# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
上下文学习(In-Context Learning, ICL)、few-shot,经常看我文章的朋友几乎没有人不知道这些概念,给模型几个例子(Demos),它就能更好地理解我们的意图。但问题来了,当您精心挑选了例子、优化了顺序,结果模型的表现还是像开“盲盒”一样时……有没有可能,问题出在一个我们谁都没太在意的地方,这些例子,到底应该放在Prompt的哪个位置?

这听起来可能有点“玄”,但来自马里兰大学的研究者们通过一篇扎实的论文,把这个“玄学”问题彻底变成了“科学”。他们发现,仅仅是挪动一下示例在Prompt里的位置,就能让模型的准确率上蹿下跳,甚至让近一半的答案“反复横跳”。

这篇研究的核心,就是提出了一个名为DPP偏见(Demos' Position in Prompt bias)的概念。它指的就是,示例(Demos)在Prompt中的物理位置,会对模型的性能产生系统性的、可预测的影响。
以前我们总觉得,只要信息给全了,模型那么聪明,总能自己找到重点。但研究者发现,AI其实像个有点“一根筋”的学生,你把“课堂笔记”(示例)放在课本的开头让他预习,还是放在习题册的最后让他参考,他学到的东西还真不一样。这个问题直接关系到AI产品的稳定性和可复现性,非常重要。
为了确保他们的发现不是巧合,研究者设计了一套非常严谨的实验流程,核心就是“控制变量”。他们保持示例的内容和内部顺序完全不变,只改变它们在Prompt中出现的位置。
研究者在一个我们最常用的“系统指令-用户对话”模板中,定义了四种泾渭分明的位置,覆盖了绝大多数应用场景:
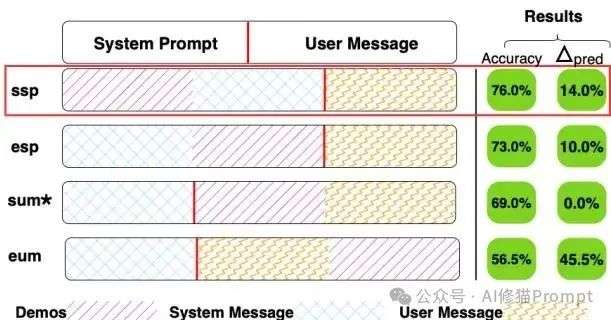
研究者定义的四种示例位置(DPP)示意图,右侧展示了QWEN-1.5B模型在不同位置下的准确率差异,波动非常明显。
关于System和user我最早在2023年就写过,之后还写过很多篇,感兴趣您可以看一下《别找了,第一性原理下的Prompt=SYSTEM信息+USER信息,来自对丹尼尔·卡尼曼的《思考,快与慢》的反思》

为了从不同维度衡量位置偏见,研究者专门设计了两个指标,不仅看“对不对”,更看“稳不稳”。
研究者们这次的实验覆盖了四大主流模型家族(QWEN, LLAMA3, MISTRAL, COHERE)的10个不同规模的模型,以及八种主流的NLP任务(包括分类、问答、摘要和推理)。如此大范围的测试,让他们的结论异常坚实。
结果显示,一个非常普遍的规律是“先入为主”。
以论文中的这个“AG News新闻文章分类”任务和sspStart of System Prompt模版为例,在DEMOS_PLACEHOLDER,研究者会填入为AG News任务准备的5个分类示例。SYSTEM_PLACEHOLDER,填入AG News的任务指令原型(“你是一个文本分类助手等等”)。在QUESTION_PLACEHOLDER,填入一篇从测试集中抽取的、需要进行分类的新闻文章。
<system>
Use the demos below as examples on how to answer the question
<DEMOS_PLACEHOLDER>
<SYSTEM_PLACEHOLDER>
<end_of_system>
<user>
<QUESTION_PLACEHOLDER>
<end_of_user>
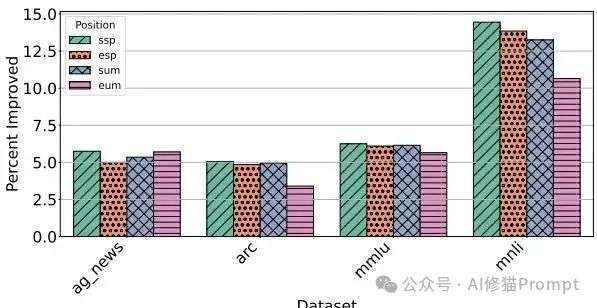
四个位置相对于“零样本”的准确率变化,数据在所有模型上进行了平均。可以看到,将示例放在开头的ssp位置,性能提升最为显著。
您可能会觉得,这是不是小模型的毛病?模型大了,数据量上来了,应该就不会这么敏感了吧?
研究者发现,确实存在一个“规模缩放定律”(Scaling Law)。随着模型参数从1.5B增长到72B,由位置变化引起的性能波动的确会减小,大模型显得更加“鲁棒”。但是,请注意,它们远非免疫。尤其是在处理像数学推理(GSM8K)这类需要严谨逻辑的复杂任务时,即便是最大的模型,其预测结果依然会因为例子的位置而大幅摇摆。
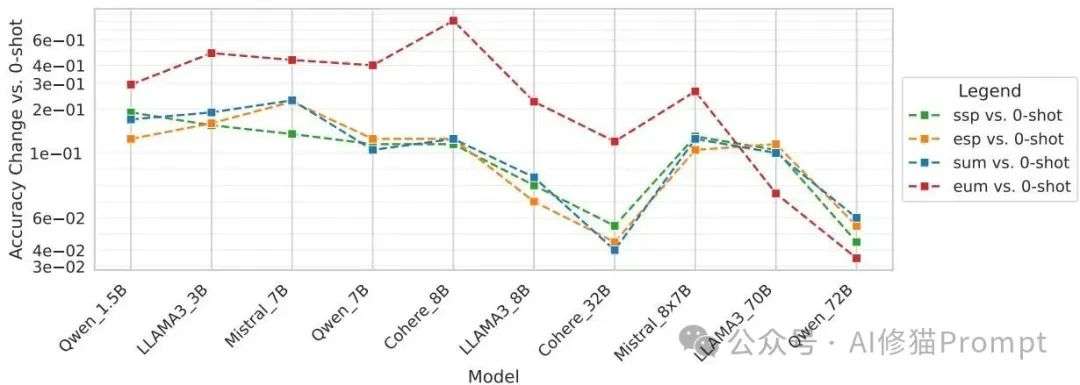
MMLU任务上的规模缩放效应。可以看到,随着模型规模增大(从左到右),由不同位置(不同颜色的线)引起的预测变化率(上图)和准确率波动(下图)都呈现出下降趋势,但并未完全消失。
这可能是对提示词工程师最有冲击力的一个发现:不存在一个对所有模型和任务都通用的最佳示例位置。
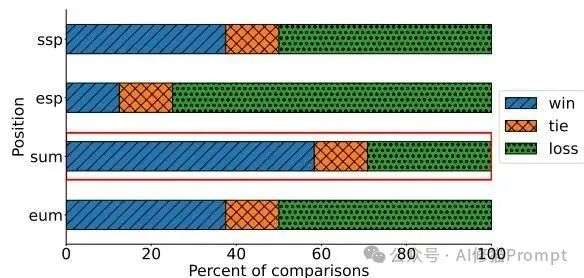
LLAMA3-70B在所有任务上的“胜-平-负”分析。这张图清晰地显示,对于这个大模型而言,sum位置(用户消息开头)胜出的任务最多,这与其他小模型的偏好形成了鲜明对比。
这个发现给我们的启示是:别再盲目地套用网上流传的或官方文档里给的所谓“最佳Prompt模板”了。您正在使用的模型,很可能有着它自己独特的“脾气”和“偏好”。
那么,这种偏见到底是怎么来的呢?研究者提出了两个很有说服力的解释:
1.架构的“原罪”:我们现在用的主流大模型,基本都是基于Transformer的因果解码器(causal-decoder LLMs) ,并且采用自回归的方式进行训练 。这意味着它在生成内容时,是一个词一个词往后蹦的,前面的内容会通过一种名为“自回归掩码(autoregressive masking)”的机制,极大地影响后面所有内容的生成 。更深度的机理解释工作发现,模型中存在一种被称为“归纳头(induction heads)”的特殊注意力机制 ,它会不成比例地将注意力集中在序列早期的Token上 。这使得模型天然就更关注它先看到的信息,就像人的“第一印象”一样,一旦形成就很难被后来信息完全覆盖。当小帅和女神的第一次约会表现得很下头或性缩力满满,今后即便再好大概也于事无补。
2.训练数据的“惯性”:用于训练这些模型的“指令微调(instruction-tuning)”数据集,本身在格式上可能就存在一些约定俗成的模式(比如,例子总是放在某个固定区域)。模型在学习海量数据的过程中,不知不觉地把这种“格式偏好”也当成了一条隐性规则给学了进去 ,从而在面对不同结构时,表现出我们观察到的位置偏见。
所以,下次当您感觉某个Prompt的效果总也上不去时,除了绞尽脑汁修改措辞、调整示例内容,不妨试试一个最简单、成本最低的操作把您的示例(Demos)换个位置。也许这个不经意的举动,就能让您的模型性能豁然开朗。这个研究提醒我们,Prompt工程的深度,远比我们想象的要深,它的物理结构本身,就是一个值得我们去精细打磨的关键参数。
文章来自于微信公众号“AI修猫Prompt”。



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
