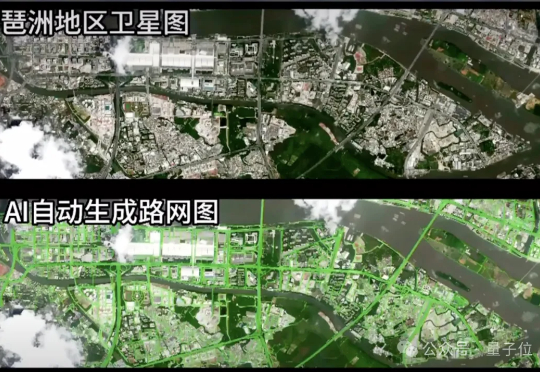
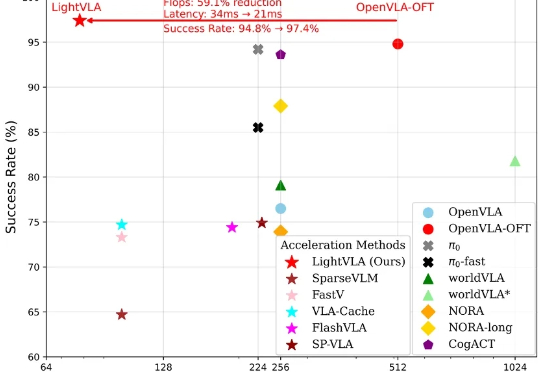
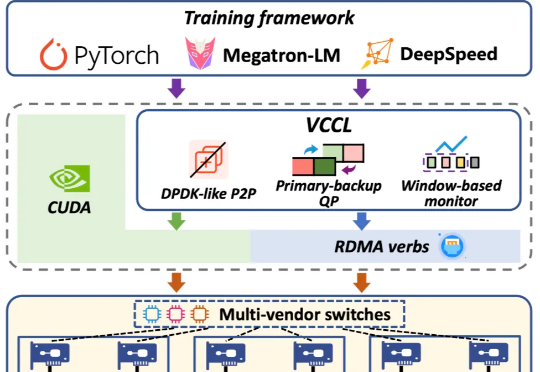
做MCP的基础设施,种子轮就拿3500万美金,让AI Agent像管理容器一样简单
做MCP的基础设施,种子轮就拿3500万美金,让AI Agent像管理容器一样简单Obot MCP Gateway是他们解决方案的核心,这是一个开源控制平面,为IT团队提供了对MCP部署前所未有的可见性和控制能力。从架构上看,这个网关采用了代理模式,所有与MCP服务器的通信都会通过网关进行代理,这为审计、日志记录和应用安全策略提供了单一控制点。这种设计消除了影子AI的可能性,确保了合规性。
来自主题: AI资讯
10213 点击 2025-10-03 00:02