
正在升温的 Voice AI 赛道,出现了一家初创团队 Hojo
正在升温的 Voice AI 赛道,出现了一家初创团队 Hojo当所有人都在盯着通用大模型时,Voice AI 这条相对安静的赛道里,也开始出现一些值得注意的新模型。最近,一家名为 Hojo 的创业团队公开披露了一组语音识别测试结果,似乎有成为「黑马」的趋势。
来自主题: AI资讯
10212 点击 2026-06-10 20:07
 搜索
搜索
当所有人都在盯着通用大模型时,Voice AI 这条相对安静的赛道里,也开始出现一些值得注意的新模型。最近,一家名为 Hojo 的创业团队公开披露了一组语音识别测试结果,似乎有成为「黑马」的趋势。
没错,用的就是主打长程任务、模糊指令遵循,跻身国产Agent第一梯队的小米MiMo‑V2.5 Pro。小米最新发布的MiMo‑V2.5系列,包含Pro旗舰Agent、全模态基座、TTS语音合成、ASR语音识别四大模型,综合实力对标国际顶尖水准。

阶跃星辰今日发布新一代自动语音识别模型StepAudio 2.5 ASR。该模型面向语音转写与长音频处理场景,在架构上引入Multi-Token Prediction(多Token预测)以提升推理效率,并通过扩展上下文窗口强化长内容识别能力。
ListenHub ASR 语音识别 API 全新上线,无限免费。 API 特点: 本地离线转录,无需 API Key,安装即可使用。专为 Agent 设计,方便你的 Claude Code 和龙虾🦞直接接入自动化工作流。
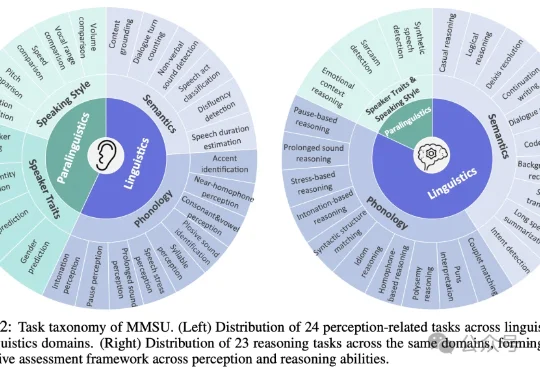
随着多模态大模型能力不断扩展,语音大模型(SpeechLLMs) 已从语音识别走向复杂语音交互。然而,当模型逐渐进入真实口语交互场景,一个更基础的问题浮现出来:我们是否真正定义清楚了「语音理解」的能力边界?
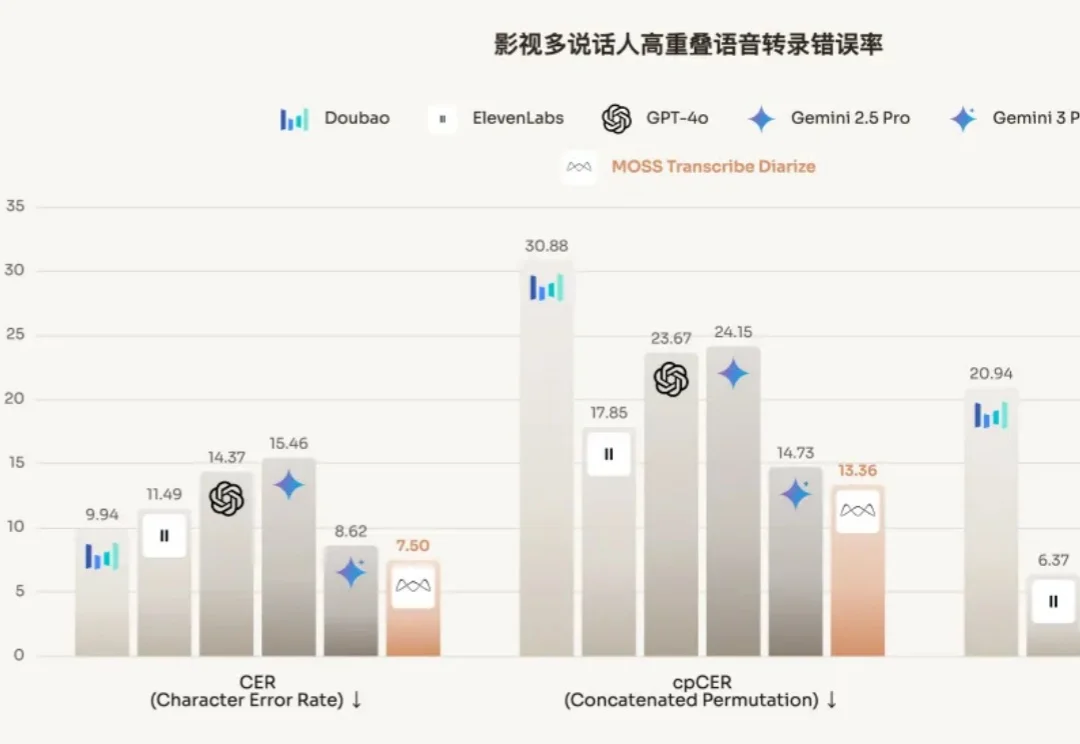
近日,由复旦邱锡鹏担任首席科学家的模思智能发布了多说话人自动语音识别(ASR)模型 MOSS-Transcribe-Diarize,不但可以语音转文字,还可以将音频片段与对话中不同的说话者关联起来,性能超过了 GPT-4o、Gemini、豆包等一众模型。

在7000多种人类语言中,只有少数被现代语音技术听见,如今这种不平等或将被打破。Meta发布的Omnilingual ASR系统能识别1600多种语言,并可通过少量示例快速学会新语言。以开源与社区共创为核心,这项技术让每一种声音都有机会登上AI的舞台。

还在忍受方言听不懂、跨省业务推进难?联通直接放出「云+AI」大招,把这些通信顽疾一锅端!本文为你揭秘,运营商如何用科技智慧破局,打开信息「黑匣子」,让效率飙升!

智东西9月15日报道,今天,阿里巴巴通义实验室推出了FunAudio-ASR端到端语音识别大模型。这款模型通过创新的Context模块,针对性优化了“幻觉”、“串语种”等关键问题,在高噪声的场景下,幻觉率从78.5%下降至10.7%,下降幅度接近70%。
如果说眼睛是心灵之窗,那么语言或许就是通往心灵的门户。