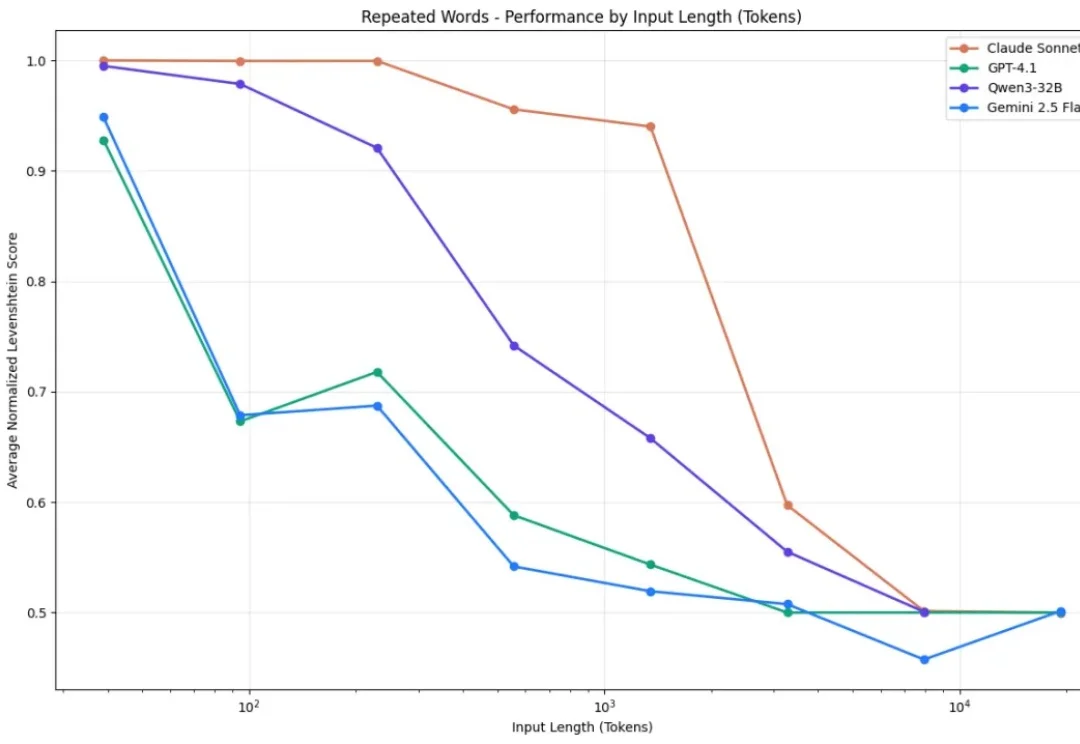
新年伊始,MIT CSAIL 的一纸论文在学术圈引发了不小的讨论。Alex L. Zhang 、 Tim Kraska 与 Omar Khattab 三位研究者在 arXiv 上发布了一篇题为《Recursive Language Models》的论文,提出了所谓“递归语言模型”(Recursive Language Models,简称 RLM)的推理策略。