Kimi新论文:把KVCache玩成新商业模式了
Kimi新论文:把KVCache玩成新商业模式了把长上下文做到极致的Kimi又发新成果!
来自主题: AI技术研报
7570 点击 2026-04-20 09:46
 搜索
搜索
把长上下文做到极致的Kimi又发新成果!

对本地部署玩家,尤其是Mac用户来说,长上下文推理最大的痛点往往不是“模型不够聪明”,而是稍微多用点上下文,统一内存就被撑爆了”,这一点在最近的Gemma-4 31B的部署中尤为明显,在同等上下文的情况,显存占用比Qwen3.5-27B高约一倍不止,直接劝退了不少人。但好消息是,谷歌近期提出的TurboQuant KV缓存量化算法,正是为了解决这个痛点而生。
长上下文推理已经成了VLM/LLM的默认形态。
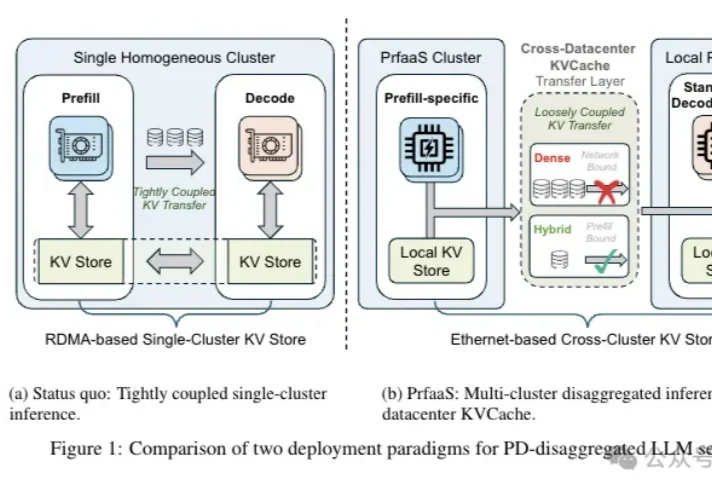
随着大模型长上下文能力快速增长,海量 KV Cache 存储需求急剧增加,各类 KV Cache 压缩方法如雨后春笋般涌现。然而,这些方案在真实场景中的工程落地却常常陷入困境。
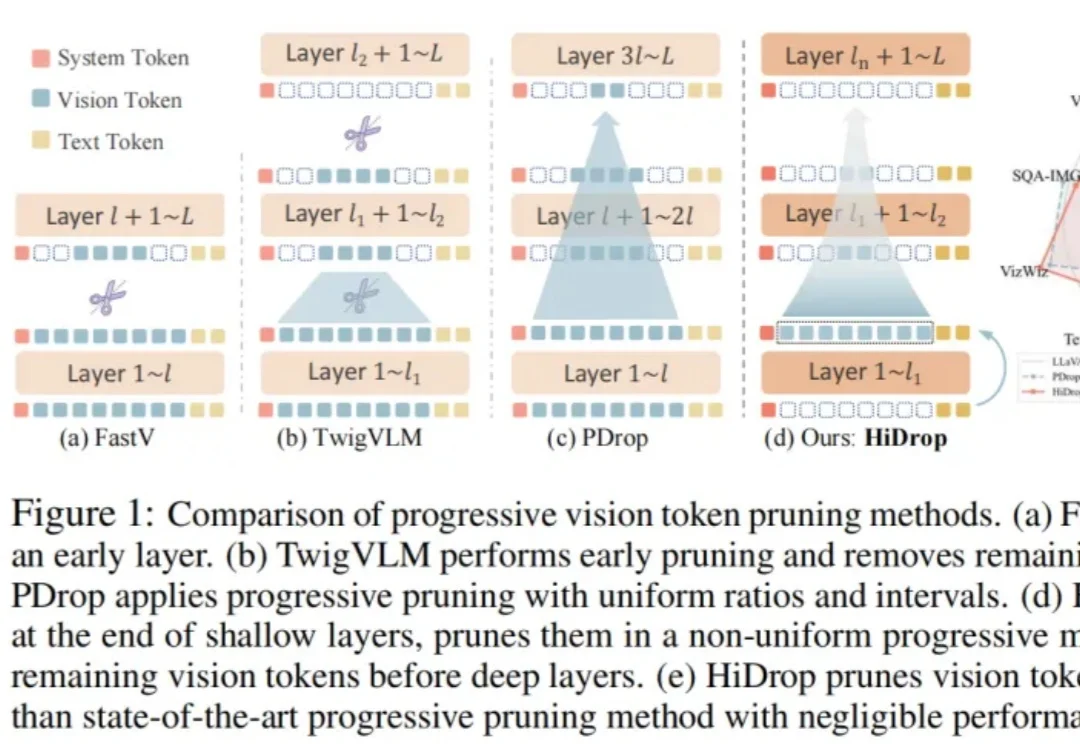
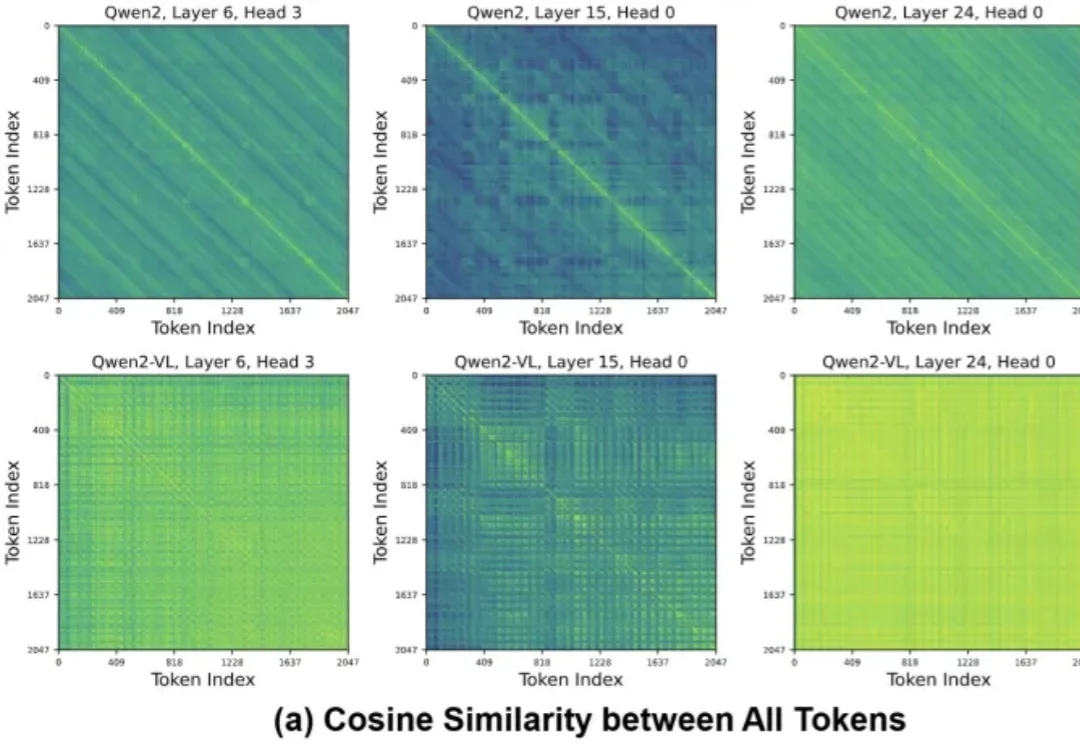
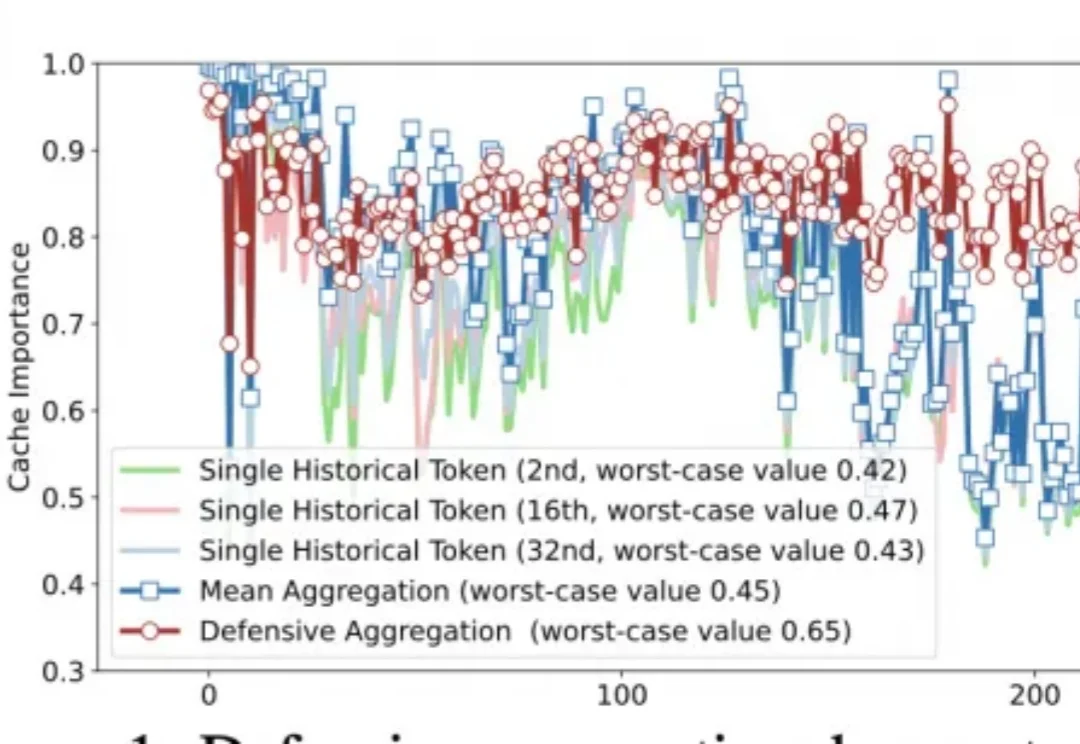
随着多模态大语言模型(MLLM)支持更长上下文,高分辨率图像和长视频会产生远多于文本的视觉 Token,在自注意力二次复杂度下迅速成为效率瓶颈。
在他们看来,真正的胜负手不在于单点技能拉满,而在于能否在同一颗芯片里,把“训练级吞吐”和“推理级低延迟”同时做好——尤其是在长上下文、Agent循环这些更复杂的真实工作流中。

这次是 Anthropic,率先发布了他们称之为「我们目前能力最强的 Sonnet 模型」Claude Sonnet 4.6。Claude 称,新模型对编码、计算机使用、长上下文推理、智能体规划、知识工作和设计进行了全面升级。
今日凌晨,Anthropic推出史上最强Sonnet模型——Claude Sonnet 4.6,新模型在编程、计算机使用、长上下文推理、Agent规划、知识工作和设计工作上全面进化。
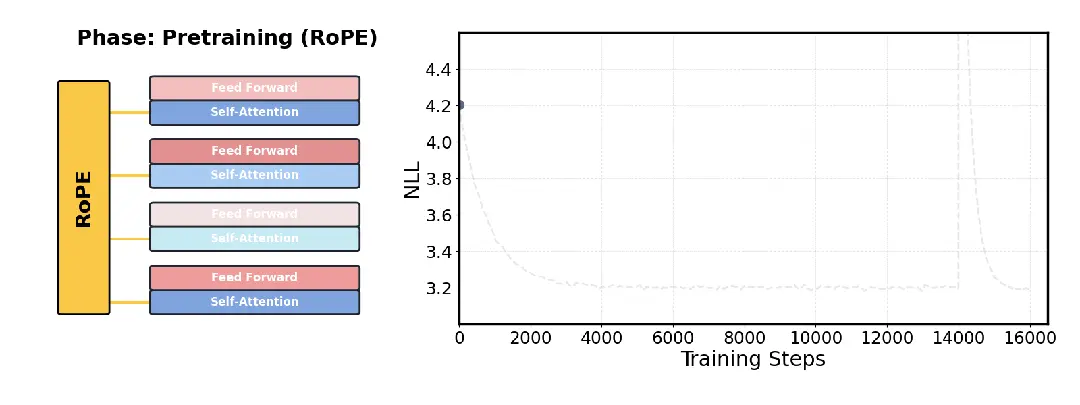
针对大模型长文本处理难题,Transformer架构的核心作者之一Llion Jones领导的研究团队开源了一项新技术DroPE。

参数越小,智商越高?Gemini 3 Flash用百万级长上下文、白菜价成本,把自家大哥Pro按在地上摩擦。谷歌到底掏出了什么黑魔法,让整个大模型圈开始怀疑人生?