
只用一张卡,做出了声称是100M参数以内最好的小模型?
只用一张卡,做出了声称是100M参数以内最好的小模型?近日,独立开发者 Harshal Singh 公布了一个仅有 3500 万参数的基础语言模型 BarunLM,并声称:「我预训练了世界上参数量小于 100M 的最好模型」。
来自主题: AI资讯
8400 点击 2026-08-02 13:45
 搜索
搜索
近日,独立开发者 Harshal Singh 公布了一个仅有 3500 万参数的基础语言模型 BarunLM,并声称:「我预训练了世界上参数量小于 100M 的最好模型」。
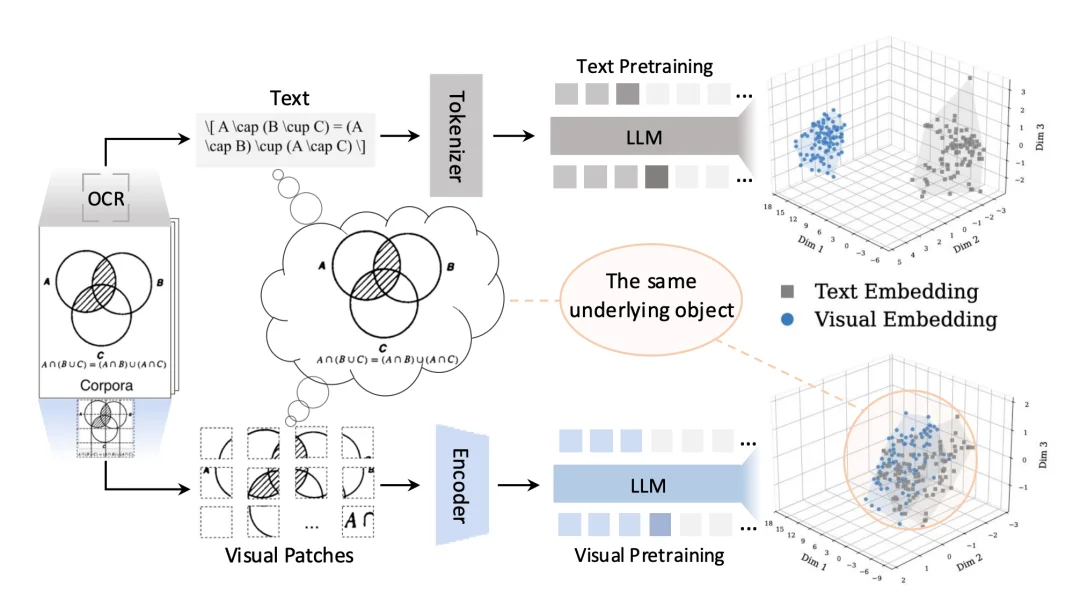
目前,这项技术已成功应用于上海人工智能实验室Intern-S2-Preview 35B/397B系列多模态大模型的预训练中,有效提升了模型的科学推理与多模态理解能力。值得一提的是,相关研发均基于国产昇腾算力平台完成,并成功实现了面向大规模预训练的深度适配与优化。

7月几天之内,中国大模型行业接连出现了两个超过2万亿参数的模型。
社会智能公司境瞳科技近日完成数千万元人民币天使轮融资,投资方包括英诺天使基金、水木清华校友种子基金、零以创投和驰星创投。这笔钱将主要用来扩大社会模拟器的规模,为社会世界模型的预训练做准备。

最近,来自 Google、哥本哈根大学、牛津大学等机构的研究者提出了 VGGRPO(Visual Geometry GRPO,收录于 ECCV 2026)。这项工作聚焦于一个核心问题:如何在不牺牲预训练模型泛化能力的前提下,高效地提升视频生成的几何一致性,并使其适用于动态场景。其核心思路是,在隐空间(latent space)中利用 4D 几何奖励,进行几何感知的视频后训练。

今天,小米刚刚扔出一颗“深水炸弹”——Xiaomi-Robotics-1具身基座模型,试图改变这一局面。Xiaomi-Robotics-1基于10万小时真实世界操作轨迹进行预训练,再用约1.1万小时跨本体数据完成后训练。据悉,这是国内首次在机器人策略模型中,对Scaling Law进行较为完整的系统验证。
蚂蚁集团旗下具身智能公司蚂蚁灵波,把这块最难的拼图拍上了桌:LingBot-VA 2.0——行业第一个具身原生预训练模型。所谓「具身原生」,一句话说清楚:不是拿现成的数字世界模型做嫁接,而是从数据、训练目标到模型架构,每一层都为「机器人在物理世界干活」而生—

蚂蚁灵波选择了后一条路:开源 LingBot-Video。这是一个面向具身智能的视频生成基座模型,也是一套专为机器人场景设计的 DiT 视频预训练范式。通用视频模型更多学习画面变化、镜头运动和视觉风格;LingBot-Video 则把重点放在动作、任务、交互和物理环境变化上,面向世界预测、动作理解和机器人训练构建视频生成基座。
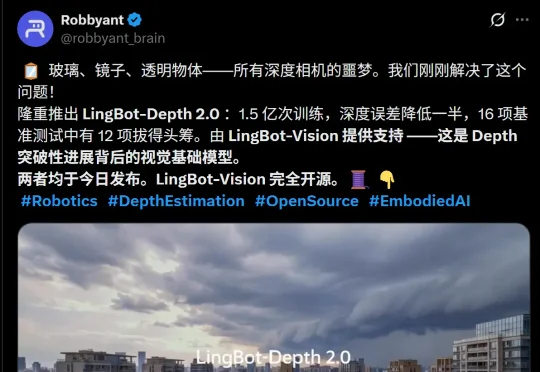
蚂蚁灵波的 LingBot-Depth 2.0,一出手就是王炸——12项世界第一!深扒内幕发现:他们竟然直接抛弃了 DINOv3,从头自研预训练基座,仅用11亿参数暴力干翻70亿大魔王,且宣布重磅开源。
Fable 5重新上线,Arena.ai的Gostev在一段视频中甩出63个3D世界,几乎都是一次成型。看了视频,就连刚加盟Anthropic预训练团队的Karpathy,也直呼没想到。