NeurIPS 2025 | 面向具身场景的生成式渲染器TC-Light来了,代码已开源
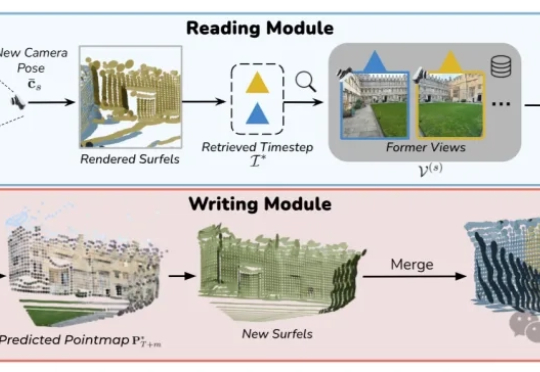
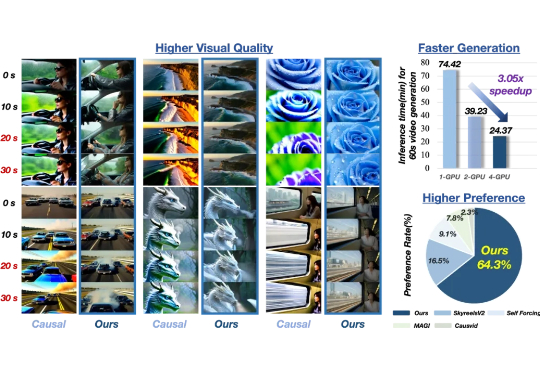
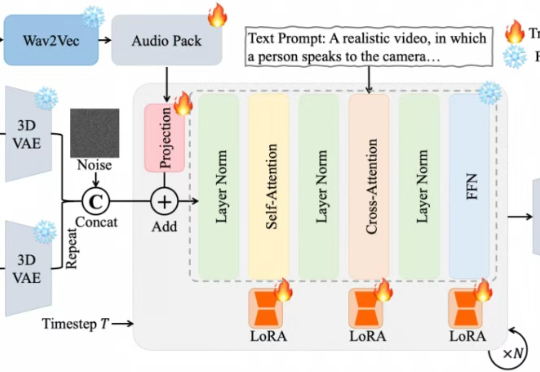
NeurIPS 2025 | 面向具身场景的生成式渲染器TC-Light来了,代码已开源TC-Light 是由中科院自动化所张兆翔教授团队研发的生成式渲染器,能够对具身训练任务中复杂和剧烈运动的长视频序列进行逼真的光照与纹理重渲染,同时具备良好的时序一致性和低计算成本开销,使得它能够帮助减少 Sim2Real Gap 以及实现 Real2Real 的数据增强,帮助获得具身智能训练所需的海量高质量数据。
来自主题: AI技术研报
8447 点击 2025-09-27 11:06