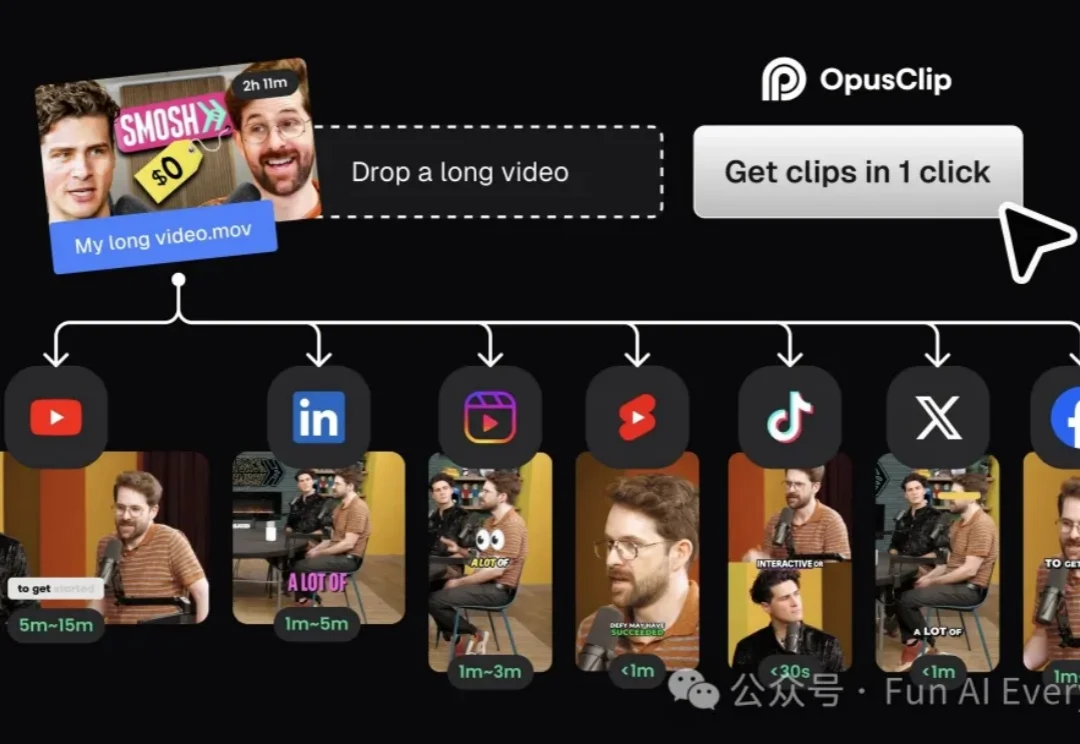
2.15 亿美元估值的 AI 创业复盘:OpusClip CEO 讲 30 天怎么做出能赚钱的产品
2.15 亿美元估值的 AI 创业复盘:OpusClip CEO 讲 30 天怎么做出能赚钱的产品OpusClip 是一款把长视频、长内容自动剪成可发布的短视频片段的 AI 工具,服务内容创作者和企业内容团队。
来自主题: AI资讯
8488 点击 2026-01-26 11:28
 搜索
搜索
OpusClip 是一款把长视频、长内容自动剪成可发布的短视频片段的 AI 工具,服务内容创作者和企业内容团队。
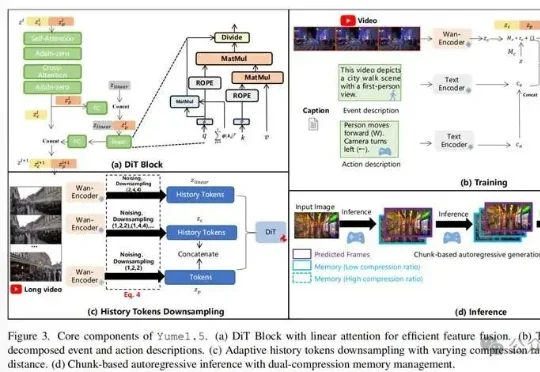
上海AI Lab联合多家机构开源的Yume1.5,针对这一核心难题提出了时空信道联合建模(TSCM),在长视频生成中实现了近似恒定计算成本的全局记忆访问。

大部分的高质量视频生成模型,都只能生成上限约15秒的视频。清晰度提高之后,生成的视频时长还会再一次缩短。

视频生成模型总是「记性不好」?生成几秒钟后物体就变形、背景就穿帮?北大、中大等机构联合发布EgoLCD,借鉴人类「长短时记忆」机制,首创稀疏KV缓存+LoRA动态适应架构,彻底解决长视频「内容漂移」难题,在EgoVid-5M基准上刷新SOTA!让AI像人一样拥有连贯的第一人称视角记忆。
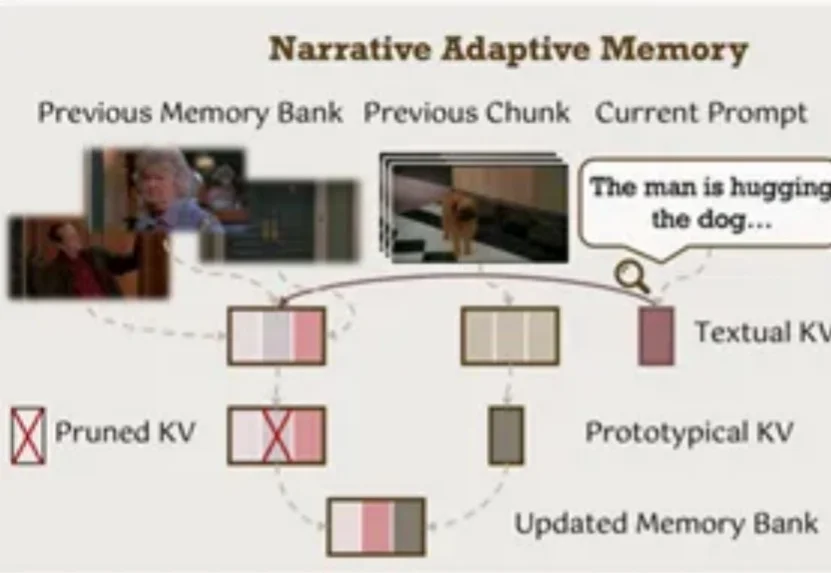
你是否曾被AI视频生成的不连贯性所困扰?
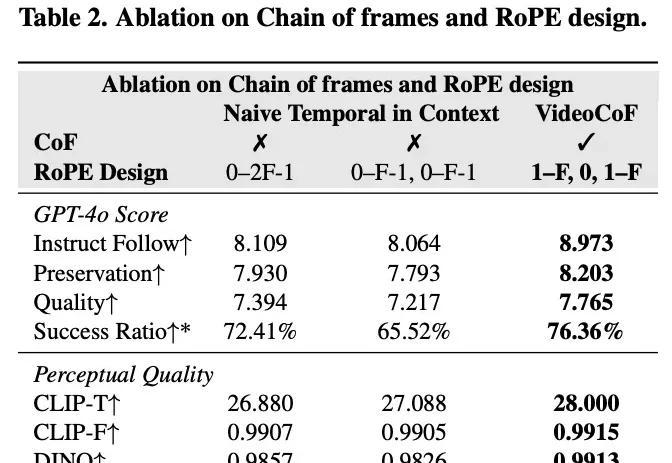
现有的视频编辑模型往往面临「鱼与熊掌不可兼得」的困境:专家模型精度高但依赖 Mask,通用模型虽免 Mask 但定位不准。来自悉尼科技大学和浙江大学的研究团队提出了一种全新的视频编辑框架 VideoCoF,受 LLM「思维链」启发,通过「看 - 推理 - 编辑」的流程,仅需 50k 训练数据,就在多项任务上取得了 SOTA 效果,并完美支持长视频外推!

去年,谢赛宁(Saining Xie)团队发布了 Cambrian-1,一次对图像多模态模型的开放式探索。但团队没有按惯例继续推出 Cambrian-2、Cambrian-3,而是停下来思考:真正的多
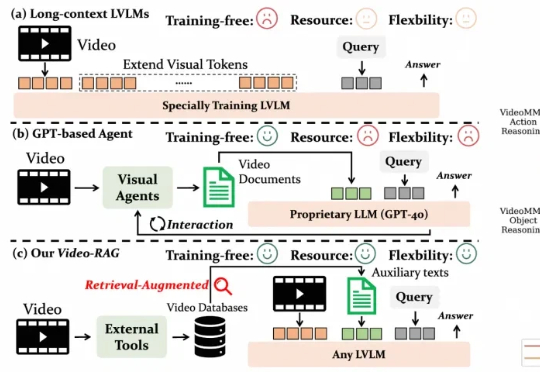
尽管视觉语言模型(LVLMs)在图像与短视频理解中已取得显著进展,但在处理长时序、复杂语义的视频内容时仍面临巨大挑战 —— 上下文长度限制、跨模态对齐困难、计算成本高昂等问题制约着其实际应用。针对这一难题,厦门大学、罗切斯特大学与南京大学联合提出了一种轻量高效、无需微调的创新框架 ——Video-RAG。
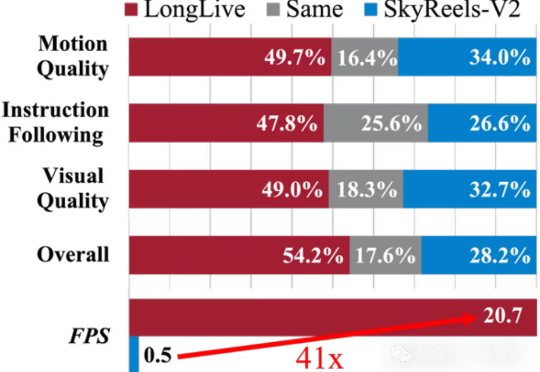
AI拍长视频不再是难事!LongLive通过实时交互生成流畅画面,解决了传统方法的卡顿、不连贯等痛点,让普通人都能轻松拍大片。无论是15秒短片还是240秒长片,画面连贯、节奏流畅,让创作变得像打字一样简单。
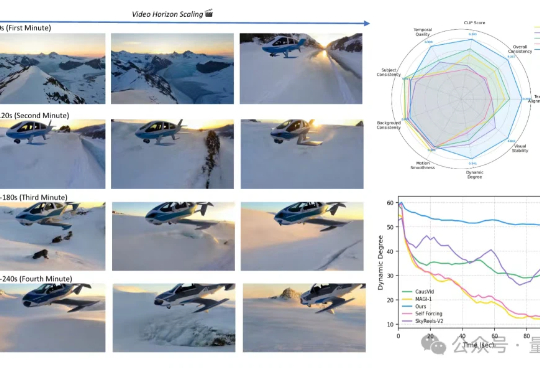
从5秒到4分钟,Sora2也做不到的分钟级长视频生成,字节做到了!这就是字节和UCLA联合提出的新方法——Self-Forcing++,无需更换模型架构或重新收集长视频数据集,就能轻松生成分钟级长视频,也不会后期画质突然变糊或卡住。