



MIT天才博士刚毕业,就被前OpenAI CTO抢走!年薪或300万起步
MIT天才博士刚毕业,就被前OpenAI CTO抢走!年薪或300万起步MIT天才博士一毕业,火速加盟OpenAI前CTO初创!最近,肖光烜(Guangxuan Xiao)在社交媒体官宣,刚刚完成了MIT博士学位。下一步,他将加入Thinking Machines,专注于大模型预训练的工作。
来自主题:
AI资讯
8908 点击 2026-01-09 14:42
MIT天才博士一毕业,火速加盟OpenAI前CTO初创!最近,肖光烜(Guangxuan Xiao)在社交媒体官宣,刚刚完成了MIT博士学位。下一步,他将加入Thinking Machines,专注于大模型预训练的工作。

联想给出的公式是,混合AI=个人智能+企业智能+公共智能。这种模式下,AI智能体应用不再依赖于单一的云端模型,而是云端大模型与本地定制化小模型的深度融合。
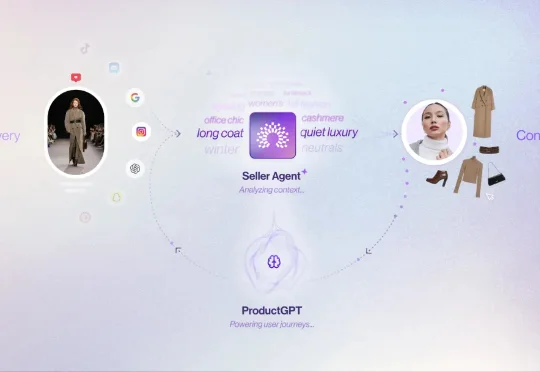
Spangle 是一家由前 Bolt 首席执行官 Maju Kuruvilla 创办的 AI 电子商务初创公司,已在新一轮融资中筹集了 1500 万美元,公司投后估值达 1 亿美元。本轮完全股权性质的A 轮融资由 NewRoad Capital Partners 领投。一年多前,这家总部位于西雅图的初创企业以 3000 万美元投前估值完成了 600 万美元的种子轮融资 。
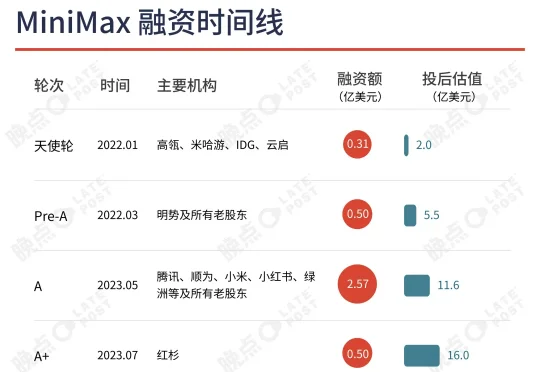
在今天(1 月 9 日)早上前往港交所敲钟前,MiniMax 创始人闫俊杰对《晚点 LatePost》分享了他此刻的想法:希望我们后续能有机会对整个行业智能水平的提升做出更大的贡献。我们初步探索了一条纯草根 AI 创业的路径,尽管后面还是非常挑战,如果能对 AI 创新创业生态的发展有启发我们会感到很光荣。
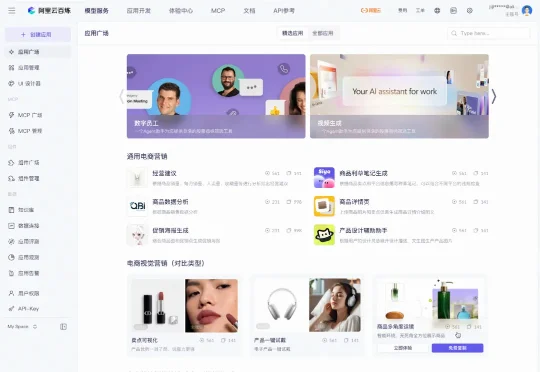
百炼升级了其提出的「1+2+N」的蓝图:其中最底层的 1 是模型与云服务,中间层的 2 是高代码、低代码的开发范式,在最上层的 N 则是面向不同任务的开发组件。这套能力覆盖了生产级智能体构建的全生命周期。
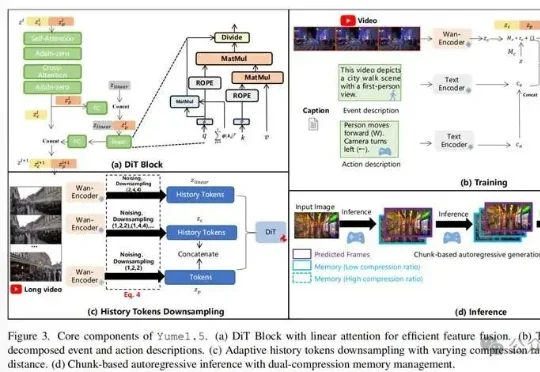
上海AI Lab联合多家机构开源的Yume1.5,针对这一核心难题提出了时空信道联合建模(TSCM),在长视频生成中实现了近似恒定计算成本的全局记忆访问。
谭老师我, 每年会找几个看似冷门, 其实值得深挖的选题, 啥意义,没苦硬吃? 这是拉开认知差距的办法。 科技这行,赚小钱靠信息差, 抓大钱靠认知差, 这篇灵感来源于, 有几位搞AI底层技术的朋友常说,

CaveAgent的核心思想很简单:与其让LLM费力地去“读”数据的文本快照,不如给它一个如果不手动重启、变量就永远“活着”的 Jupyter Kernel。这项由香港科技大学(HKUST)领衔的研究,为我们展示了一种“Code as Action, State as Memory”的全新可能性。它解决了所有开发过复杂Agent的工程师最头疼的多轮对话中的“失忆”与“漂移”问题。
如果你是 Claude Code 的用户,你可能会注意到,它最近有个重要的版本更新,从节前的 2.0.76 更新到了 2.1.0。而且,这次的日志,你得往下翻好几屏。

Meta收购Manus,或许还未到尘埃落定之际。据商务部新闻发言人何亚东透露,商务部将会同相关部门对此项收购与出口管制、技术进出口、对外投资等相关法律法规的一致性开展评估调查。

出走5年,估值翻倍!曾被嘲笑「太保守」的Anthropic,正凭3500亿美元身价硬刚OpenAI。看理想主义者如何靠极致安全与Coding神技,在ARR激增的复仇路上,终结Sam Altman的霸权!

在 2026 年的 CES 全球消费电子展上,AI 硬件无疑是不可忽视的一支—— 小至能根据指令作画的 AI 画框,大到能叠衣服的家务机器人......AI 已经无处不在。
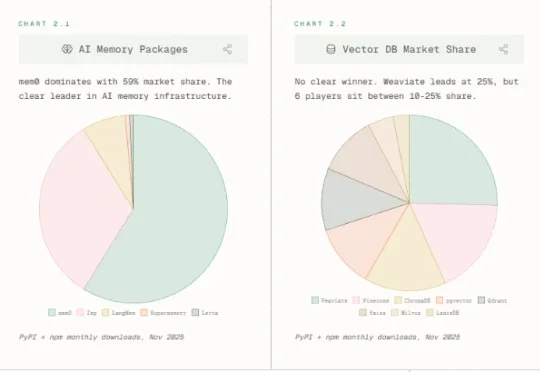
想知道硅谷的程序员怎么使用AI编程,被2000家公司使用的AI代码审查智能体Greptile基于每月用AI审核的的十亿行代码,发布了AI编程年度报告,揭示了使用AI编程后带来的生产率提升,但对此程序员们却无法感同身受。
面对一张精美的画作,你的第一反应是什么?
2026 年,基模会不会吃掉所有应用场景?

谁能想到,AI界最权威的大模型排行榜,竟然是个彻头彻尾的骗局?最近,2025年底的一篇名为《LMArena is a cancer on AI》的文章被翻了出来。登上了Hacker News的首页,引起轩然大波!
今日,小米前高管王腾在个人微博发文透露创业新动态。据其所述,从小米离开后开始筹备创业,最近新公司已经成立,公司取名为“今日宜休”,目标是通过研发睡眠健康相关的产品。谈及入局“AI+健康睡眠”领域,王腾认为,新时代下AI大模型发展迅速,让很多产品的体验能大幅提升。

借鉴人类联想记忆,嵌套学习让AI在运行中构建抽象结构,超越Transformer的局限。谷歌团队强调:优化器与架构互为上下文,协同进化才能实现真正持续学习。这篇论文或成经典,开启AI从被动训练到主动进化的大门。

“我们只交付100%可以复现的轨迹。”

针对端到端全模态大模型(OmniLLMs)在跨模态对齐和细粒度理解上的痛点,浙江大学、西湖大学、蚂蚁集团联合提出 OmniAgent。这是一种基于「音频引导」的主动感知 Agent,通过「思考 - 行动 - 观察 - 反思」闭环,实现了从被动响应到主动探询的范式转变。

最近一年,互联网上各种为RAG赛博哭坟的帖子不胜枚举。

提起“AI战胜人类”,很多人第一反应是1997年IBM的“深蓝”击败国际象棋世界冠军卡斯帕罗夫。那场人机大战轰动全球,被视为人工智能的里程碑。

刚刚,MiniMax(0100.HK)正式登陆港交所上市,发行价为165港元(约合人民币147.9元),开盘价为235.4港元(约合人民币211.0元),较发行价上涨42.67%,目前已涨到270.8港元,总市值约为827亿港元。

抛开产品体验不谈的话,Rokid无疑是国内AR眼镜的先行者,他们用眼镜这个不可能三角最难平衡的硬件形态,硬是推出了10几个功能,客观上也推进了全产业链的发展。

在上期内容发布后 有很多小伙伴都反馈很好用 NotebookLM改不了细节?提示词 V2.0 生成既有质感,又能随意修改文字的完美 PPT

是你的、是我的、是每个人的黄金时代。

前端生态最具影响力的开源项目之一 Tailwind CSS,正经历一场罕见的生存压力测试。
10 年前,我人生第一次走进腾讯大厦的时候,无数次憧憬着可以和一群有趣的 Founder,出入在高端写字楼,有喝不完的咖啡,拿不完的年终奖和期权。但是现在我厌倦甚至讨厌这种精英主义的虚伪感,如今这些东西都有了,身处其中的人却在异化、在变得没那么快乐。

今天,Qwen 家族新成员+2,我们正式发布 Qwen3-VL-Embedding 和 Qwen3-VL-Reranker 模型系列,这两个模型基于 Qwen3-VL 构建,专为多模态信息检索与跨模态理解设计,为图文、视频等混合内容的理解与检索提供统一、高效的解决方案。
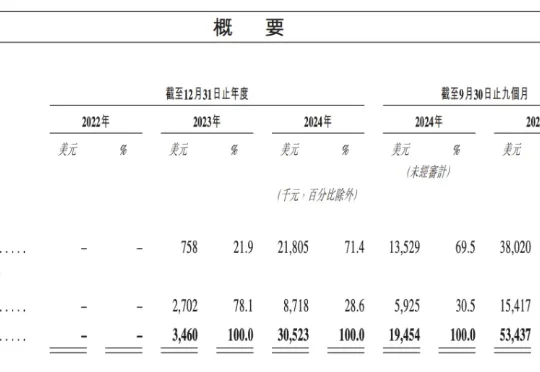
即将于 1 月 9 日敲钟上市的大模型公司 MiniMax,创下近年来港股 IPO 机构认购历史记录。此次参与 MiniMaxIPO 认购的机构超过 460 家,超额认购达 70 多倍。此前的认购记录属于宁德时代,其在 2025 年登陆港股市场时,剔除基石后超额认购 30 倍。

