
LLM会梦到AI智能体吗?不,是睡着了也要加班
LLM会梦到AI智能体吗?不,是睡着了也要加班人类的大脑,会在梦里筛选记忆。如今,AI也开始学会在「睡眠」中整理、保存,甚至遗忘。Bilt部署数百万智能体,让科幻小说里的设问——「仿生人会梦见电子羊吗?」——逐步成真。那么,当AI也能选择忘记时,它会变得更像人,还是更陌生?
来自主题: AI资讯
8352 点击 2025-09-16 15:55
 搜索
搜索
人类的大脑,会在梦里筛选记忆。如今,AI也开始学会在「睡眠」中整理、保存,甚至遗忘。Bilt部署数百万智能体,让科幻小说里的设问——「仿生人会梦见电子羊吗?」——逐步成真。那么,当AI也能选择忘记时,它会变得更像人,还是更陌生?
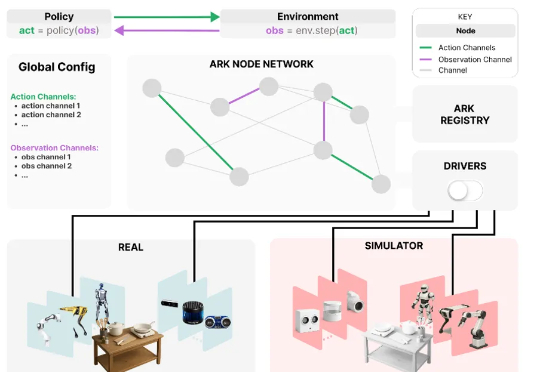
为应对这些挑战,来自华为诺亚方舟实验室,德国达姆施塔特工业大学,英国伦敦大学学院,帝国理工学院和牛津大学的研究者们联合推出了 Ark —— 一个基于 Python 的机器人开发框架,支持快速原型构建,并可便捷地在仿真和真实机器人系统上部署新算法。
时薪900美元的AI工程师正成为咨询界新贵,直接挑战麦肯锡等传统巨头。面对高达95%的企业AI项目失败率,传统MBA式顾问空有战略却难落地。为此,Hasura推出了一种新型「AI工程师顾问」应运而生,他们不仅能提供策略,更能亲手编码、部署,弥合了从构想到现实的鸿沟。

只用 1.5% 的内存预算,性能就能超越使用完整 KV cache 的模型,这意味着大语言模型的推理成本可以大幅降低。EvolKV 的这一突破为实际部署中的内存优化提供了全新思路。

我们今天正式开源 jina-code-embeddings,一套全新的代码向量模型。包含 0.5B 和 1.5B 两种参数规模,并同步推出了 1-4 bit 的 GGUF 量化版本,方便在各类端侧硬件上部署。
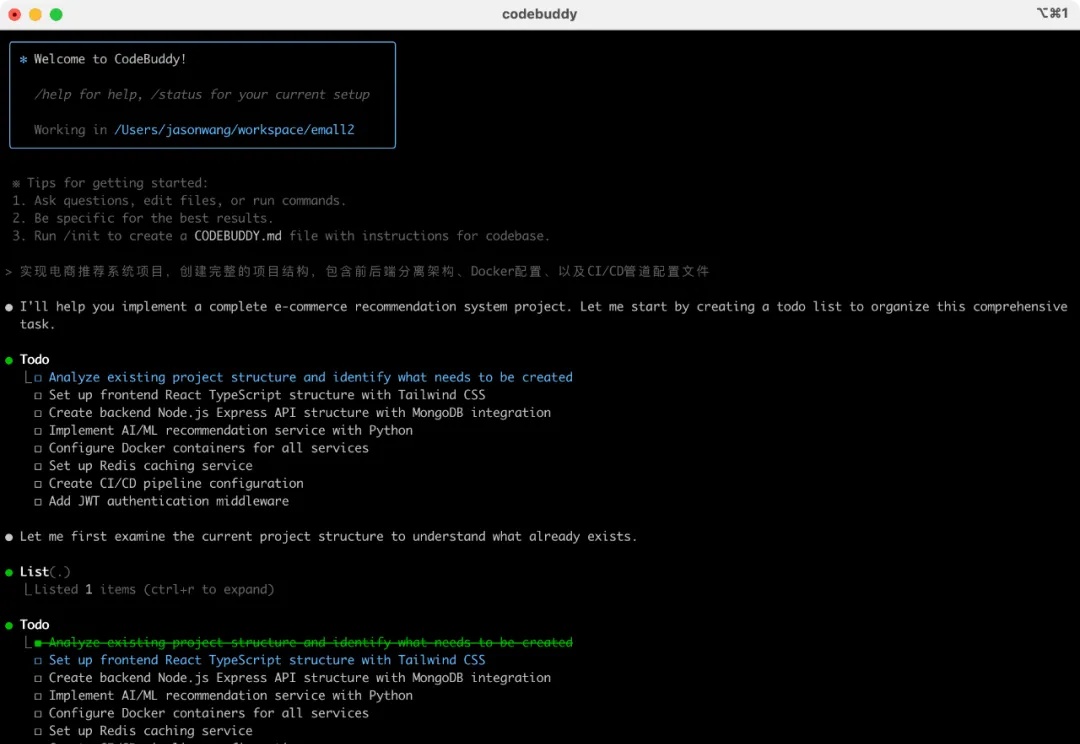
作为一名有着8年全栈开发经验的技术人员,我最近接手了一个具有挑战性的项目:为某中型服装电商平台开发一套智能商品推荐系统。该系统需要在2个月内完成,包含以下核心功能:
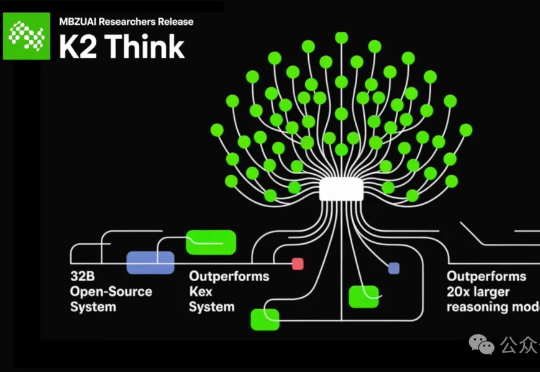
全球最快的开源大模型来了——速度达到了每秒2000个tokens! 虽然只有320亿参数(32B),吞吐量却是超过典型GPU部署的10倍以上的那种。它就是由阿联酋的穆罕默德·本·扎耶德人工智能大学(MBZUAI)和初创公司G42 AI合作推出的K2 Think。
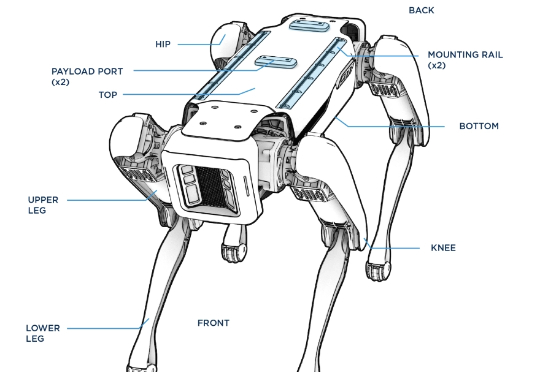
刚刚,风头被中国机器人盖过的波士顿动力,又整了个大活!前后空翻我还能理解,这侧空翻?(不是哥们,你真会啊!)他们先在仿真环境中进行强化学习,一旦策略出现问题,那么他们就将其部署在真机上进行测试,观察问题,然后反复测试迭代,加强Spot的稳定性。
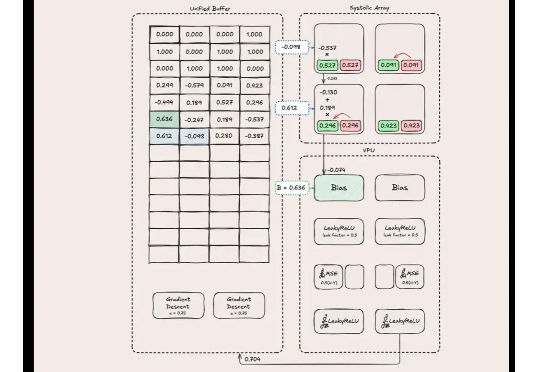
对于计算任务负载来说,越是专用,效率就越高,谷歌的 TPU 就是其中的一个典型例子。它自 2015 年开始在谷歌数据中心部署后,已经发展到了第 7 代。目前的最新产品不仅使用了最先进的制程工艺打造,也在架构上充分考虑了对于机器学习推理任务的优化。TPU 的出现,促进了 Gemini 等大模型技术的进展。

本文介绍使用四块Framework主板构建AI推理集群的完整过程,并对其在大语言模型推理任务中的性能表现进行了系统性评估。该集群基于AMD Ryzen AI Max+ 395处理器,采用mini ITX规格设计,可部署在10英寸标准机架中。