# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
长期以来,扩散模型的训练通常依赖由变分自编码器(VAE)构建的低维潜空间表示。然而,VAE 的潜空间表征能力有限,难以有效支撑感知理解等核心视觉任务,同时「VAE + Diffusion」的范式在训练与推理效率上也存在显著瓶颈。
清华大学智能视觉团队和快手可灵团队联合推出《Latent Diffusion Model without Variational Autoencoder》与近期爆火的谢赛宁团队 RAE 工作不谋而合,但在总体设计思路与研究重点上有所差异。
本篇文章通过直接结合预训练视觉特征编码器(如 DINO、SigLIP、MAE)结合残差信息学习预训练视觉特征编码器丢失的图片重建信息与专门训练的解码器,有效替代了传统 VAE,提升了表示质量与效率。
本文提出的系统性框架称为 SVG(Self-supervised representation for Visual Generation)。

该论文同样对传统 VAE + Diffusion 的局限性进行了分析,发现其关键问题在于 VAE 空间存在非常明显的语义纠缠现象。VAE 的 latent 空间缺乏清晰语义结构,不同类别特征高度混合(论文通过 t-SNE 可视化验证,普通 VAE latent 中不同语义类别的特征点严重重叠),导致扩散模型需花费大量步数学习数据分布。
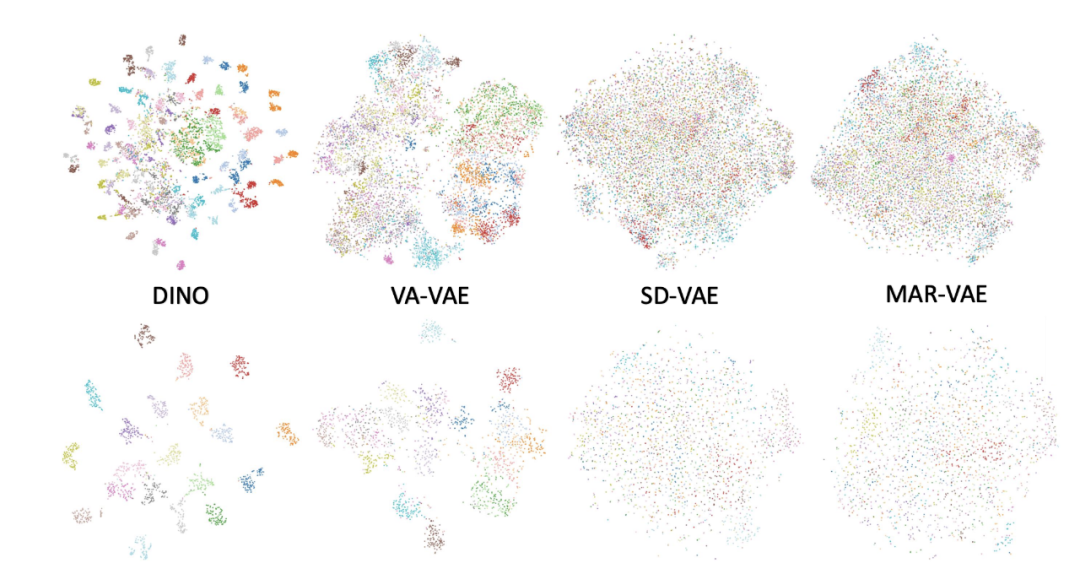
不同特征空间中不同语义类别的 t-SNE 可视化图
这种语义纠缠现象直接导致了两个关键问题:
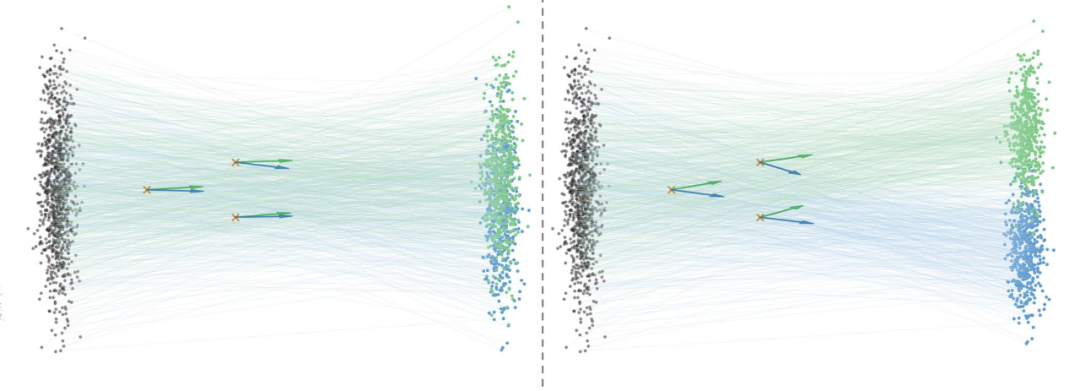
特征空间语义纠缠会对生成模型训练推理带来消极影响
考虑到各类视觉基础模型(如 DINO、SigLIP)已经构建出了具有优良语义结构的空间,研究者认为这类预训练视觉特征空间可能更适合生成模型的训练,同时也具有更强的可通用性。其中 DINO 特征在各种视觉下游任务中已经展现出了良好的性能,并且保留了基础的图像结构信息,具备比较高的重建潜力。
SVG 破局:
靠 DINO 搭地基,残差分支补细节
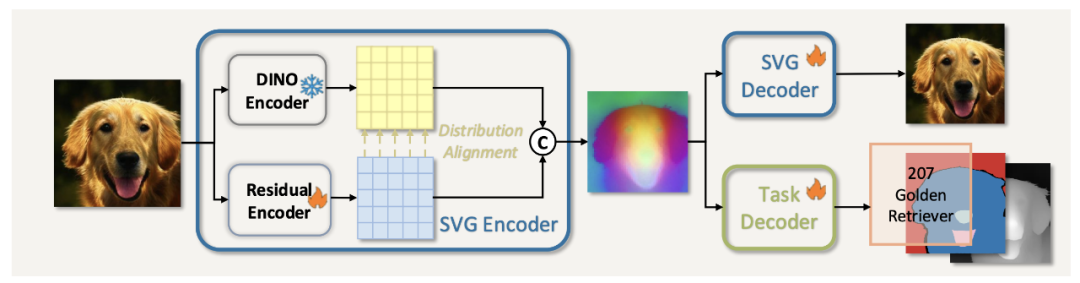
SVG 自编码器结构示意图
SVG 的核心思路很简单:用更强的语义结构解锁模型生成潜力,基于自监督特征构建统一特征空间。
SVG 自编码器由「冻结的 DINOv3 编码器」、「轻量残差编码器」、「解码器」三部分组成,核心是通过多组件协作同时实现强判别性的语义结构与图像细节补充。
二者结合,构成了一个既有良好语义可区分性,又具有强重建能力的潜在空间。

重建效果展示图:残差编码器修复了图像色差问题,补充了高频细节
SVG 扩散训练:
直接在高维 SVG 特征空间学习
与传统 LDM 在 VAE 的低维(如 16×16×4)latent 空间训练不同,SVG 扩散模型直接在高维特征空间(16×16×392)训练。研究者指出,尽管之前的观点大多认为高维空间训练易导致生成模型收敛不稳定,但实验证明 SVG 空间良好的性质使得在这种高维度情况下,模型训练依旧稳定,甚至效率更高。
论文在 ImageNet 256×256 数据集上进行了全面实验,对比 SiT、DiT、MaskDiT 等主流 LDM,从生成性能、效率、多任务适配性三个维度验证 SVG 的优势,核心结果如下:
在训练 80 个 epoch,25 步采样条件下,SVG-XL(675M 参数)的生成性能全面超越同规模基线:
无分类器引导(w/o CFG)时,SVG-XL 的 gFID 为 6.57,而 SiT-XL(SD-VAE)为 22.58、SiT-XL(VA-VAE)为 7.29;
有分类器引导(w/ CFG)时,SVG-XL 的 gFID 降至 3.54,SiT-XL(VA-VAE)为 4.13。
若延长训练至 1400 个 epoch,SVG-XL 的 gFID 可进一步降至 1.92(w/ CFG),接近当前生成模型 SOTA 水平。

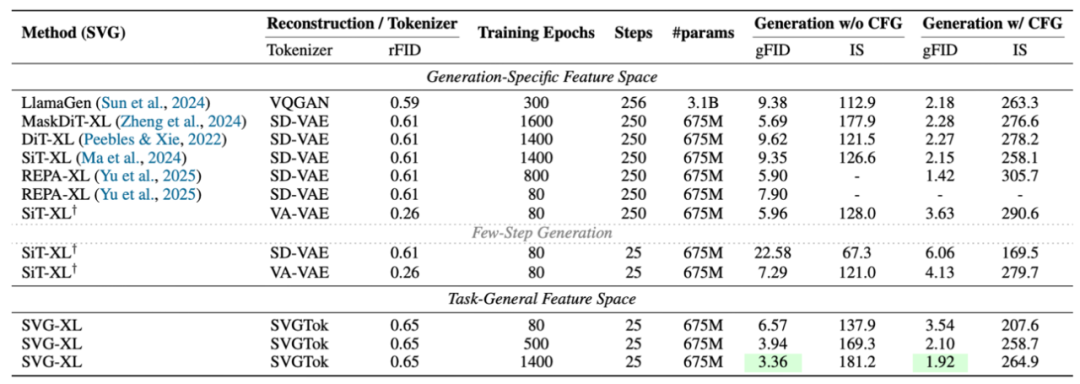
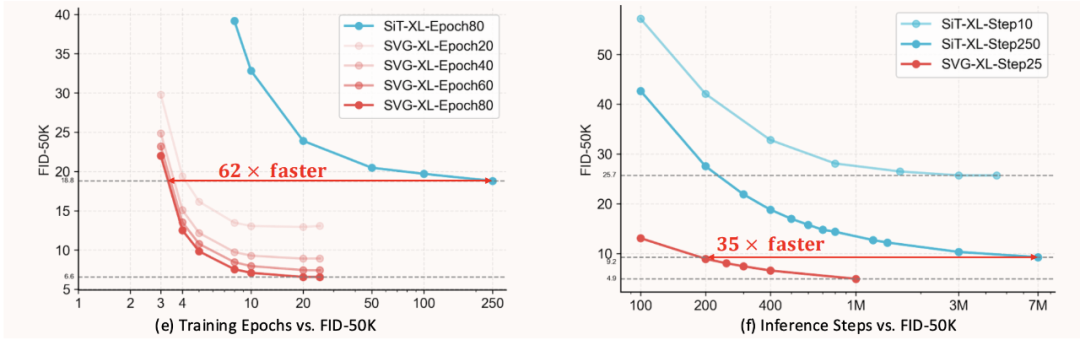
训练效率: 在 w/o CFG 设定下,SVG-XL 仅需 80 个 epoch 即可达到 SiT-XL 1400 个 epoch 的生成质量(gFID 6.57 vs 9.35);
推理效率: 消融实验中,5 步采样时,SVG-XL 的 gFID 为 12.26(w/o CFG),而 SiT-XL(SD-VAE)为 69.38、SiT-XL(VA-VAE)为 74.46,展现了良好的少步数推理性能。
SVG 的 latent 空间继承了 DINOv3 的良好性质,可直接用于分类、分割、深度估计等任务,无需额外微调编码器:

消融实验结果证明 SVG 编码器完全保持了 DINOv3 编码器的性能。这一结果验证了 SVG 作为统一表征空间的可行性。
研究者发现 SVG 空间中的随机噪声在直接线性插值与球面线性插值下均能生成平滑过渡的图像;而传统 VAE 空间中直接线性插值可能产生较差的中间结果。这证明了 SVG 空间的鲁棒性。

研究者还对 SVG 进行了零样本编辑实验,证明基于 SVG 空间的生成模型依然具备 VAE + Diffusion 模型所具备的可编辑性。

总结
SVG 的核心价值并非单纯「弃用 VAE」,而是通过「自监督特征 + 残差细节」的组合,证明了「生成、理解与感知共享统一 latent 空间」的可行性。这一思路不仅解决了传统 LDM 的效率与通用性痛点,更为后续通用视觉模型的研发提供了新的思路。
在总体思路上,该论文关键思路与谢赛宁团队的 RAE 高度相似,都验证了在生成模型训练中用预训练视觉特征编码器替代 VAE 的可行性。RAE 工作更多侧重于如何优化改善扩散模型在这种高维度特征空间的训练,而本文解决了单纯依赖预训练视觉特征编码器带来的重建效果差的问题,从而也为该方法用于统一生成编辑模型初步验证了可行性。
更多细节请参阅原论文。
文章来自于微信公众号 “机器之心”,作者 “机器之心”


【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
