
深度体验豆包这个功能后,我有点羡慕现在的学生
深度体验豆包这个功能后,我有点羡慕现在的学生当 AI 学会「不直接给答案」
来自主题: AI产品测评
9457 点击 2026-03-19 09:47
 搜索
搜索
当 AI 学会「不直接给答案」

1984年,教育心理学家本杰明·布鲁姆(Benjamin Bloom)的一项实验,揭示了一个惊人的事实:接受一对一辅导的学生,成绩可以超越传统班级里98%的同学。这种效果被称为两个标准差优势,它证明了个性化教学的巨大潜力。但它也带来了一个现实难题:一对一辅导成本极高,无法普及。
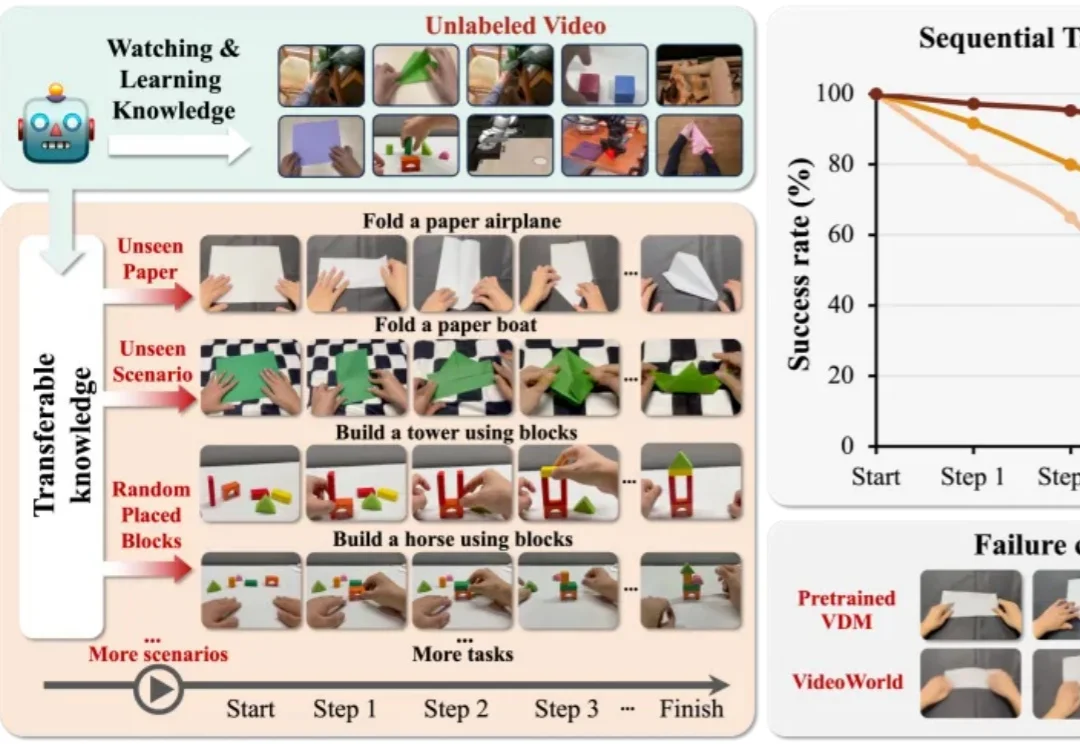
视觉世界模型 “VideoWorld 2” 由豆包大模型团队与北京交通大学联合提出。不同于 Sora 2 、Veo 3、Wan 2.2 等主流多模态模型,VideoWorld 系列工作在业界首次实现无需依赖语言模型,即可认知世界。

两个月前我第一次接触 OpenClaw 的时候也是这样:我当时花了一下午部署成功,兴冲冲地打开对话框,让它帮我写个周报。结果也就那样,还不如问豆包。然后再让它帮我查个资料,它要么打开链接失败,要么给的不是我想要的,体验感极差,这还个人助理个啥啊。

我天!感觉 Seed 1.8 发布还没多久,没想到 Doubao-Seed-2.0 这么快就杀到了…今天发都算是晚讯了。据官方介绍,这次 Seed 2.0 多模态理解能力全面升级,还强化了 LLM 与 Agent 能力,模型在真实长链路任务中可以稳定推进。
原本以为,三星 Galaxy S26 系列早已被曝光,发布会也就走个流程。没想到三星和 Google 还藏了一手。 两家公司共同展示了 S26 搭载的全新 Gemini 智能体能力:口头吩咐一句话,G

北京时间今天凌晨,三星正式发布了年度旗舰新机Galaxy S26系列,这也是三星第三代AI手机,其重点提升了AI、影像、性能等方面的能力。发布会后,智东西第一时间上手体验了最新的三星旗舰机,其在视频防抖、AI视频问答、AI智能执行方面都给我留下了深刻印象。

此前彭博社等媒体报道称,近期月之暗面即将完成的超7亿美元融资,由阿里、腾讯、五源资本、九安医疗等老股东领投,并且已经超募。与此同时,月之暗面已经以100亿-120亿美金的估值,无缝开启了新一轮融资。

结果今天就等到豆包全家族了。Seedance 2.0都把贾樟柯干Fomo了,现在又上了个最全面的多模态Agent模型,还有人管管字节吗?Seed团队跳动得停不下来了💃烧的全是火山引擎上的Tokens,同时火山引擎上已经有豆包2.0系列的API了。

2026年2月12日,字节跳动正式发布新一代AI视频生成模型Seedance 2.0,同步接入豆包App、即梦App等平台,凭借广播级画质、丝滑运镜、多镜头叙事控制的工业级生成能力,迅速引发全球行业关注。