# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在处理短文本时,大语言模型(LLM)已经表现出惊人的理解和生成能力。但现实世界中的许多任务——如长文档理解、复杂问答、检索增强生成(RAG)等——都需要模型处理成千上万甚至几十万长度的上下文。
与此同时,模型参数规模也从数十亿一路飙升至万亿级别。
在「上下文长度激增」与「模型参数量膨胀」的双重挑战下,Token压缩不再是优化项,而是必需品。
若不能有效缩减输入规模,即便最强大的大语言模型,也难以高效处理我们需要它分析的海量信息。
南京理工大学、中南大学、南京林业大学的研究人员提出VIST(Vision-centric Token Compression in LLM)框架,正是为了解决这一痛点。

论文链接:https://arxiv.org/abs/2502.00791
研究团队早在一年多以前NeurIPS 2024就开始探索——如何让模型像人类一样,以视觉的方式更高效地理解长文本。

论文链接:https://arxiv.org/pdf/2406.02547
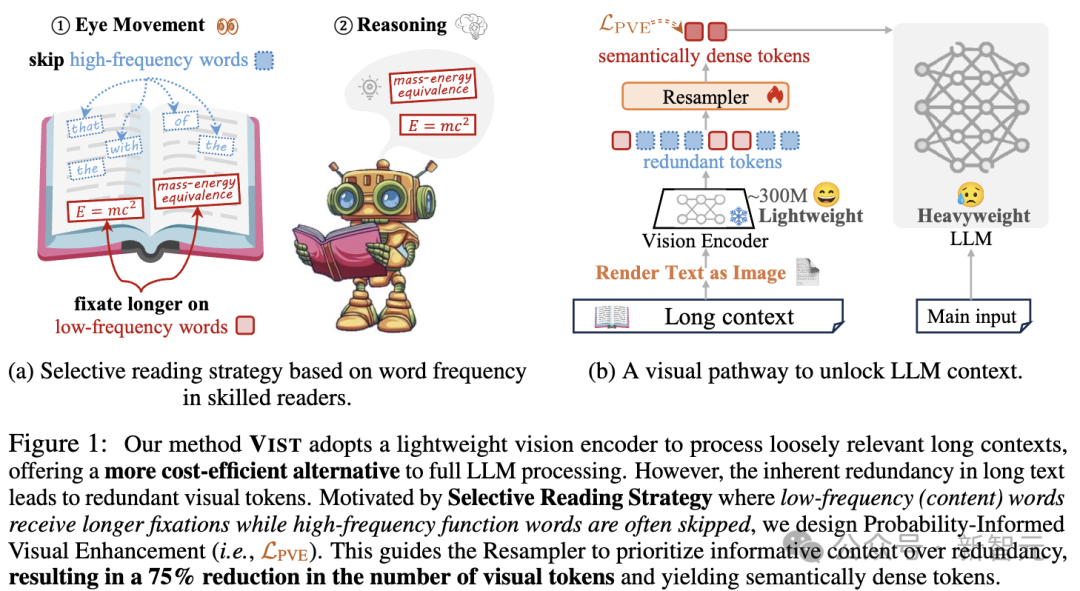
人类阅读文章时,不会逐字读完每一个词。
「的」「了」「和」这些功能性高频词,几乎是被大脑自动略过的。真正让我们停下来的,是那些承载意义的低频词——名词、动词、数字等。
VIST 的核心思想,就是让大模型也具备这种「选择性阅读」能力。
它设计了一种模仿人类「快–慢阅读通路(Slow–Fast Reading Circuit)」的视觉化压缩机制,让大模型在理解长文本时,既能快速扫读,又能深入思考:
快路径(Fast Path):将远处、相对次要的上下文渲染为图像,由一个冻结的轻量级视觉编码器快速提取显著性语义;
慢路径(Slow Path):将关键的近处文本直接输入 LLM,用于深层推理与语言生成。
这种「视觉+语言」的双通道协作,就像人类的眼睛与大脑——一边扫视全局,一边聚焦要点,深度思考。
VIST让模型真正具备了「像人一样速读」的能力。
凭借这一设计,在处理相同文本内容时,VIST所需的视觉Token数量仅为传统文本分词所需Token数量的56%,内存减少了50%。
用「视觉压缩」解锁长文本理解
早期的LLM主要通过tokenizer把文本拆分的离散token输入给LLM去处理,这种范式带来了很多好处如高度语义化。
但是已有研究发现,经过大规模图文配对数据预训练,CLIP等视觉编码器能够自发掌握 OCR 能力,这使它们可以直接理解文本图像内容,为长文本的视觉化处理提供了强大工具。
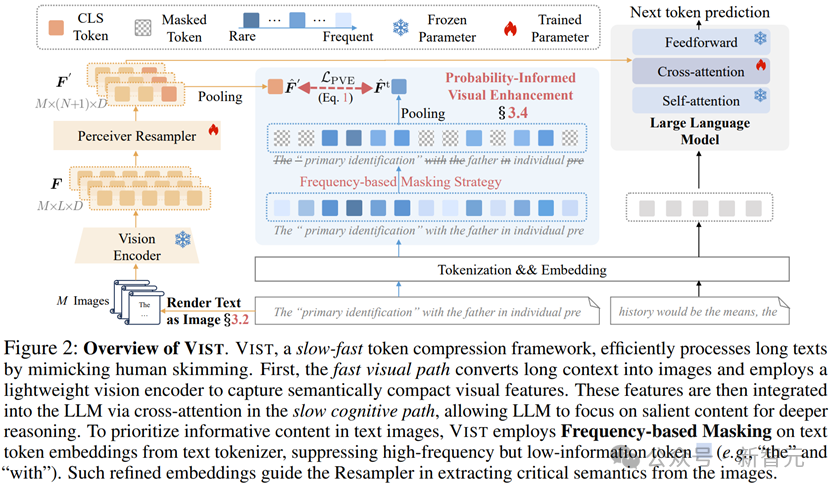
VIST则借鉴了人类高效阅读的技巧,提出了一种全新的快–慢视觉压缩框架,用视觉方式处理长文本,让模型既能快速扫读,又能深度理解。
快路径(Fast Path)
将次要的长距离上下文渲染成图像,由轻量级视觉编码器处理;
通过 Resampler 将视觉特征进一步压缩为4倍;
压缩后的视觉特征再通过cross-attention与LLM的主输入整合。
慢路径(Slow Path)
对近处或核心文本直接交给LLM处理,进行深度推理和语言生成。
这种「扫视远处,专注近处」的方式,模拟了人类阅读的自然策略,让模型在长文本场景下既高效又精准。
概率感知视觉增强
教模型学会略读
虽然视觉编码器(如 CLIP)非常强大,但它们主要在自然图像上训练,对于渲染文本的理解能力有限。而且,长文本中往往充斥大量冗余信息,如果不加选择地处理,浪费算力,还会被干扰得抓不住重点。
为此,VIST引入了一个巧妙的机制——概率感知视觉增强(PVE, Probability-informed Visual Enhancement),教模型「略读」,抓住关键信息,忽略冗余词。

在训练中,PVE采用基于频率的屏蔽策略(Frequency-based Masking Strategy)把高频但信息量低的词(如英文中的 「the」、「with」)掩码而重点保留低频、高信息量词如名词、动词、数字等核心内容。
这些经过语义优化的文本嵌入(embeddings)有效指导Resampler从文本图像中提取最重要的语义信息,让视觉压缩模块更高效、更精准。
视觉压缩的极大潜力
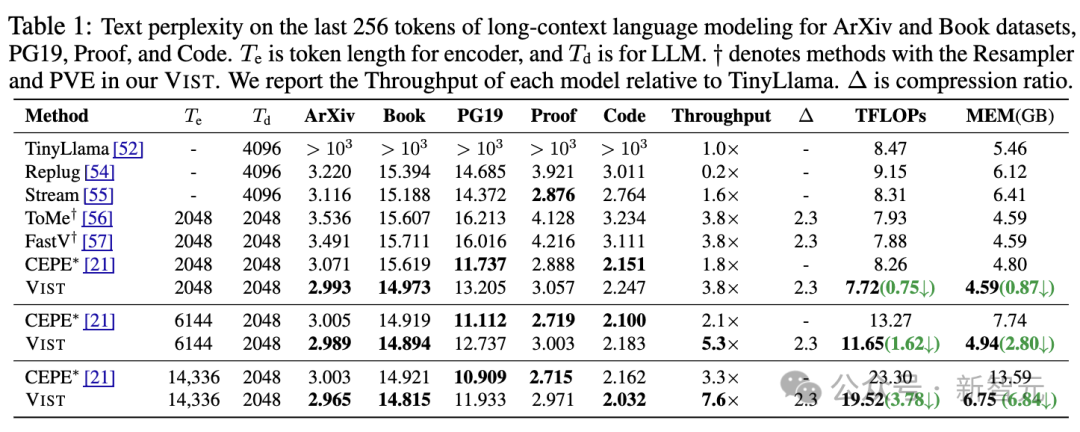
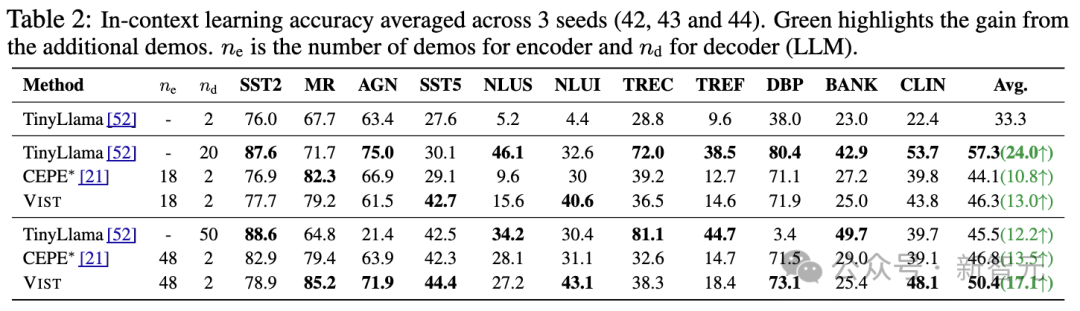
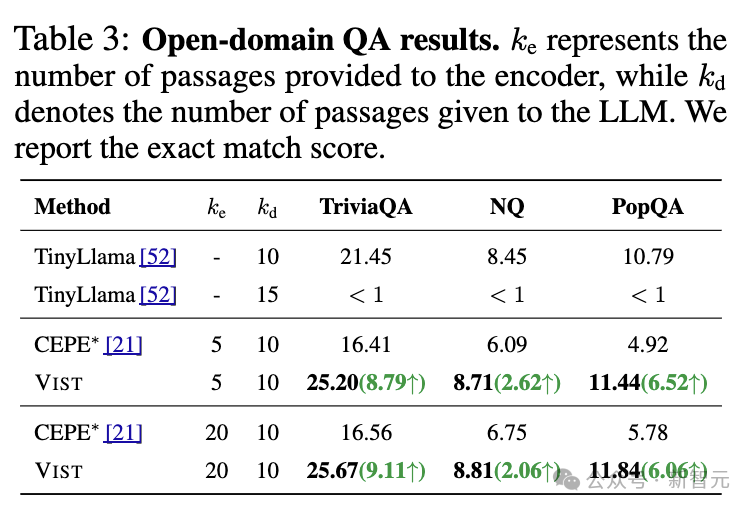
在开放域问答(Open-domain QA) 任务以及11 个 In-Context Learning(ICL)基准任务 上,VIST 显著优于基于文本编码器的压缩方法 CEPE。
即便在极端条件下——所有篇章仅通过视觉编码器处理——VIST仍能在开放域问答任务中达到与TinyLlama相当的性能,充分显示了视觉压缩在长文本处理中的可靠性。
此外,VIST在处理相同文本内容时,所需视觉 Token 数量比传统文本 Token 少56%(压缩比约为2.3,从 1024 个文本Token压缩到448个视觉 Token),同时显存使用减少50%,极大提高了计算效率。
让大模型「用眼睛读文字」
VIST利用轻量级视觉编码器,将冗长的上下文信息压缩处理,为大语言模型提供了一条高效、低成本的新路径。
更妙的是,视觉编码器还能充当视觉文本分词器(Visual Text Tokenization),带来四大优势:
1. 简化分词流程传统文本分词器依赖复杂规则和固定词表,通常涉及近十步人工预处理(如小写化、标点符号处理、停用词过滤等)。
视觉编码器直接将渲染后的文本视作图像输入,无需繁琐预处理,处理流程更直接高效。
2. 突破词表瓶颈传统分词器在多语言环境下容易受词表限制影响性能,而视觉编码器无需词表,统一处理多种语言文本,大幅降低嵌入矩阵和输出层的计算与显存开销。
3. 对字符级噪声更鲁棒视觉编码器关注整体视觉模式,而非单个 Token 匹配,因此对拼写错误或低级文本攻击具备天然抵抗力。
4. 多语言高效性尽管本文主要针对英文,视觉文本分词器在其他语言中同样高效:与传统文本分词相比,可减少62%的日文Token、78%的韩文Token、27%的中文Token,在处理长文本时优势尤为显著。
结语与未来展望
VIST 展示了「视觉 + 语言」协作在大模型长文本理解中的巨大潜力:
未来,视觉驱动的 Token 压缩可能会成为长上下文 LLM 的标准组件。 随着模型规模不断增长,这种「先看再读」的策略,将帮助大模型在保证理解能力的同时,大幅降低计算成本,为多模态智能理解铺平道路。
参考资料:
https://arxiv.org/abs/2502.00791
文章来自于微信公众号 “新智元”,作者 “新智元”



【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
