# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
同样是语义相似度结合时效性做rerank,指数衰减、高斯衰减、线性衰减怎么选?
假设你要在一个新闻应用中落地语义检索功能,让用户搜索雷军的投资版图盘点时,能自动关联顺为资本、小米战投等核心关联信息。
那么在确定了向量数据库应该用Milvus之后,要怎么对搜索结果排序呢?
是直接根据基于embedding的语义相似度,根据语义进行内容排序,还是引入更多与新闻相关的变量,比如时间?
答案是后者,在类似新闻、电商这样的场景,我们做检索既要考虑相似度,也需要让新鲜内容自动浮出水面,而旧闻悄然后移。
针对这一需求,Milvus 2.6中推出了一个备受关注的亮点功能 Time-aware Ranking Functions(时间感知排名函数),也称为 Time-Aware Decay Functions(时间感知衰减函数)。
这个功能让搜索结果不再仅依赖向量相似度,而是巧妙融入时间因素,实现更智能的排名调整。
本文将深入探讨这一功能的细节、意义、应用场景,并通过一个实际案例展示其使用方式。
Time-aware Ranking Functions 通过在搜索结果重排序(re-ranking)阶段应用时间衰减,动态调整文档的相关性分数。 传统向量搜索仅基于相似度(如 L2、COSINE 等)排名,但现实中信息价值往往随时间衰减(如新闻的时效性)。该功能使用集合中的时间戳字段(支持 INT8/16/32/64、FLOAT 或 DOUBLE 类型),计算一个衰减分数(0 到 1 之间),然后与归一化相似度相乘,生成最终排名,从而平衡语义相似度和时间相关性。对于时间相关的衰减,确保参数单位(如秒、毫秒)与集合的时间戳一致。
该功能通过三个阶段计算最终分数:
1.归一化相似度分数:将向量相似度分数标准化到 0-1 范围。对于 L2 和 JACCARD 指标(较低值表示更高相似度),使用公式:normalized_score = 1.0 - (2 × arctan(score))/π 对于 IP、COSINE 和 BM25 指标,直接使用原始分数。
2.计算衰减分数:基于选择的衰减函数,将数值字段(如时间戳)转换为 0-1 范围的衰减分数,反映与理想点(如当前时间)的“距离”。
3.计算最终分数:final_score = normalized_similarity_score × decay_score 在混合搜索中,使用多个向量字段的最大归一化分数:final_score = max(normalized_scores) × decay_score。
Milvus 支持三种衰减模型,每种适合不同曲线形状:
配置参数
(通过 Python SDK 的 Function 对象实现):
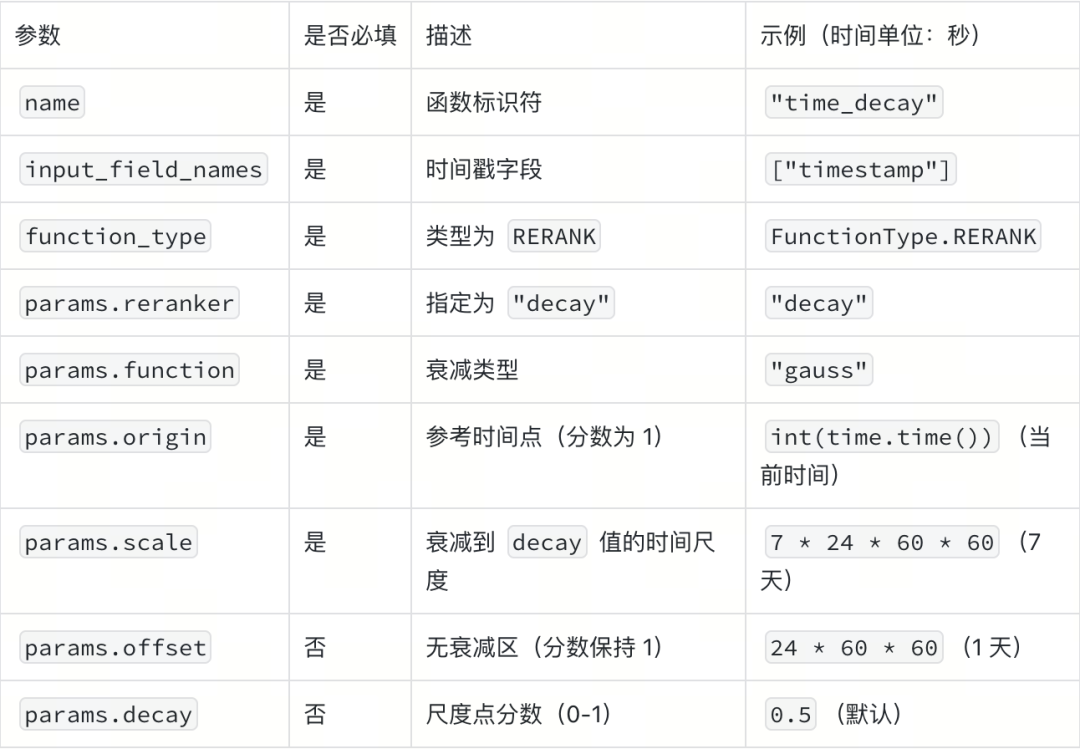
在搜索时,将函数传入 ranker 参数即可应用,支持标准向量搜索和混合搜索。
示例配置(Gaussian):
from pymilvus import Function, FunctionType
from datetime import datetime
decay_ranker = Function(
name="time_decay",
input_field_names=["timestamp"],
function_type=FunctionType.RERANK,
params={
"reranker": "decay",
"function": "gauss",
"origin": int(datetime.now().timestamp()),
"scale": 7 * 24 * 60 * 60, # 7 天
"offset": 24 * 60 * 60, # 1 天
"decay": 0.5
}
)
在 search() 或 hybrid_search() 中应用 ranker 参数。
引入 Time-aware Ranking Functions 的核心意义在于解决传统向量搜索的“时效盲区”。
在动态数据环境中(如社交媒体或实时推荐),旧信息往往淹没新内容,导致用户体验下降。 该功能通过内置衰减机制,直接在 Milvus 引擎中处理时间因素,避免了后处理(如客户端排序)的额外开销,提高了查询效率和精度。
此外,它与 Milvus 的文本分析管道无缝整合,支持全文本搜索与向量嵌入的结合,进一步桥接传统信息检索和现代 AI。 在 v2.6.3 更新中,还优化了分数合并逻辑,提升了性能。 总体而言,这一功能让 Milvus 更适合亿级规模的实时应用,降低了开发复杂度和运维成本,推动 AI 搜索的民主化。
Time-aware Ranking Functions 适用于任何需要时效优先的向量搜索场景:
这些场景中,该功能通过 configurable 衰减率,确保结果既相关又及时。
为了快速了解功能,我们通过一个新闻文章搜索系统案例演示,使用 Milvus 构建时间感知排名。 假设我们有一个包含 7 篇 AI 相关新闻的集合,发布日期从 1 天前到 120 天前,包括相同内容但不同日期的文章对。
(1)连接 Milvus 并创建集合:使用 pymilvus 连接,定义 schema 包括 headline、content、dense(语义向量)、sparse_vector(BM25)和 publish_date。
(2)设置嵌入函数:使用 Openai text embedding 模型生成 dense 向量,BM25 生成 sparse 向量。
(3)插入数据:添加文章,publish_date 为时间戳。
(4)配置衰减排名器:定义 Gaussian、Exponential 和 Linear 排名器,以当前时间为 origin。
(5)执行搜索:查询 "artificial intelligence advancements",比较无衰减和有衰减结果。
import datetime
import matplotlib.pyplot as plt
import numpy as np
from pymilvus import (
MilvusClient,
DataType,
Function,
FunctionType,
AnnSearchRequest,
)
# Create connection to Milvus
milvus_client = MilvusClient("http://localhost:19530")
# Define collection name
collection_name = "articles_tutorial"
# Clean up any existing collection with the same name
milvus_client.drop_collection(collection_name)
# Create schema with fields for content and temporal information
schema = milvus_client.create_schema(enable_dynamic_field=False, auto_id=True)
schema.add_field("id", DataType.INT64, is_primary=True)
schema.add_field("headline", DataType.VARCHAR, max_length=200, enable_analyzer=True)
schema.add_field("content", DataType.VARCHAR, max_length=2000, enable_analyzer=True)
schema.add_field("dense", DataType.FLOAT_VECTOR, dim=3072) # For dense embeddings
schema.add_field("sparse_vector", DataType.SPARSE_FLOAT_VECTOR) # For sparse (BM25) search
schema.add_field("publish_date", DataType.INT64) # Timestamp for decay ranking
# Create embedding function for semantic search
text_embedding_function = Function(
name="openai_embedding",
function_type=FunctionType.TEXTEMBEDDING,
input_field_names=["content"],
output_field_names=["dense"],
params={
"provider": "openai",
"model_name": "text-embedding-3-large"
}
)
schema.add_function(text_embedding_function)
# Create BM25 function for keyword search
bm25_function = Function(
name="bm25",
input_field_names=["content"],
output_field_names=["sparse_vector"],
function_type=FunctionType.BM25,
)
schema.add_function(bm25_function)
index_params = milvus_client.prepare_index_params()
index_params.add_index(field_name="dense", index_type="AUTOINDEX", metric_type="L2")
index_params.add_index(
field_name="sparse_vector",
index_name="sparse_inverted_index",
index_type="AUTOINDEX",
metric_type="BM25",
)
milvus_client.create_collection(
collection_name,
schema=schema,
index_params=index_params,
consistency_level="Bounded"
)
print(f"Collection {collection_name} is created successfully")
current_time = int(datetime.datetime.now().timestamp())
current_date = datetime.datetime.fromtimestamp(current_time)
print(f"Current time: {current_date.strftime('%Y-%m-%d %H:%M:%S')}")
# Sample news articles spanning different dates
articles = [
{
"headline": "AI Breakthrough Enables Medical Diagnosis Advancement",
"content": "Researchers announced a major breakthrough in AI-based medical diagnostics, enabling faster and more accurate detection of rare diseases.",
"publish_date": int((current_date - datetime.timedelta(days=120)).timestamp()) # ~4 months ago
},
{
"headline": "Tech Giants Compete in New AI Race",
"content": "Major technology companies are investing billions in a new race to develop the most advanced artificial intelligence systems.",
"publish_date": int((current_date - datetime.timedelta(days=60)).timestamp()) # ~2 months ago
},
{
"headline": "AI Ethics Guidelines Released by International Body",
"content": "A consortium of international organizations has released new guidelines addressing ethical concerns in artificial intelligence development and deployment.",
"publish_date": int((current_date - datetime.timedelta(days=30)).timestamp()) # 1 month ago
},
{
"headline": "Latest Deep Learning Models Show Remarkable Progress",
"content": "The newest generation of deep learning models demonstrates unprecedented capabilities in language understanding and generation.",
"publish_date": int((current_date - datetime.timedelta(days=15)).timestamp()) # 15 days ago
},
# Articles with identical content but different dates
{
"headline": "AI Research Advancements Published in January",
"content": "Breakthrough research in artificial intelligence shows remarkable advancements in multiple domains.",
"publish_date": int((current_date - datetime.timedelta(days=90)).timestamp()) # ~3 months ago
},
{
"headline": "New AI Research Results Released This Week",
"content": "Breakthrough research in artificial intelligence shows remarkable advancements in multiple domains.",
"publish_date": int((current_date - datetime.timedelta(days=5)).timestamp()) # Very recent - 5 days ago
},
{
"headline": "AI Development Updates Released Yesterday",
"content": "Recent developments in artificial intelligence research are showing promising results across various applications.",
"publish_date": int((current_date - datetime.timedelta(days=1)).timestamp()) # Just yesterday
},
]
# Insert articles into the collection
milvus_client.insert(collection_name, articles)
print(f"Inserted {len(articles)} articles into the collection")
# Create a Gaussian decay ranker
gaussian_ranker = Function(
name="time_decay_gaussian",
input_field_names=["publish_date"],
function_type=FunctionType.RERANK,
params={
"reranker": "decay",
"function": "gauss", # Gaussian/bell curve decay
"origin": current_time, # Current time as reference point
"offset": 7 * 24 * 60 * 60, # One week (full relevance)
"decay": 0.5, # Articles from two weeks ago have half relevance
"scale": 14 * 24 * 60 * 60 # Two weeks scale parameter
}
)
# Create an exponential decay ranker with different parameters
exponential_ranker = Function(
name="time_decay_exponential",
input_field_names=["publish_date"],
function_type=FunctionType.RERANK,
params={
"reranker": "decay",
"function": "exp", # Exponential decay
"origin": current_time, # Current time as reference point
"offset": 3 * 24 * 60 * 60, # Shorter offset
"decay": 0.3, # Steeper decay
"scale": 10 * 24 * 60 * 60 # Different scale
}
)
# Create a linear decay ranker
linear_ranker = Function(
name="time_decay_linear",
input_field_names=["publish_date"],
function_type=FunctionType.RERANK,
params={
"reranker": "decay",
"function": "linear", # Linear decay
"origin": current_time, # Current time as reference point
"offset": 7 * 24 * 60 * 60, # One week (full relevance)
"decay": 0.5, # Articles from two weeks ago have half relevance
"scale": 14 * 24 * 60 * 60 # Two weeks scale parameter
}
)
(4)搜索:
# Helper function to format search results with dates and scores
def print_search_results(results, title):
print(f"\n=== {title} ===")
for i, hit in enumerate(results[0]):
publish_date = datetime.datetime.fromtimestamp(hit.get('publish_date'))
days_from_now = (current_time - hit.get('publish_date')) / (24 * 60 * 60)
print(f"{i+1}. {hit.get('headline')}")
print(f" Published: {publish_date.strftime('%Y-%m-%d')} ({int(days_from_now)} days ago)")
print(f" Score: {hit.score:.4f}")
print()
# Define our search query
query = "artificial intelligence advancements"
# 1. Search without decay ranking (purely based on semantic relevance)
standard_results = milvus_client.search(
collection_name,
data=[query],
anns_field="dense",
limit=7, # Get all our articles
output_fields=["headline", "content", "publish_date"],
consistency_level="Bounded"
)
print_search_results(standard_results, "SEARCH RESULTS WITHOUT DECAY RANKING")
# Store original scores for later comparison
original_scores = {}
for hit in standard_results[0]:
original_scores[hit.get('headline')] = hit.score
# 2. Search with each decay function
# Gaussian decay
gaussian_results = milvus_client.search(
collection_name,
data=[query],
anns_field="dense",
limit=7,
output_fields=["headline", "content", "publish_date"],
ranker=gaussian_ranker,
consistency_level="Bounded"
)
print_search_results(gaussian_results, "SEARCH RESULTS WITH GAUSSIAN DECAY RANKING")
# Exponential decay
exponential_results = milvus_client.search(
collection_name,
data=[query],
anns_field="dense",
limit=7,
output_fields=["headline", "content", "publish_date"],
ranker=exponential_ranker,
consistency_level="Bounded"
)
print_search_results(exponential_results, "SEARCH RESULTS WITH EXPONENTIAL DECAY RANKING")
# Linear decay
linear_results = milvus_client.search(
collection_name,
data=[query],
anns_field="dense",
limit=7,
output_fields=["headline", "content", "publish_date"],
ranker=linear_ranker,
consistency_level="Bounded"
)
print_search_results(linear_results, "SEARCH RESULTS WITH LINEAR DECAY RANKING")
=== SEARCH RESULTS WITHOUT DECAY RANKING ===
1. AI Research Advancements Published in January
Published: 2025-07-23 (90 days ago)
Score: 0.7090
2. New AI Research Results Released This Week
Published: 2025-10-16 (5 days ago)
Score: 0.7090
3. AI Development Updates Released Yesterday
Published: 2025-10-20 (1 days ago)
Score: 0.7317
4. Tech Giants Compete in New AI Race
Published: 2025-08-22 (60 days ago)
Score: 1.0101
5. AI Breakthrough Enables Medical Diagnosis Advancement
Published: 2025-06-23 (120 days ago)
Score: 1.1065
6. Latest Deep Learning Models Show Remarkable Progress
Published: 2025-10-06 (15 days ago)
Score: 1.1649
7. AI Ethics Guidelines Released by International Body
Published: 2025-09-21 (30 days ago)
Score: 1.3030
=== SEARCH RESULTS WITH GAUSSIAN DECAY RANKING ===
1. New AI Research Results Released This Week
Published: 2025-10-16 (5 days ago)
Score: 0.6074
2. AI Development Updates Released Yesterday
Published: 2025-10-20 (1 days ago)
Score: 0.5979
3. Latest Deep Learning Models Show Remarkable Progress
Published: 2025-10-06 (15 days ago)
Score: 0.3601
4. AI Ethics Guidelines Released by International Body
Published: 2025-09-21 (30 days ago)
Score: 0.0642
5. Tech Giants Compete in New AI Race
Published: 2025-08-22 (60 days ago)
Score: 0.0000
6. AI Research Advancements Published in January
Published: 2025-07-23 (90 days ago)
Score: 0.0000
7. AI Breakthrough Enables Medical Diagnosis Advancement
Published: 2025-06-23 (120 days ago)
Score: 0.0000
=== SEARCH RESULTS WITH EXPONENTIAL DECAY RANKING ===
1. AI Development Updates Released Yesterday
Published: 2025-10-20 (1 days ago)
Score: 0.5979
2. New AI Research Results Released This Week
Published: 2025-10-16 (5 days ago)
Score: 0.4774
3. Latest Deep Learning Models Show Remarkable Progress
Published: 2025-10-06 (15 days ago)
Score: 0.1065
4. AI Ethics Guidelines Released by International Body
Published: 2025-09-21 (30 days ago)
Score: 0.0161
5. Tech Giants Compete in New AI Race
Published: 2025-08-22 (60 days ago)
Score: 0.0005
6. AI Research Advancements Published in January
Published: 2025-07-23 (90 days ago)
Score: 0.0000
7. AI Breakthrough Enables Medical Diagnosis Advancement
Published: 2025-06-23 (120 days ago)
Score: 0.0000
=== SEARCH RESULTS WITH LINEAR DECAY RANKING ===
1. New AI Research Results Released This Week
Published: 2025-10-16 (5 days ago)
Score: 0.6074
2. AI Development Updates Released Yesterday
Published: 2025-10-20 (1 days ago)
Score: 0.5979
3. Latest Deep Learning Models Show Remarkable Progress
Published: 2025-10-06 (15 days ago)
Score: 0.3226
4. AI Research Advancements Published in January
Published: 2025-07-23 (90 days ago)
Score: 0.3037
5. Tech Giants Compete in New AI Race
Published: 2025-08-22 (60 days ago)
Score: 0.2484
6. AI Breakthrough Enables Medical Diagnosis Advancement
Published: 2025-06-23 (120 days ago)
Score: 0.2339
7. AI Ethics Guidelines Released by International Body
Published: 2025-09-21 (30 days ago)
Score: 0.2084
(1)无衰减排名(纯语义相关性搜索)
这是基准(Baseline),其结果完全由查询 artificial intelligence advancements 与每篇文章内容之间的语义相似度决定,时间因素被完全忽略。
(2)高斯衰减排名 (Gaussian Decay)
高斯衰减器引入了时间维度,其衰减曲线像一个“钟形”,对近期内容友好,对中期内容惩罚逐渐加重,对远期内容则给予极大的惩罚。
配置: offset 为7天(一周内不惩罚),scale 为14天,decay 为0.5(两周前的文章,时间权重衰减为50%)。
(3)指数衰减排名 (Exponential Decay)
指数衰减是最“严厉”的时间衰减方式,时间越久,权重下降得越快。
配置: offset 仅3天,scale 为10天,decay 为0.3。这些参数比高斯衰减的配置更为“激进”。
(4)线性衰减排名 (Linear Decay)
线性衰减的惩罚是恒定的,随着时间的推移,分数呈直线下降,是最“温和”的衰减方式。
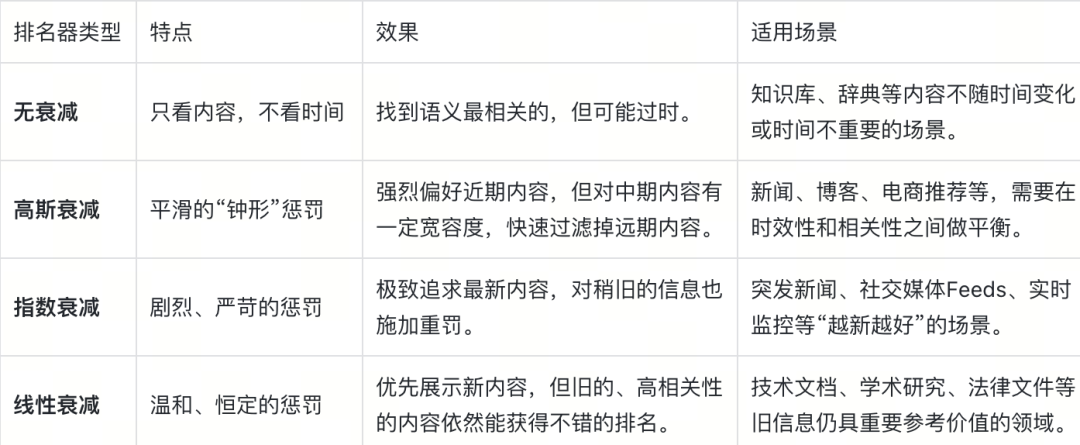
在实践中,我们可以根据以上排名器各自的特点,进行选择性的配置。
如有更多相关问题,欢迎评论区分享交流。
作者介绍

Zilliz 黄金写手:臧伟
文章来自于微信公众号 “Zilliz”,作者 “Zilliz”



【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
