



AI 行业最被低估的武器,是审美
AI 行业最被低估的武器,是审美AI 竞赛的节奏快得惊人,但产品层面却逐渐陷入单调重复。
来自主题:
AI资讯
9078 点击 2026-03-05 14:27
AI 竞赛的节奏快得惊人,但产品层面却逐渐陷入单调重复。
人类在创作艺术时,大脑并非一味地输出,而是在每一笔落下时都在进行着复杂的、难以言表的 “视觉优化”。

林俊旸的名字刷屏了一整天。

刚刚,YC最新创业清单点名「AI欺诈猎手」。当黑灰产开始用AI作案,防守方也在组建智能体军团——反欺诈的终局,或许不是更强风控,而是一个自带安全基因的智能体世界。
在一天的发酵之后,阿里官方正式回应了此事。今天上午,阿里巴巴 CEO 吴泳铭在内部邮件中作出了回应。邮件中提到,「公司已决定批准林俊旸同学的辞职」。

创造 IP 宇宙曾经是迪士尼和任天堂的特权,捏 Ta 正在把它变成一种个人能力。 近日,AI 原生社区捏 Ta 宣布完成超千万美金的 Pre A+ 轮融资,由九坤创投领投,BV 百度风投跟投,源码资本
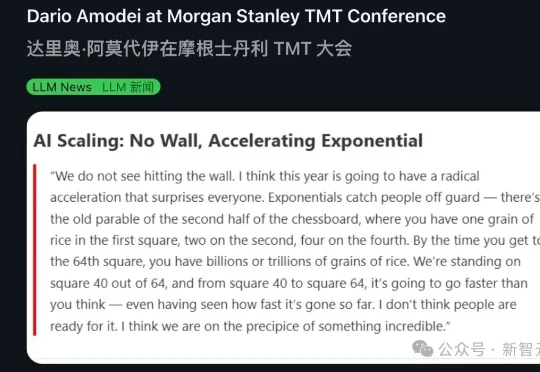
Anthropic CEO Dario Amodei在摩根士丹利会议上扔出一颗深水炸弹:Scaling Law根本没撞墙,2026年将迎来激进加速。他用棋盘稻米寓言做了个精准比喻——我们正站在第40格,前39格的所有震撼加在一起,不过是后24格的零头。这场指数级狂飙,没人准备好。

人在西班牙出差了好几天。 然后,昨天刚回北京,一回公司,就发现了一个很有趣的事。 就是内容创意组那边的小伙伴,在窗边架了一个Pocket 3。 我最开始以为,他们是在拍vlog记录公司日常。然后才发现,这玩意,他们居然说,是组里的OpenClaw的,眼睛???
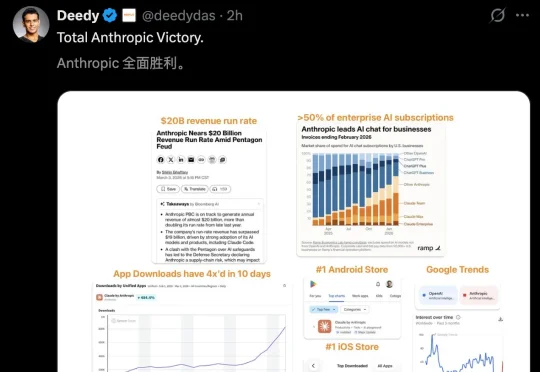
逆天了!Anthropic一路狂飙,全美市场份额飙至70%,给OpenAI留下30%的活口。更离谱的是,其年化收入近200亿美金,2周暴涨50亿。如今,所有人都在用脚投票Claude。

就在刚刚,Claude独立攻克了图论猜想,写《计算机程序设计艺术》的计算机泰斗高德纳彻底震惊了!这一次,AI在自动推理和解决创造性问题上,又达到了全新的里程碑。

又一位地平线系具身智能创业者拿到大额融资。

拼多多的AI,终于浮出水面。
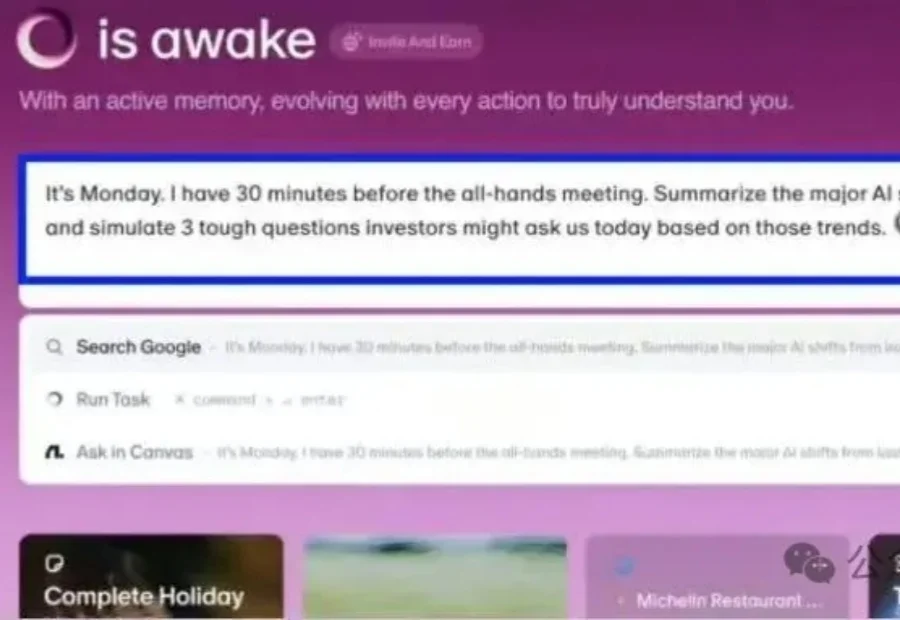
Flowith完成千万美元种子轮及种子+轮融资。

陶哲轩办公室有 6 块黑板,他说绝不放弃。但他刚带 50 个人用 AI 和代码解决了 2200 万道数学题。
前两天有个朋友问我最近在忙什么。

激进投资者艾略特投资管理公司已持有Pinterest 价值 10 亿美元股份,该公司以积极参与企业决策而闻名。该机构首次投资这家社交平台是在 2022 年。

Openclaw是不是不如骆老师轶航家的狗还需要探讨,但云端Openclaw肯定是路边一条。

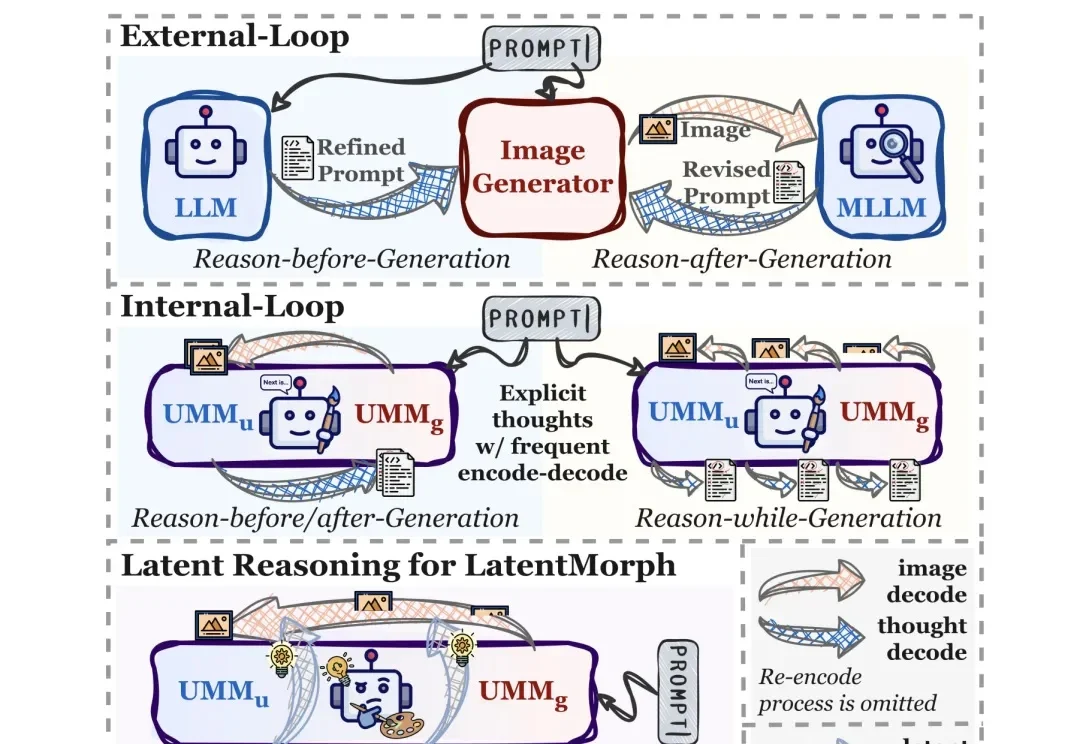
长期以来,计算机视觉领域陷入了一个 “表征(Representation)” 的执念。我们习惯设计各种精巧的 Encoder,试图将动态世界压缩成一组特征向量。然而,视频作为现实的高维投影,其熵值之高、动态之复杂,让这种试图 “定格” 的表征显得力不从心。

抖音Top 1、京东Top 1、天猫Top 2,竟是款挂件?

北京时间3月4日下午约13:00,通义实验室紧急召开了All Hands会议,阿里集团CEO吴泳铭向千问员工坦诚表示。12个小时前(北京时间3月4日凌晨0点11分),阿里千问大模型技术负责人林俊旸在X上突然宣布离职——林俊旸是阿里AI开源模型的核心推手,也是阿里最年轻的P10之一——行业一片哗然之时,Qwen的部分成员也无法接受团队灵魂人物的突然出走。

亏贼! GitHub热榜,居然被纸片人占领了—— 不是手办,是AI。你的赛博老婆,开源了。
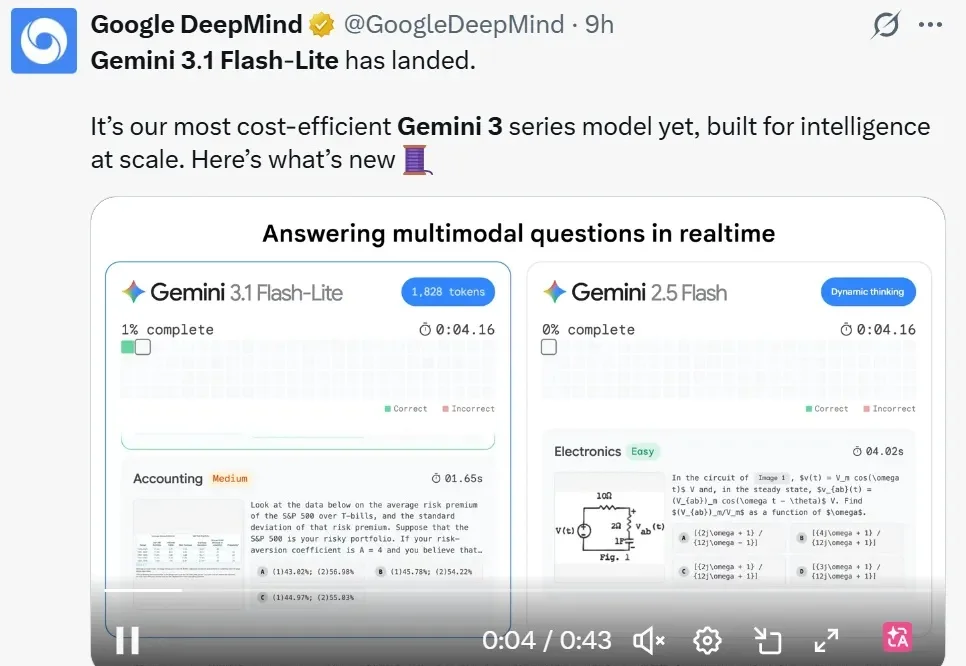
深夜,两大科技巨头谷歌和 OpenAI 硬刚起来,相继推出了新版本大模型,分别是 Gemini 3.1 Flash-Lite、GPT‑5.3 Instant。

AI打工利器杀入Windows桌面了!阿里QoderWork新版全面上线,多种Skills无限扩展。首测效果惊艳,19页硬核PPT一键支出,班味儿秒散。

在今年的MWC巴塞罗那展会上,整个科技圈都在关注“智能跃升”这个话题。

近日,NVIDIA 发布的世界 - 动作模型 DreamZero,在两项颇具代表性的机器人基准测试 RoboArena 、MolmoSpaces 上双双登顶。
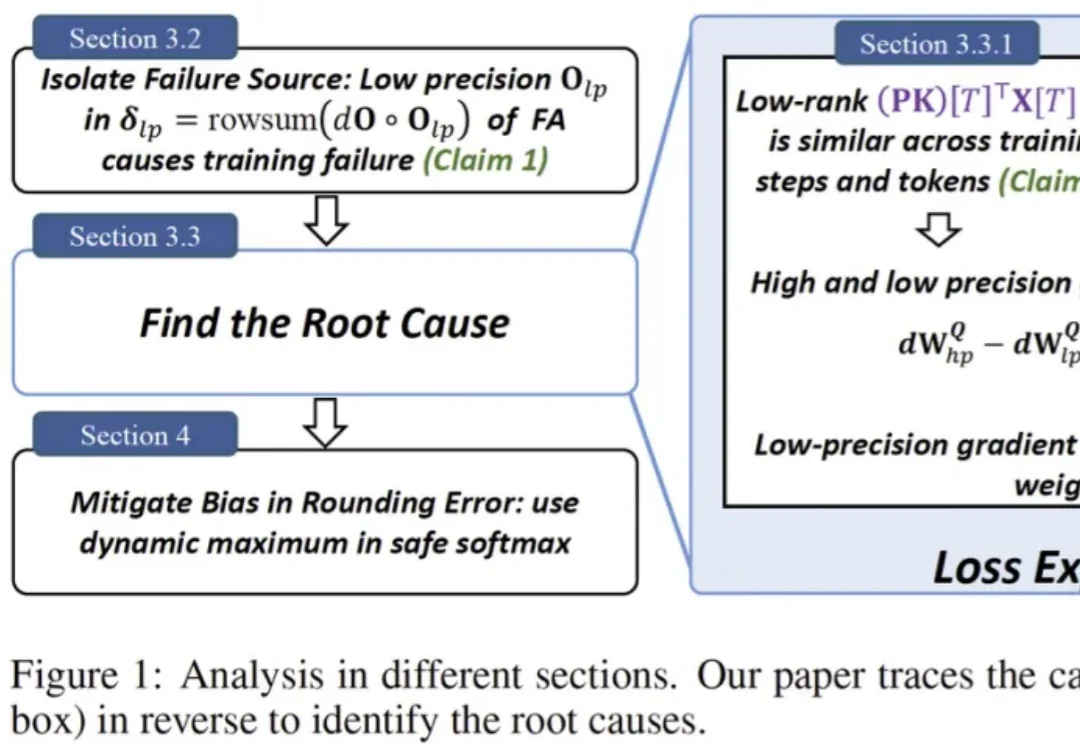
一句话总结:社区里困扰了多年的一个 “玄学” 现象终于被拆解清楚了:在 BF16 等低精度训练里,FlashAttention 不是随机出 bug,而是会在特定条件下触发有方向的数值偏置,借助注意力中涌现的相似低秩更新方向被持续放大,最终把权重谱范数和激活推到失控,导致 loss 突然爆炸。论文还给出一个几乎不改模型、只在 safe softmax 里做的极小修改,实测能显著稳定训练。

如果科研中的文献阅读、代码演进、实验验证都可以由智能体自主完成,科学发现的方式会被重新定义吗?自主科研智能体(Autonomous Research Agent)的兴起,正在把这一设想带入现实:科学家有望回归科学品味和探索源头,智能体承担科研全链路的繁琐工作,两者在人机协同的闭环中共探新的重大科研突破。
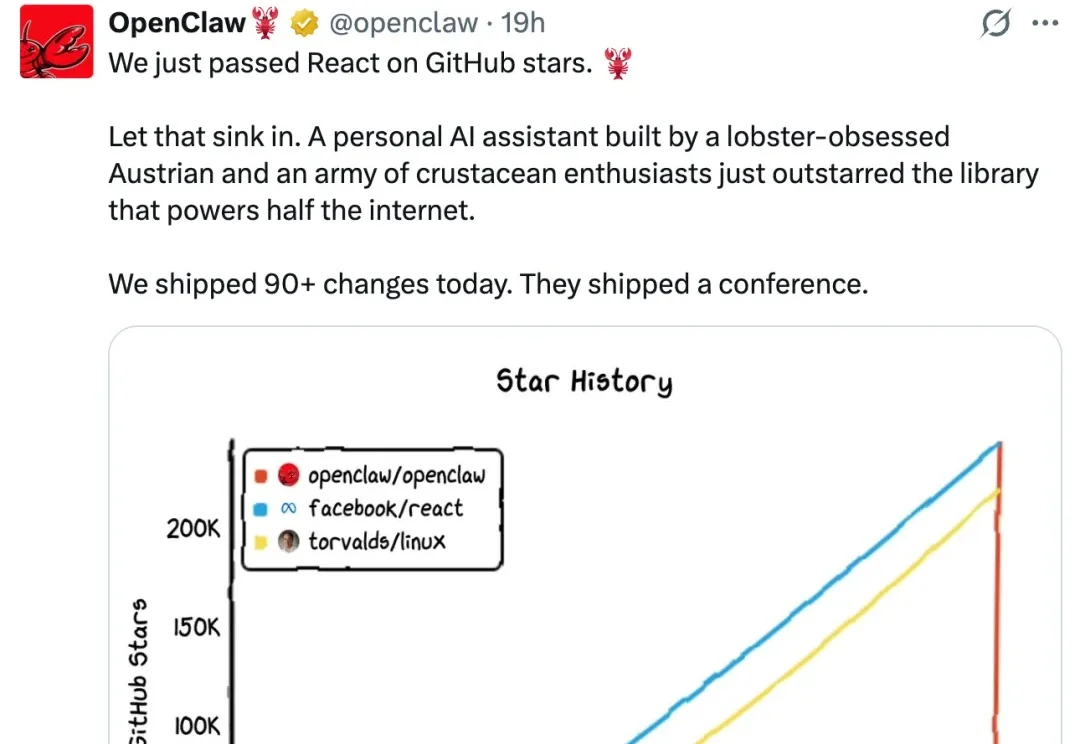
2026 开年已两个月,Agent 依然是全球最引人注目的 AI 赛道之一。OpenClaw(原 Clawbot)掀起的那波 Agent 热潮至今仍在发酵,甚至让「一人公司」概念第一次真正有了落地的可能性。

全新的具身模型空间能力评估范式 Theory of Space 突破了传统静态图文问答的局限,系统性地考察基础模型能否像人一样,在部分可观测的动态环境中,通过自主探索来构建、修正和利用空间信念。该论文已被 ICLR 2026 接收。
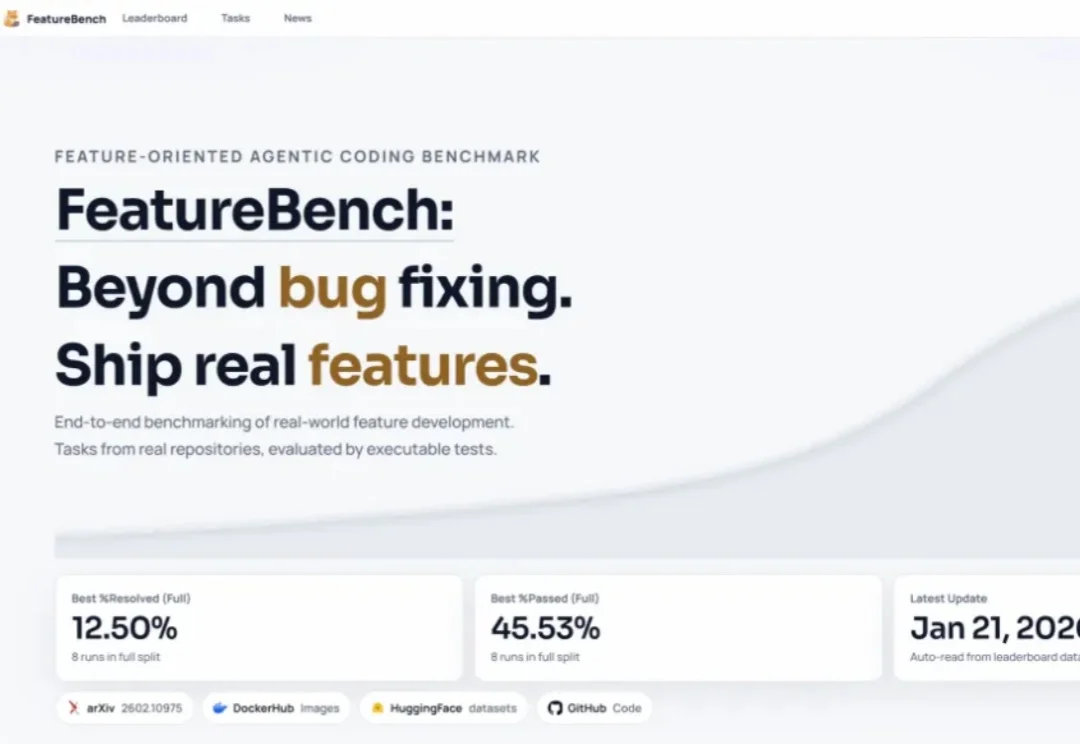
在 Princeton 发布 SWE-Bench 之后,用真实世界代码仓库+可执行测试评测大模型软件工程能力,几乎已成为学术界与工业界的共识。围绕 SWE issue 的评测范式迅速发展,也催生了一系列 SWE 系列 benchmark,在刻画模型 bug 修复能力方面发挥了重要作用。

