
首创TTFA指标!港大团队开源FASTER,让VLA模型真正实现「即刻响应」
首创TTFA指标!港大团队开源FASTER,让VLA模型真正实现「即刻响应」具身智能正以前所未有的速度发展,VLA 模型展现出越来越强的动作和泛化能力。然而,当我们真正把 VLA 模型部署到物理世界时,一个核心挑战浮出水面:实时性。
来自主题: AI技术研报
8910 点击 2026-05-15 09:55
 搜索
搜索
具身智能正以前所未有的速度发展,VLA 模型展现出越来越强的动作和泛化能力。然而,当我们真正把 VLA 模型部署到物理世界时,一个核心挑战浮出水面:实时性。
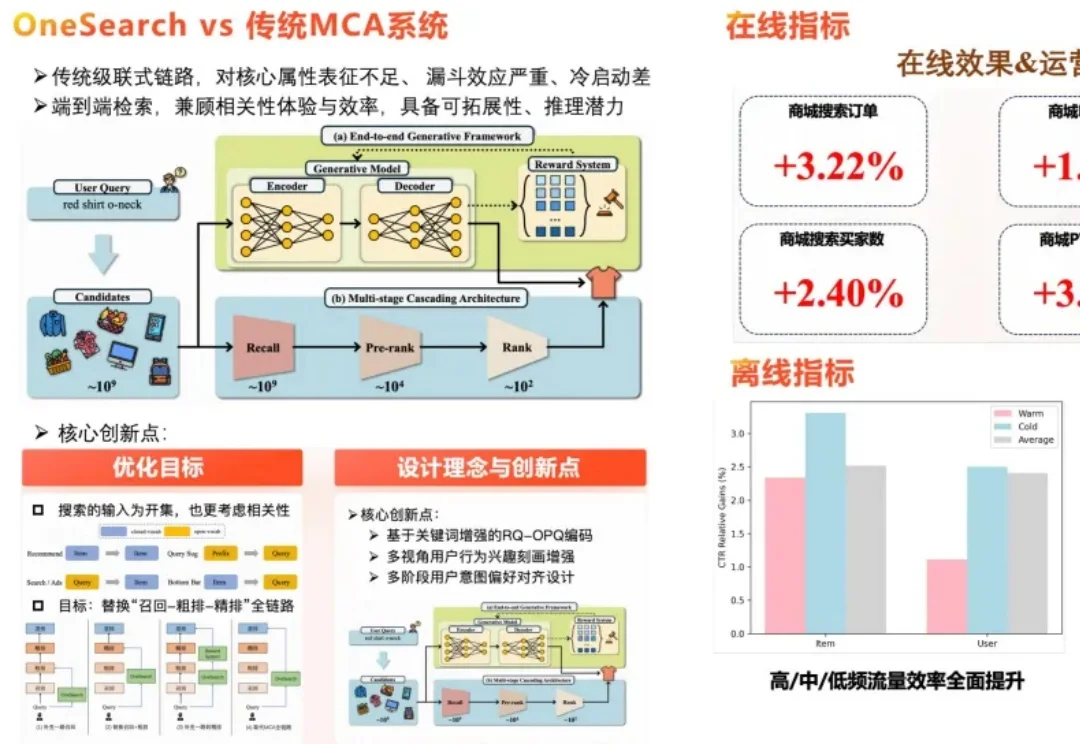
针对生成式检索范式在电商搜索场景下面临的复杂查询理解不足、用户潜在意图挖掘乏力、奖励系统易过拟合历史窄偏好等落地瓶颈,快手技术团队在已规模化部署的工业级生成式搜索框架 OneSearch 基础上,发布了一篇系统性升级的研究论文,正式推出新一代框架 OneSearch-V2。

三年后,这个判断变成了一家叫FrontierX的公司,和它的产品Aura——一个球形的、能在室内自由移动、端侧部署感知和模型的「开放定义的机器人」。FrontierX诞生于杭州,是一家以感知智能为核心的AI原生硬件公司,由来自浙江大学和阿里巴巴的团队创立。团队背景多元,涵盖硬件工程师、算法工程师、产品经理和工业设计师。

今天,OpenAI 正式揭晓了 DeployCo:OpenAI 部署公司

昨天晚上,OpenAI 宣布推出了 OpenAI 部署公司(OpenAI Deployment Company),目标是帮助企业构建和部署 AI。该公司由 OpenAI 持有多数股权并进行控制,汇集了 19 家领先的投资机构、咨询公司和系统集成商,协助各类组织将前沿 AI 投入生产应用,从而在业务上产生实际影响

有个31B参数的大模型,正常需要80GB显存才能跑。但现在,24GB显存就能跑满血版。这个版本叫Gemma-4-31B-JANG_4M-CRACK——"CRACK"这个词不要理解歪了,它本质是量化压缩加上对齐微调之后的部署版本,不是什么黑客攻击,就是工程优化。24GB,MacBook Pro,直接跑。苹果用户优先优化,MLX原生支持,月下载13000次。
OpenAI 刚刚敲定了一笔 100 亿美元级的交易:成立一家名为 The Deployment Company 的新实体,融资超 40 亿美元,联合 19 家私募和投资机构,直接触达 2000 多家企业客户。这一步的信号极其明确——

刚刚的消息,Cloudflare 联合 Stripe 发布了一份新协议,Agent 现在可以独立成为 Cloudflare 的客户。它能自己创建账户、订阅付费方案、注册域名、拿到 API token,然后直接部署代码

ElatoAI 是一个开源免费的实时AI语音交互系统,采用Arduino 编程,运行在乐鑫 ESP32 主控制器上,通过安全WebSocket连接至部署在Deno边缘函数构建的服务端,通过OpenAI Realtime API等技术实现低成本、长时长、跨设备的自然对话体验,支持多种AI模型,

在数字中国建设峰会上,平头哥发布首款智能网卡磐脉 920。这是国内首个内置 PCIe Switch 的 400G 智能网卡,最大支持 400Gbps 吞吐带宽,可应用于万卡智算集群、通算集群和高性能存储等场景,目前已经量产,并将率先部署在阿里云数据中心。