# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
Token危机真的要解除了吗?
最新研究发现,在token数量受限的情况下,扩散语言模型的数据潜力可达自回归模型的三倍多。
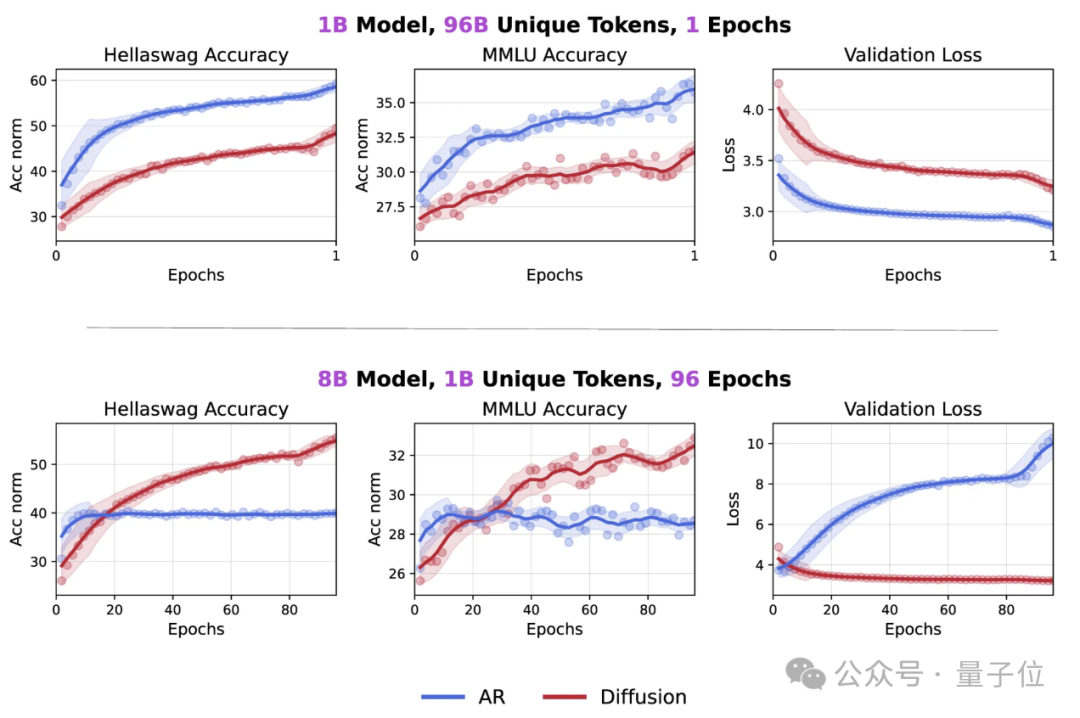
不仅如此,一个参数规模为1B的扩散模型,用1B tokens进行480个周期的训练,就在HellaSwag和MMLU基准上分别取得56%和33%的准确率,且未使用任何技巧或数据筛选。
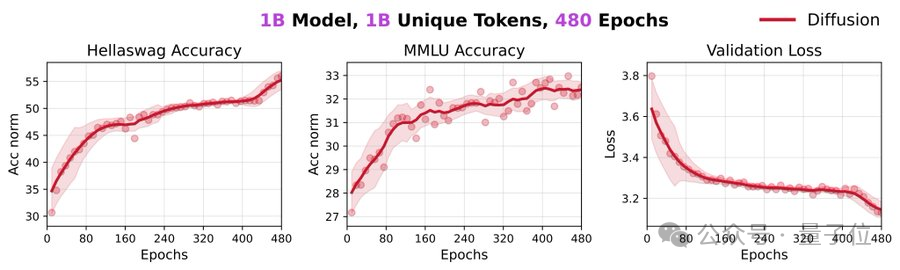
更令人惊讶的是,即使是在如此极端的重复下,模型都未出现性能饱和,这表明此模型甚至还可以从这1B数据中挖掘出更多有用信息。
论文一作Jinjie Ni在x上详细介绍了其团队的研究结论和方法。

下面让我们详细了解更多细节。
扩散语言模型之所以具备超强的数据学习能力,主要有两个原因:
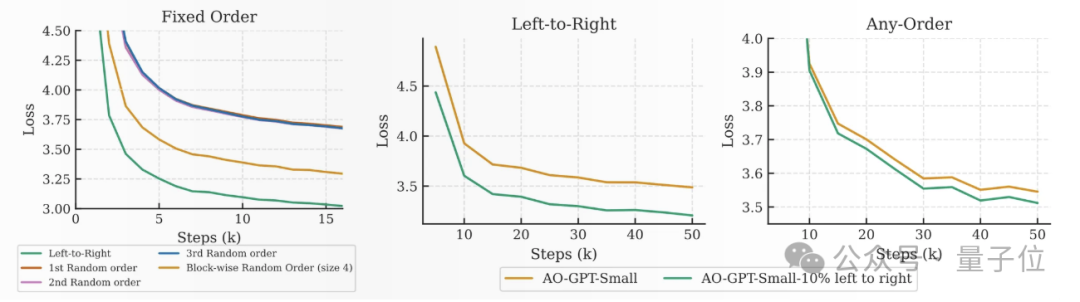
1)扩散目标和双向注意力机制使其能够进行双向建模,更充分地挖掘网络数据中的信息,,而这些数据并非完全因果关系。
简单来说,传统自回归语言模型只能从前向上下文预测,存在严格的因果限制,这限制了模型对语言和其他非因果数据(如代码、生物序列等)中复杂模式的捕捉能力。
扩散语言模型通过支持双向建模,打破了这种因果限制,更全面地利用数据,从而提升了学习效果。
2)其计算密度极高。扩散模型在训练和推理过程中投入了更多计算资源(FLOPs),通过多次处理数据和迭代优化预测,提高了计算密度和模型性能。
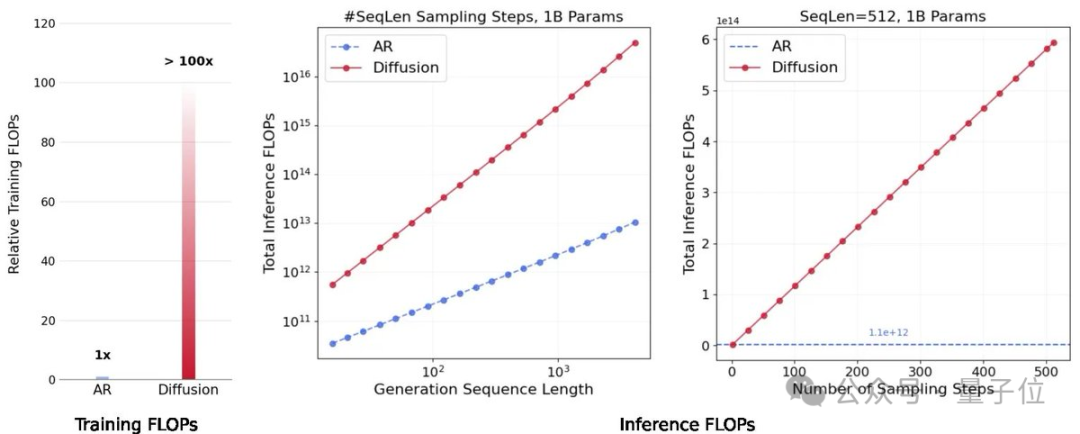
相比之下,自回归模型优先考虑计算效率,而非数据潜力。它们的transformer设计采用了教师强制(teacher forcing)和因果掩码(causal masking),虽然能最大化GPU的利用率,但也限制了模型的建模能力。
随着计算成本下降,数据的可获得性成为关键瓶颈——这正是研究团队开展DLMs研究的出发点。
此外,扩散目标明确要求在预训练时,对每个数据点进行多种掩码比例和组合的扰动,以便更有效地训练并获得更准确的期望估计,这也解释了为什么多次重复使用数据能带来显著的提升。
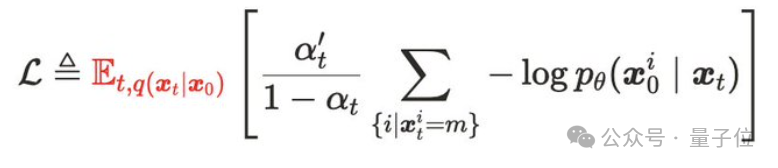
尽管扩散语言模型对数据重复具有一定的鲁棒性,但当训练足够多的周期后,它们也会出现过拟合现象。
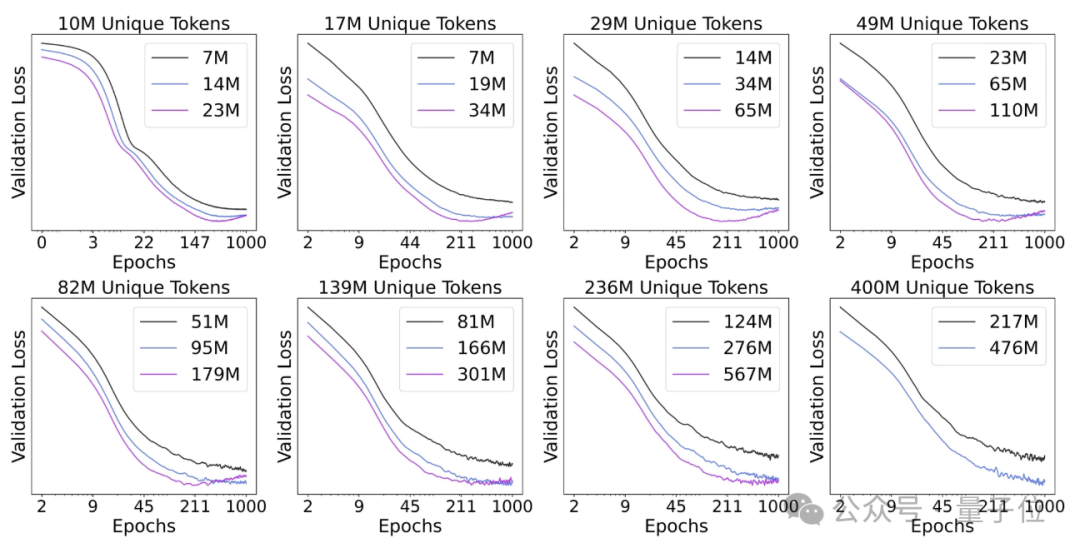
具体来说,研究团队观察到模型开始过拟合的训练周期数与独特数据量呈正相关,与模型规模呈负相关。
换句话说,独特数据量越大,过拟合出现得越晚;而模型规模越大,过拟合则越早发生。
除了得出上述结论,研究者还发现当模型在预训练验证集上“过拟合”时,它们在下游任务中的性能不一定会下降,反而可能会一直上升,直到训练结束。
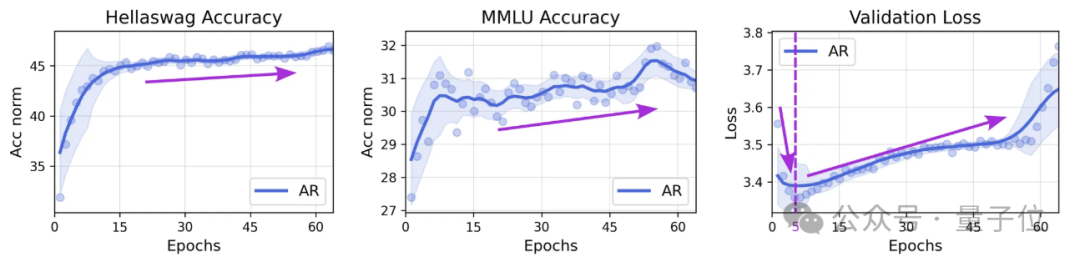
出现这种现象的原因在于,验证损失是是以绝对的交叉熵损失(负对数似然,NLL)来衡量的,而下游任务的准确率基于比较不同选项的相对交叉熵损失。
因此, 绝对NLL值的变化并不一定转化为其相对顺序的变化 。
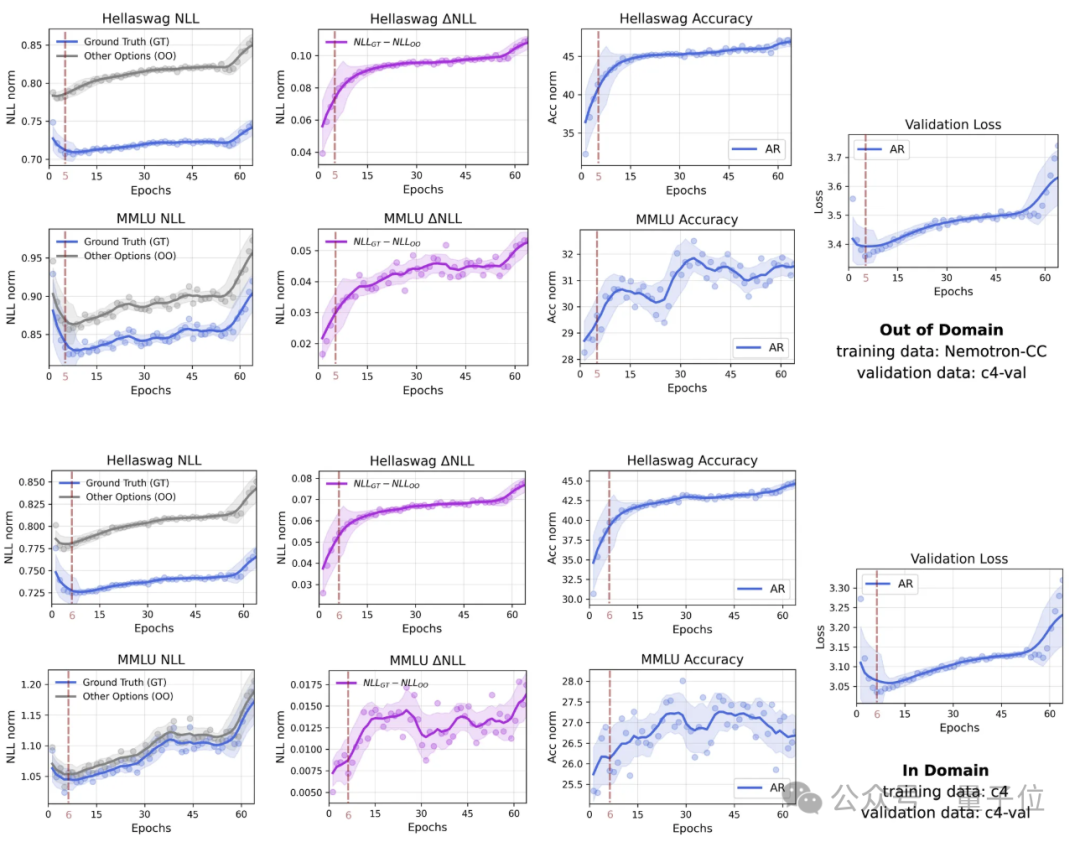
上图中,研究者还展示了在64个训练周期内,一个参数规模为1B的自回归模型在使用1.5B tokens进行训练时,其多选评测中真实答案与其他选项的平均负对数似然(NLL)、以及它们之间差值(△NLL)的变化情况。
值得注意的是,即使在第一个验证检查点(训练3600步后),模型对真实答案的NLL值已经显著较低(即概率较高),这表明模型早期就具备优先为正确选项分配更高logits的能力。
然而,随着训练的继续,模型开始出现过拟合,导致真实答案和错误选项的NLL值均有所上升。
但有趣的是,即便出现了“过拟合”,真实答案与其他选项之间的NLL差距依然持续扩大,表明模型的判别能力在验证损失上升的情况下仍在不断提升。
一个合理的解释是,模型反复接触有限的训练数据后,可能会对某些文本片段过于自信,从而放大了错误预测的NLL值。
然而,真实答案与其他选项之间的相对NLL差距不断拉大,表明模型的判别能力仍在持续提升。
类似的道理也适用于生成式评估(即在单个token级别进行选择)。因此,研究者推测,模型对非关键token的错误过度自信,对整体任务性能影响有限。
之后,团队将在研究中使用更大模型和更多独特数据,进一步验证这一假设。

Jinjie Ni,本科毕业于西北工业大学电气工程专业,博士毕业于新加坡南洋理工大学计算机科学专业。
曾于2019年任哈佛大学应用计算科学研究所助理,2022年任阿里巴巴达摩院研究实习生。现任新加坡国立大学SEA AI研究员,与Michael Shieh教授一起工作。

Michael Shieh(谢其哲),本科就读于上海交通大学ACM班,硕士和博士均毕业于卡内基梅隆大学。
现任新加坡国立大学计算机科学系助理教授,他曾在谷歌DeepMind与Quoc Le和Thang Luong合作过两年。
参考链接:
[1]https://jinjieni.notion.site/Diffusion-Language-Models-are-Super-Data-Learners-239d8f03a866800ab196e49928c019ac
[2]https://threadreaderapp.com/thread/1954177095435014533.html?utm_source=chatgpt.com
文章来自于微信公众号“量子位”,作者是“时令”。


