我在 iPhone 17 Pro Max 上跑 AI 模型,体验了一把十年前「越狱」的快乐
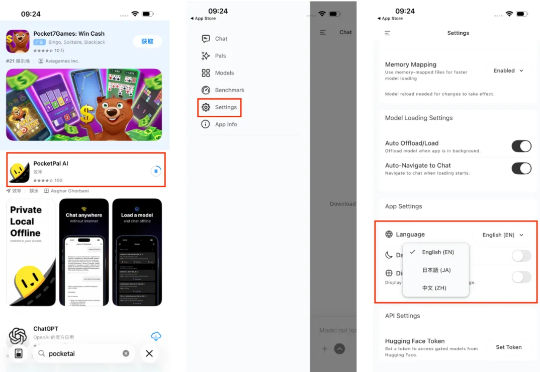
我在 iPhone 17 Pro Max 上跑 AI 模型,体验了一把十年前「越狱」的快乐在 iPhone 上部署端侧 AI 模型,成了互联网的新显学。在 iPhone 上体验端侧模型,门槛其实不算高。打开 App Store,搜索 PocketPal AI,下载安装。如果不习惯英文界面,可以在设置 (Setting) 里找到语言 (Language) 选项,切换成中文。
来自主题: AI资讯
10711 点击 2025-10-19 22:11