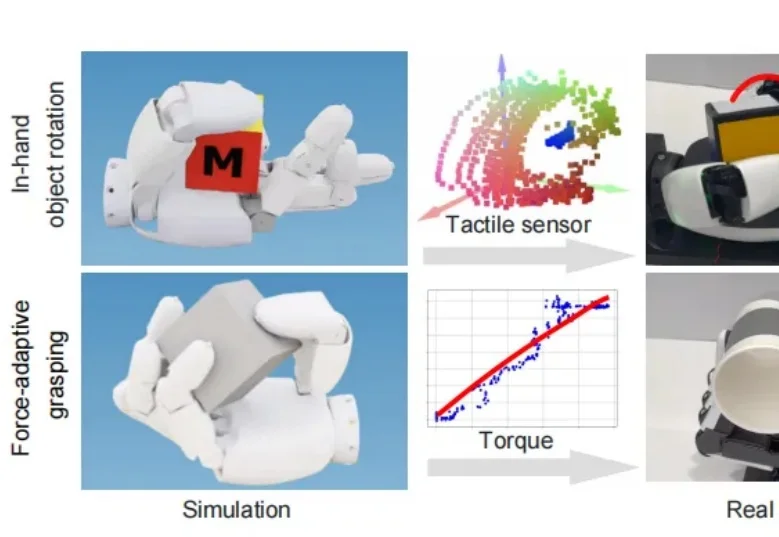
零样本 Sim-to-Real !实现五指灵巧手力控抓取与手内操作
零样本 Sim-to-Real !实现五指灵巧手力控抓取与手内操作实现具备人类水平的灵巧操作能力,是机器人学领域长期以来的核心挑战之一。尽管多指灵巧手在硬件上具备了类似人类的潜力,但由于接触丰富的物理特性和非理想的驱动机制,训练能够直接部署在真实硬件上的控制策略仍然非常困难。
来自主题: AI技术研报
6770 点击 2026-03-26 10:48
 搜索
搜索
实现具备人类水平的灵巧操作能力,是机器人学领域长期以来的核心挑战之一。尽管多指灵巧手在硬件上具备了类似人类的潜力,但由于接触丰富的物理特性和非理想的驱动机制,训练能够直接部署在真实硬件上的控制策略仍然非常困难。
一家企业花了七周时间部署 AI:第 1 周精准回答行业分析问题,团队欢呼;第 3 周反复回答相同的错误结论,因为它“忘了”上周的修正;第 5 周在董事会汇报中引用了已被否定的数据,造成决策偏差;第 7 周项目暂停,“AI 不可信”成为共识。问题不在于 AI 不够聪明,而在于它每次醒来都是一张白纸。
养虾🦞(OpenClaw)这阵风刮得太猛了,不止个人在玩,企业也都在装,生怕落后。

我们也在 Claude Code、本地部署的龙虾里,都接入了 MiniMax M2.7 模型,以及 MiniMax 提供的 MaxClaw,然后把真实的开发过程中遇到的 Bug、枯燥的金融数据,还有大量的长流程任务统统交给它。

昨晚(3月16日),朋友圈里有不少人在转飞书玩虾大会的加更直播链接。说是李诞和呼兰还有小声比比在现场实操演示,怎么玩最近科技圈炙手可热的小龙虾(OpenClaw)。 坦白说,作为一个在AI行业两年多、自己折腾过本地服务器部署、写过无数复杂Prompt的从业者和观察者,我一开始点进直播间的心态,是带着一点傲慢和不屑的。

随着生成式 AI 迈入万亿参数时代,大语言模型(LLM)的推理与部署面临着前所未有的“显存墙”挑战。如何在超节点(SuperNode)复杂的异构存储架构下,实现海量张量的高效管理和调度,已成为大模型落地的胜负手。
《读佳》获悉,阿里巴巴正开发最新AI产品“秒悟Meoo”,官方介绍指出:秒悟 Meoo 是一款革命性的云端 AI 开发工具。它就像一个“会编程、懂设计、自部署的全能 AI 伙伴”。秒悟Meoo生成的项目支持可视化页面编辑和多人在线协作编辑两项高级功能。

随着龙虾OpenClaw热潮持续,复杂的云端部署已经无法满足用户的需求,尤其是最近两周,涌现出了大量在原OpenClaw基础上定制的新产品,其中很多已经实现了应用化,用户只需要点击下载注册应用就能够体验OpenClaw的部分功能。
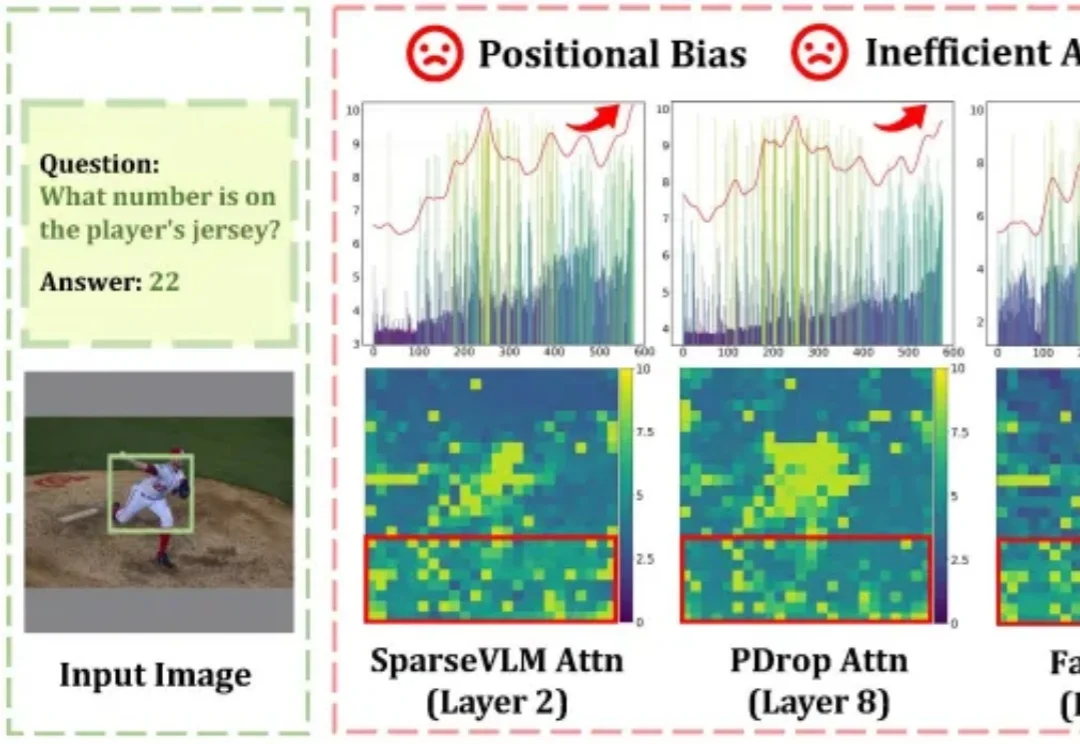
随着高分辨率图像理解与长视频处理需求的爆发式增长,大型视觉语言模型(LVLMs)所需处理的视觉 Token 数量急剧膨胀,推理效率成为落地部署的核心瓶颈。Token 压缩是缩短序列、提升吞吐的直接手段,但现有方法普遍依赖注意力权重来判断 Token 重要性,这一路线暗藏两个致命缺陷:
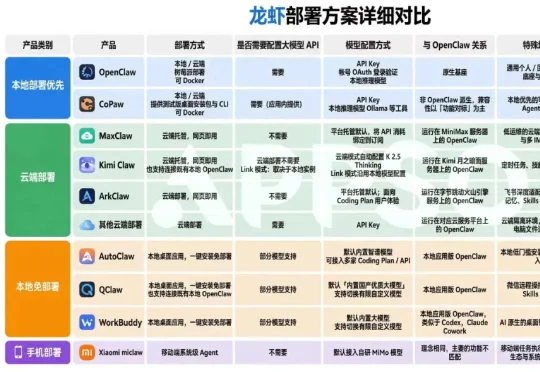
用这篇文章把现在市面上不同的龙虾产品统统讲清楚,看看哪个最合你的口味。同时,我们还会手把手教你在本地,安全地部署一只原汁原味的龙虾。