GPU 维修那些事: H100 哪里容易坏?以 Llama3 训练大模型为例
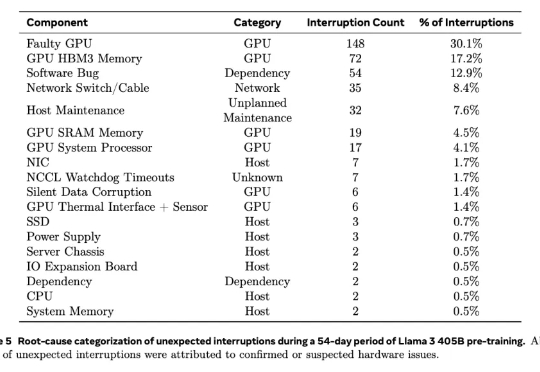
GPU 维修那些事: H100 哪里容易坏?以 Llama3 训练大模型为例根据去年2024年7月28日Meta公司在训练大模型(Llama 3)时使用“16384 个 英伟达H100 GPU 集群”的经验,该显卡在高负载、大规模集群运行环境下容易出现以下故障点:
来自主题: AI技术研报
12584 点击 2025-04-07 09:17
 搜索
搜索
根据去年2024年7月28日Meta公司在训练大模型(Llama 3)时使用“16384 个 英伟达H100 GPU 集群”的经验,该显卡在高负载、大规模集群运行环境下容易出现以下故障点:

文本到图像(Text-to-Image, T2I)生成任务近年来取得了飞速进展,其中以扩散模型(如 Stable Diffusion、DiT 等)和自回归(AR)模型为代表的方法取得了显著成果。然而,这些主流的生成模型通常依赖于超大规模的数据集和巨大的参数量,导致计算成本高昂、落地困难,难以高效地应用于实际生产环境。

再次证明,AI行业里大力出奇迹。

当我们惊叹于Deepseek的妙语连珠时,是否正目睹硅基系统对人类语言本源的复刻?那在服务器集群中奔流的矩阵运算,与人脑皮层间跳跃的神经电波,究竟共享着怎样的“语言密码”?
国内首个自研万卡集群,刚刚成功点亮!国产AI的高价门槛直接被打下来了。在百度智能云平台上,DeepSeek R1和V3的官方价格直接低至五折和三折,基本实现全网最低。

GPU万卡集群,小米下场了!摩尔线程智算集群扩展至万卡!中国移动将商用三个自主可控万卡集群......一系列标题的袭来,让笔者突然意识到,仿佛在不经意间,智能算力建设已然迈入万卡时代。

大模型浪潮下,AI与其背后的通信网络存在密不可分的联系,可以总结为Network for AI和AI for Network两层关系—— 我们用网络加速AI训练推理,通过AI手段让网络变得更加安全可靠。

基流科技是国内极少数拥有万卡集群落地经验的AI基础设施厂商,已服务包括智谱AI、商汤科技等多个头部用户。

助力北京亦庄打造人工智能应用发展新高地,将成为全国规模最大、北京首个人工智能新质社区集群。

12月26日,界面新闻独家获悉,小米正在着手搭建自己的GPU万卡集群,将对AI大模型大力投入。小米大模型团队在成立时已有6500张GPU资源。