



Anthropic失业报告炸场!22-25岁年轻人被斩杀,AI淘汰75%编程
Anthropic失业报告炸场!22-25岁年轻人被斩杀,AI淘汰75%编程Anthropic最新报告炸场了:调查显示,程序员75%的任务已被AI覆盖!客服、数据录入紧随其后。更可怕的是,这还只是开始,报告预警:AI对劳动力市场的影响,是一场长达十年的「温水煮青蛙」!
来自主题:
AI技术研报
8755 点击 2026-03-06 15:15
Anthropic最新报告炸场了:调查显示,程序员75%的任务已被AI覆盖!客服、数据录入紧随其后。更可怕的是,这还只是开始,报告预警:AI对劳动力市场的影响,是一场长达十年的「温水煮青蛙」!
近期,大连理工与快手可灵团队推出了 MultiShotMaster—— 一个高度可控的多镜头视频生成框架,该论文向研究社区展示了即使在 1B 左右的小参数量级模型上,也可以实现导演级的镜头调度和连贯叙事,且支持多图参考、主体运动控制。
机器之心编辑部 近日,一款名为 StoryWorld 的 iOS 产品 Demo 在海外开发者与 3D 创作者社区引发关注:用户只需用手机摄像头对准真实空间,通过语音输入描述,即可生成 3D 角色与物

谷歌大神用6个AI智能体杀疯了。

通用人工智能公司 VAST 今日宣布完成 5000 万美元 A 轮融资。本轮融资由阿里、恒旭资本联合领投,元禾璞华、BV 百度风投、东方嘉富等跟投,形成覆盖顶级资本、产业巨头、知名战投的全方位赋能格局。

AI 本质不是工具升级,而是生产关系的重塑。

你是不是也在思考这个问题: AI大模型之间的真实差距,真的像各种榜单上表现得那样直观吗?
全球投行业每年处理超过 3.5 万亿美元的交易,但驱动这台庞大机器运转的,是数以万计每周工作超过百小时、从事着高度重复性劳动的初级分析师。Vertical Agent 开始加速很多专业领域的工作流,比如法律领域的 Harvey、医疗领域的 OpenEvidence,而在离钱最近的金融领域迟迟未能出现一款真正的统治级应用。
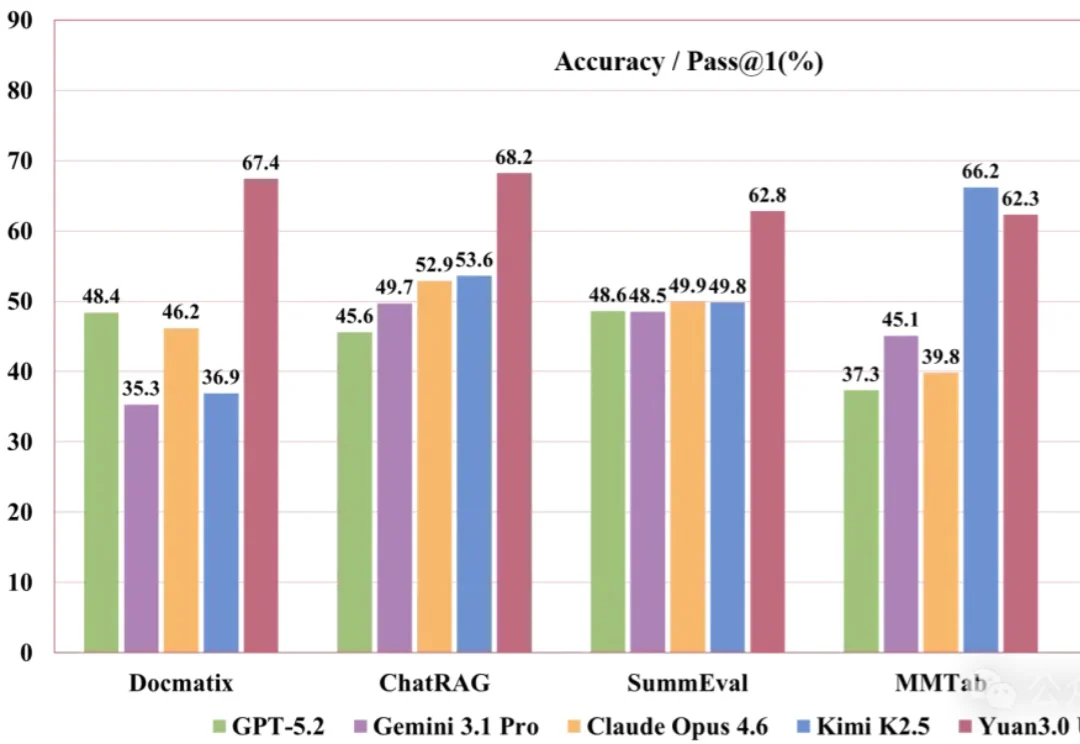
刚刚,YuanLab.ai团队正式开源发布源Yuan3.0 Ultra多模态基础大模型。

一副中国眼镜,装进了四个全球最强 AI。
昨天,Thinking Maching Lab 研究者、斯坦福大学博士生 Zitong Yang 正式完成了他的博士论文答辩,课题为「持续自我提升式 AI」(Continually self-improving AI),并且他在答辩完成后很快就放出了自己的答辩视频,从中我们可以看到他对未来 AI 发展路径的系统性探索。

昨天,计算机科学的活传奇、88 岁的图灵奖得主 Don Knuth,在自己的论文里正式感谢了一个 AI。
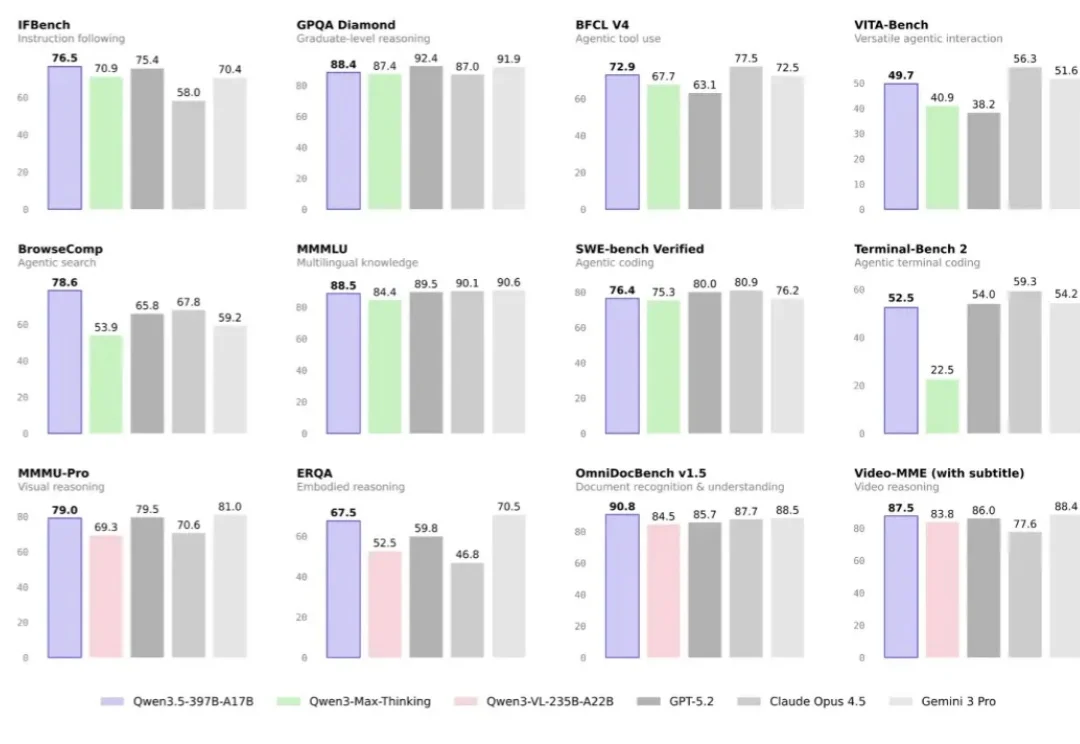
最近关于Qwen3.5还有其幕后团队,市场上的讨论沸沸扬扬,但今天我们不聊八卦,主要讲讲干货。

AI 搜索引擎正逐渐取代传统搜索入口,「问 AI」已经成为日常习惯。随着 OpenAI 宣布在 ChatGPT 中引入商业推荐,搜索与内容分发的边界正在被重新定义。在这样的环境下,你的内容能否在 AI 搜索中成为「爆款」,不再只取决于标题和流量,而是更大程度取决于 AI 本身的引用偏好。

离职的消息最沸沸扬扬的时候,Qwen 团队的核心负责人林俊旸在朋友圈发了两句话:
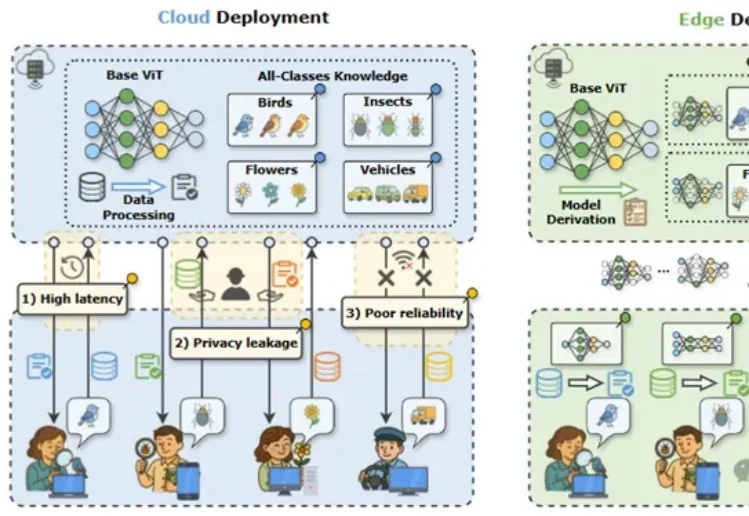
近年来,视觉大模型在自动驾驶、智慧医疗等场景中得到广泛应用,但在真实业务环境中,“大而全”的通用模型往往并不是最优选择。
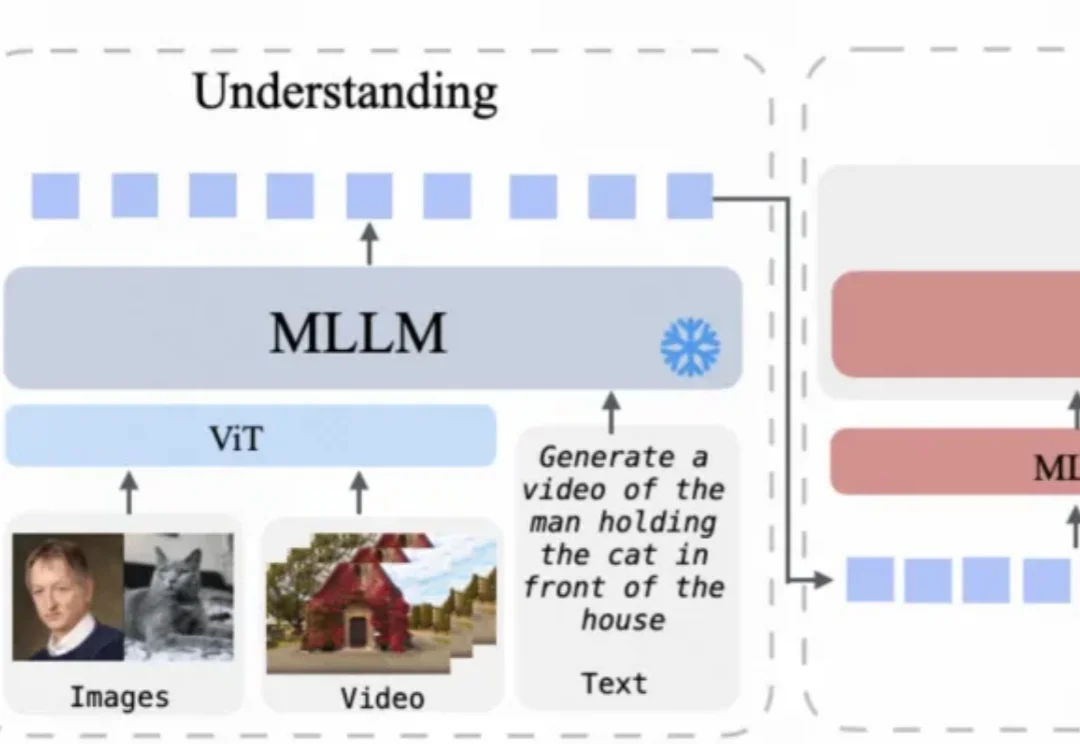
统一多模态模型在多模态内容理解与生成方面已展现出良好效果,但目前仍主要局限于图像领域。

过去,科学家观察研究细胞的工具很有限。

OpenAI深夜突袭,GPT-5.4新王炸场!一夜之间,直接粉碎了Gemini 3.1 Pro和Claude Opus 4.6的神话。这也是头一次,ChatGPT拥有真正「原生电脑使用」能力,办公效率直接拉满。而真正恐怖的地方在于,每一个维度上它都没有短板。
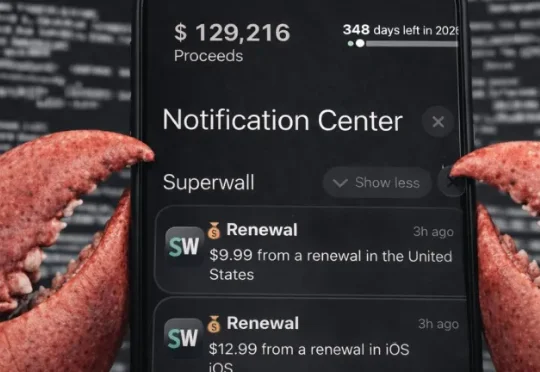
国外有一个小哥,超级个体,也就是现在国内流行的 OPC(一人公司),靠 11 个应用加 OpenClaw,每月能赚 7.3 万美元。这篇文章里,他专门拆解 OpenClaw 是怎么帮我们赚真金白银的,以及如何通过自动化把主动收入变成被动收入。
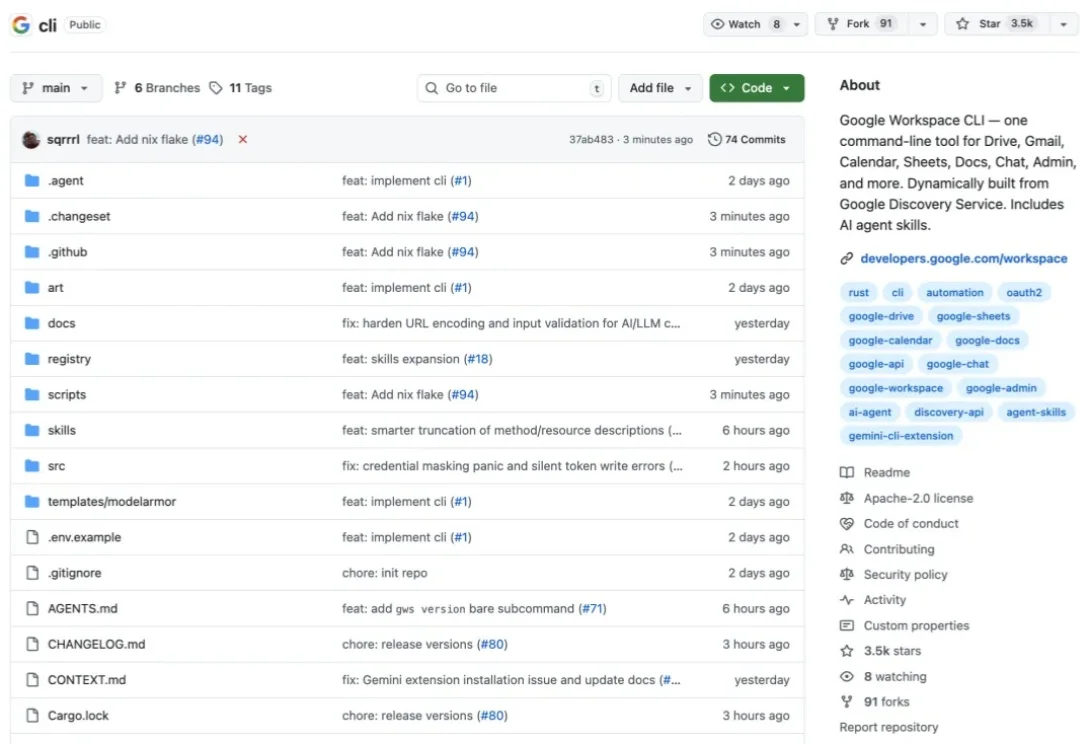
今天上午的时候,Google Workspace CLI 上线到了 GitHub,挂在 Google Workspace 的官方组织名下。我开始写这篇文章的时候,这个项目是 2700 个 Star;当我发出去的时候,重新截了个图,已经有 3500 个 Star 了

今一大早,收到了个消息: OpenAI 要上市了

大家好,我是最近一直在折腾 OpenClaw 的袋鼠帝。

OpenAI的人才地震还在继续!刚刚,前研究副总裁Max Schwarzer宣布离职,这位亲手主导o1、o3和整个GPT-5系列post-training的核心人物,选择加入Anthropic,重返一线RL研究。

资本正在加速押注具身智能的下一阶段。

一份绝密备忘录爆出,Dario Amodei彻底撕碎了OpenAI,怒喷「安全作秀」做样子给所有人看。但不可否认的是,美国务院正大面积抛弃Claude,接入GPT-4.1。

Agentic Engineering 这个词刚被大神 Karpathy 提出了 1 个月,就已经有了不少大佬现身说法如何管理你的 Agent团队了。
大家好,我是最近疯狂研究OpenClaw的袋鼠帝。

导读:近日,位于中关村的深度机智全球首次使用全新范式——人类学习,在多个国际 Benchmark 上取得 SOTA,史无前例地使用全新架构(仅使用人类第一视角数据、零真机数据)击败 Physical Intelligence 和英伟达等头部巨头二十多个百分点,并在两会开幕首日被央视报道。
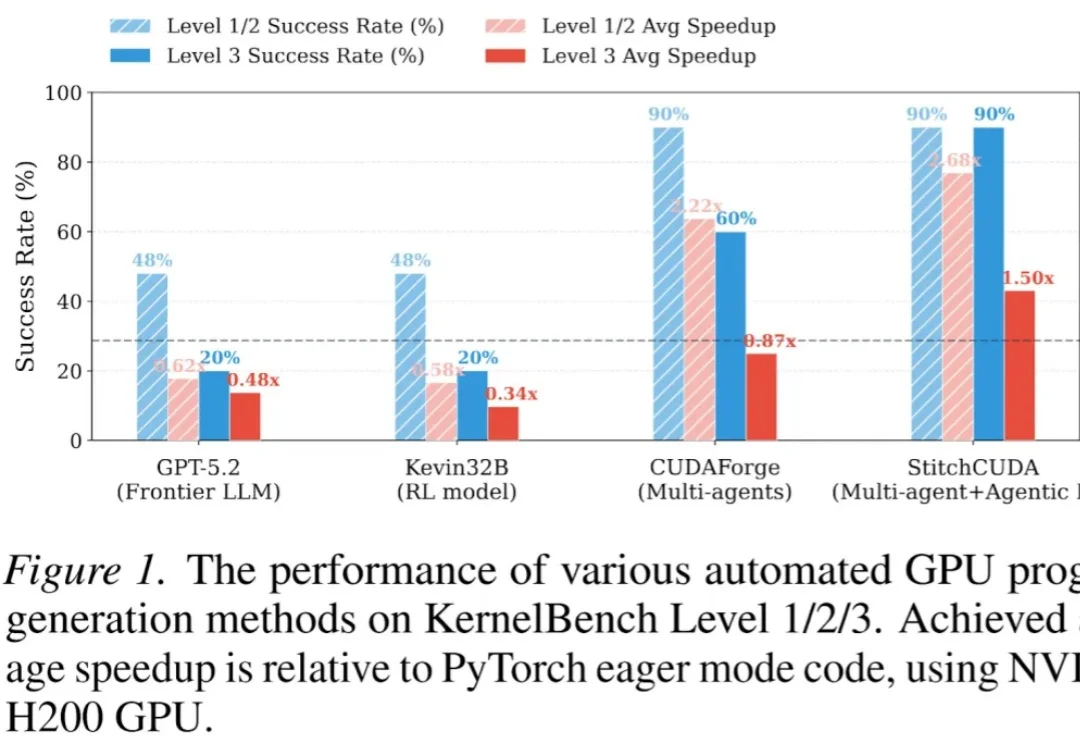
现有的 LLM 自动化 CUDA 方法大多只能优化单个 Kernel,面对完整的端到端 GPU 程序(如整个 VisionTransformer 推理)往往束手无策。

