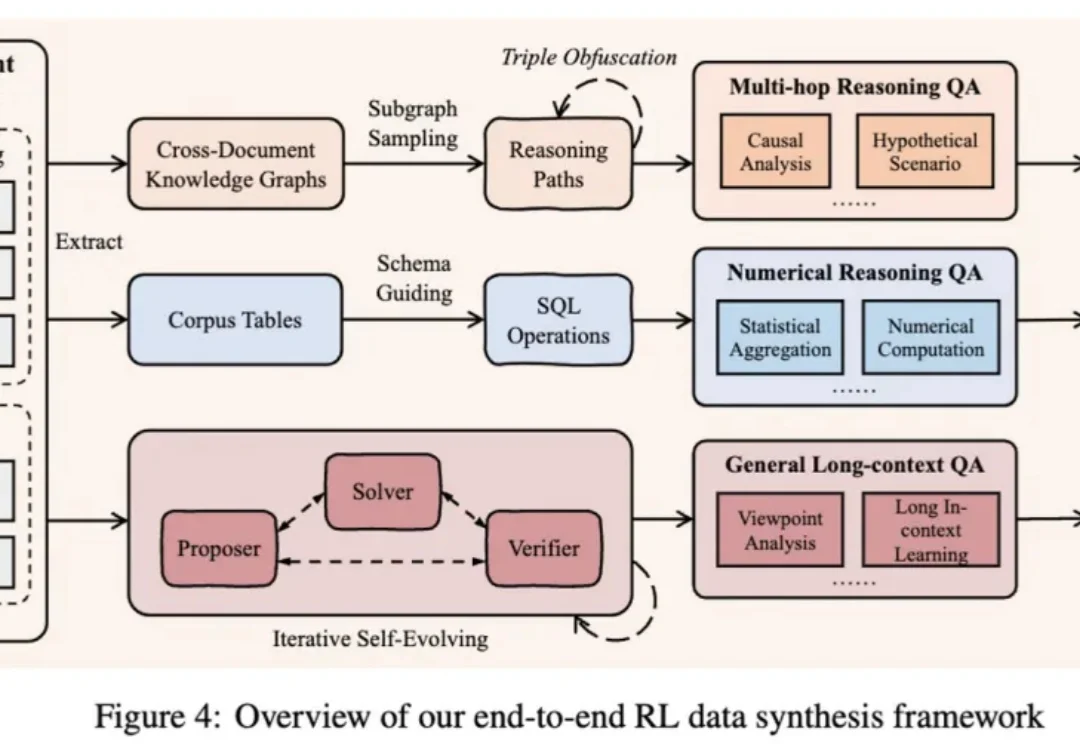
QwenLong-L1.5发布:一套配方,三大法宝,让30B MoE模型长文本推理能力媲美GPT-5
QwenLong-L1.5发布:一套配方,三大法宝,让30B MoE模型长文本推理能力媲美GPT-5作为大模型从业者或研究员的你,是否也曾为一个模型的 “长文本能力” 而兴奋,却在实际应用中发现它并没有想象中那么智能?
来自主题: AI技术研报
8751 点击 2025-12-29 14:35
 搜索
搜索
作为大模型从业者或研究员的你,是否也曾为一个模型的 “长文本能力” 而兴奋,却在实际应用中发现它并没有想象中那么智能?
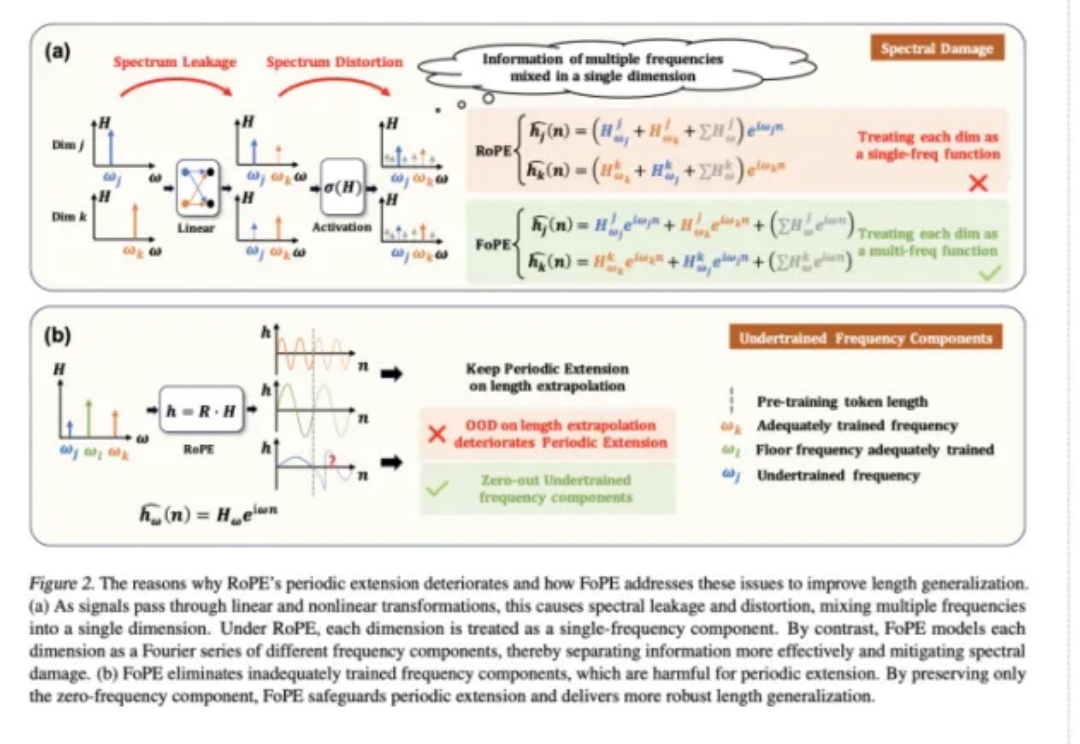
长文本能力对语言模型(LM,Language Model)尤为重要,试想,如果 LM 可以处理无限长度的输入文本,我们可以预先把所有参考资料都喂给 LM,或许 LM 在应对人类的提问时就会变得无所不能。
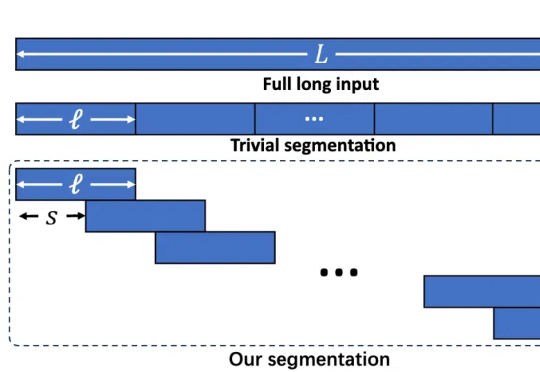
长文本任务是当下大模型研究的重点之一。在实际场景和应用中,普遍存在大量长序列(文本、语音、视频等),有些甚至长达百万级 tokens。
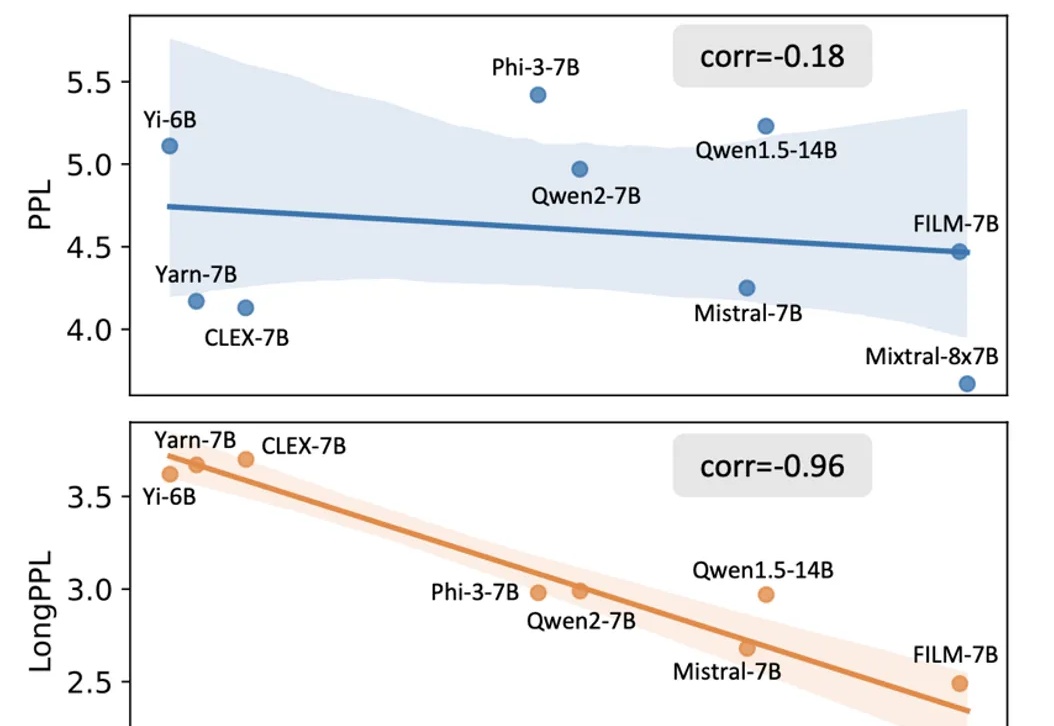
随着大模型在长文本处理任务中的应用日益广泛,如何客观且精准地评估其长文本能力已成为一个亟待解决的问题。

大模型长文本能力测试,又有新方法了!

CLIP长文本能力被解锁,图像检索任务表现显著提升!一些关键细节也能被捕捉到。上海交大联合上海AI实验室提出新框架Long-CLIP。

“据我了解,国内多个一线大模型机构,都已经突破了兆级的长文本能力。”以上,是“2024全球开发者先锋大会”大模型前沿论坛会间隙,上海人工智能实验室领军科学家林达华与量子位的交谈剪影。
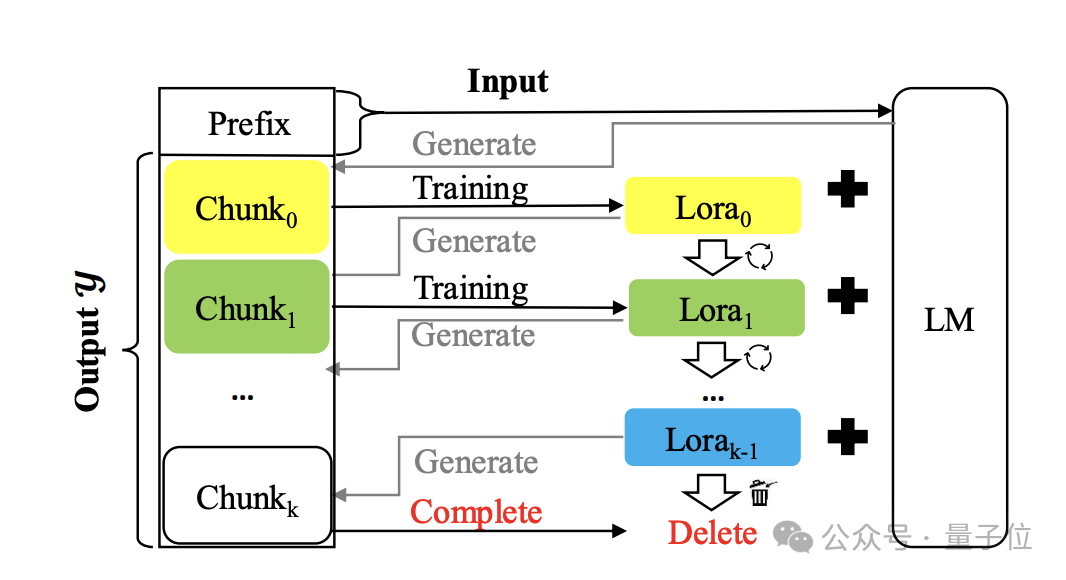
来看一个奇妙新解:和长度外推等方法使用KV缓存的本质不同,它用模型的参数来存储大量上下文信息。