# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
精心设计了一个由多个AI智能体组成的强大团队,期望它们能像人类专家一样协作解决复杂问题,但却发现这个团队聊着聊着就“精神涣散”,忘记了最初的目标,甚至连彼此的角色都开始混乱。这并非您的设计失误,而是当前Multi-Agent System普遍面临的一个底层困境“集体失忆”,而来自艾伦·图灵研究所、伦敦国王学院等机构的研究者们,最近的一篇论文可能解决了这个问题

这个问题的根源,其实在于LLM的“上下文窗口”,您可以把它想象成一个会议室里大小有限的白板,一旦写满了新的讨论,就必须擦掉最早的内容才能继续。在只有一个Agent(Single-Agent)时这个问题还不算致命,可当一群Agent(Multi-Agent)开会时,信息量暴增,白板很快就会被写满并反复擦除,导致关键的初始需求、中间结论被无情地遗忘,整个团队的协作也就失去了根基。虽然业界尝试过RAG(检索增强生成)或共享记忆库等方法,但这又像给所有与会专家发了一份完全相同的、由秘书统一整理的会议纪要,虽然信息是保住了,但每个专家独特的思考角度和推理过程却被“拉平”了,这恰恰违背了组建多智能体团队的初衷。
面对这个困境,研究者们提出了一个名为“内在记忆代理”(Intrinsic Memory Agents)的框架,它的核心思想听起来非常符合直觉:与其让所有人看同一份会议纪要,不如让每个专家在参与公共讨论的同时,拥有一本自己的“私有笔记本”,并建立一套高效的会议规则。
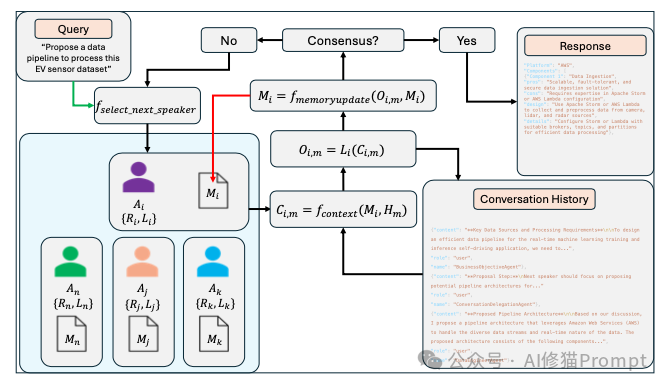
这个框架的基础,是为每个AI智能体配备一个完全独立的记忆系统,它有三个非常关键的特点:
那么问题来了,既然大家的笔记本都是私有的,信息要怎么同步,团队又该如何协作并达成一致呢?这个框架的设计是“共享白板”加“会议规则”模式。
当然,一个好的想法需要用实验来验证。研究者们通过两个核心实验来验证其“内在记忆智能体”框架的有效性,一个是对照基准的量化测试,另一个是更贴近实际应用的案例研究。以下是关于这两个实验的详细讲解
这个实验的目的,是在一个标准化的、结构化的规划任务中,将“内在记忆智能体”框架与其他主流的记忆架构进行直接的性能对比。
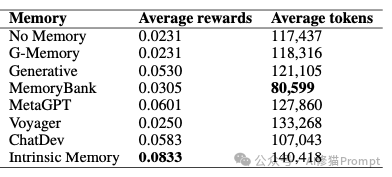
光有量化数据还不够,这个框架在真实的复杂项目里表现如何呢?第二个实验就是为了回答这个问题。
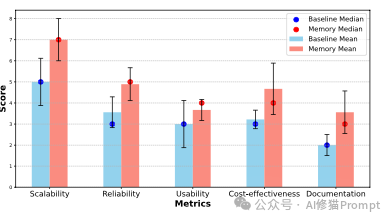
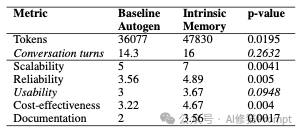

为了验证这个框架的实际效果,我复现了论文中的"内在记忆智能体"框架,并选择了一个更贴近商业实战的场景,让8位AI专家协作制定一个完整的sales-led的Go-To-Market(GTM)市场进入战略。
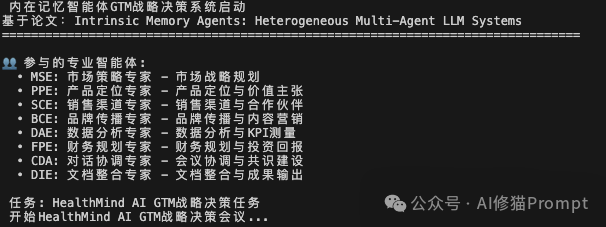
在下方的示例中是一款名为"HealthMind AI"的健康管理SaaS虚构产品(仅做示例),Multi-Agent的任务是为此召开战略规划会议。为此我精心设计了一个完整的AI专家团队,让每位成员都拥有清晰的专业定位和独立的"记忆笔记本":
这种设计确保了每位专家都能带着自己部门的专业视角参会,就像真实的董事会会议一样。

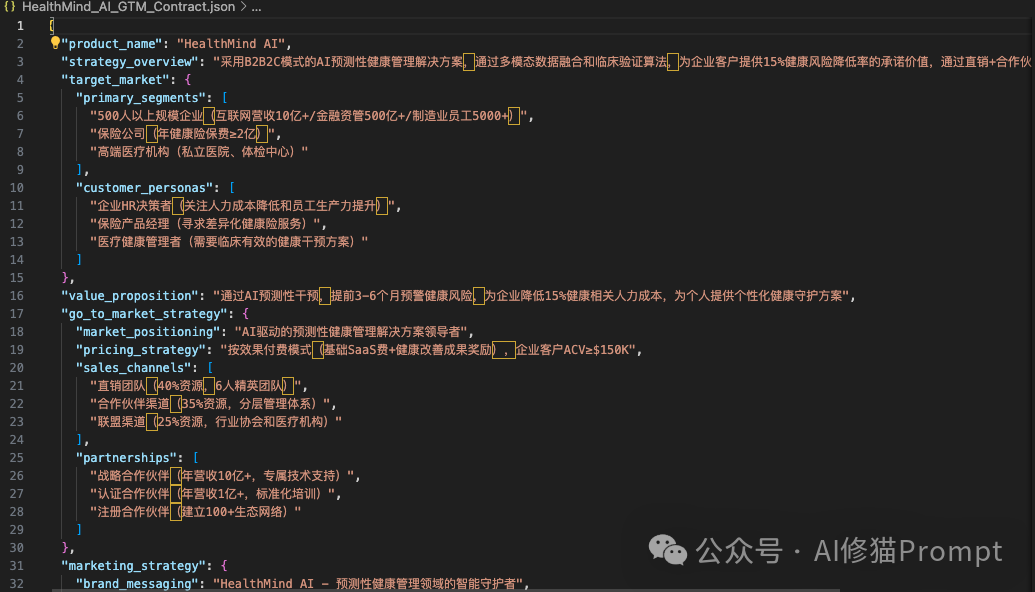
这种异构化的记忆结构确保了每位专家都能从自己的专业角度深度思考,而不会被其他领域的信息"干扰"。这是真正具有共识的"团队智慧",这说明"内在记忆智能体"框架确实能够在复杂的商业场景中发挥作用,关键的是能让每个Agent保持了自己的专业特色和思考角度,不会被统一的上下文信息"同质化,并且通过共享的"会议白板"实现了信息的有效传递和共识达成。这份代码周末我会分享在我的Agent开发者交流群中,欢迎您一起来讨论!
这项研究为我们开发复杂的AI应用提供了极具价值的思路,它告诉我们,构建高效的AI团队,关键可能不在于一个多么强大的中央大脑或共享记忆库,而在于如何让每个成员都能“守住”自己的专业视角,同时又能高效地达成共识。关于现实中的共识,感兴趣您可以看一下前天的文章《AI时代还用德尔菲法?其实“少数人”远比“多数人”更有价值 |谷歌最新》,研究者也提及目前这个框架的记忆模板还需要我们手动设计,但这无疑打开了一扇新的大门,未来的研究或许能实现模板的自动生成,让构建这样一个各司其职、记忆独立的AI专家团队变得更加简单。
文章来自于微信公众号“AI修猫Prompt”。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
