不止修bug:Agentic Coding评测走向复杂feature交付新阶段
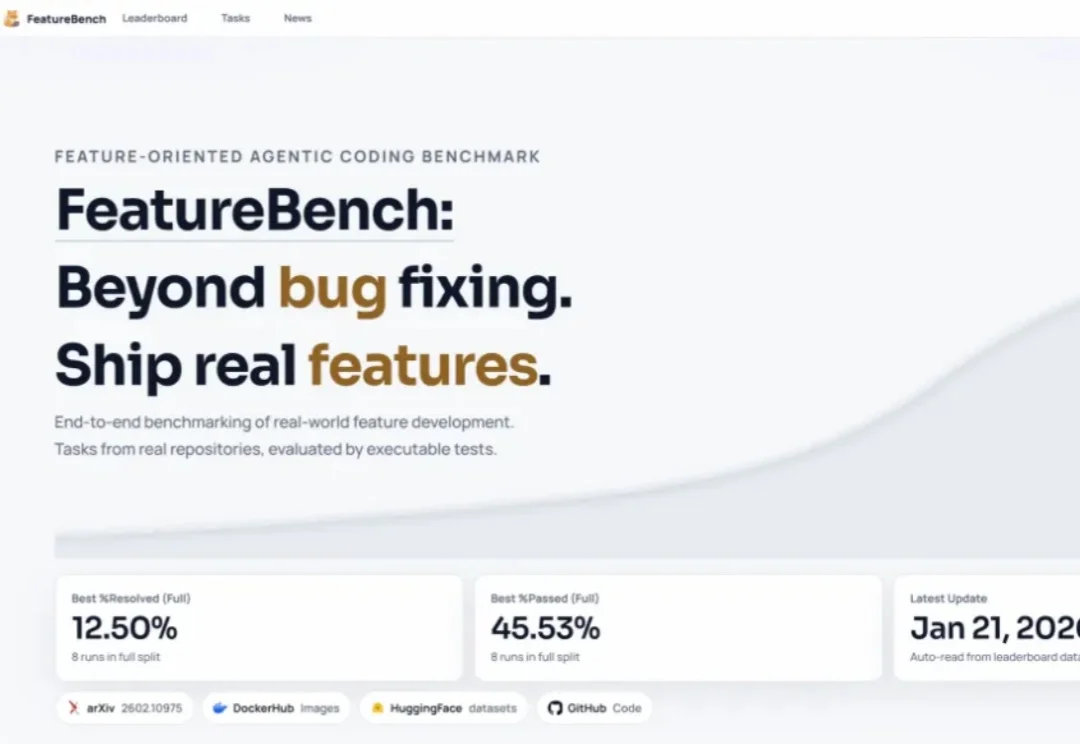
不止修bug:Agentic Coding评测走向复杂feature交付新阶段在 Princeton 发布 SWE-Bench 之后,用真实世界代码仓库+可执行测试评测大模型软件工程能力,几乎已成为学术界与工业界的共识。围绕 SWE issue 的评测范式迅速发展,也催生了一系列 SWE 系列 benchmark,在刻画模型 bug 修复能力方面发挥了重要作用。
来自主题:
AI技术研报
7470 点击 2026-03-04 13:44