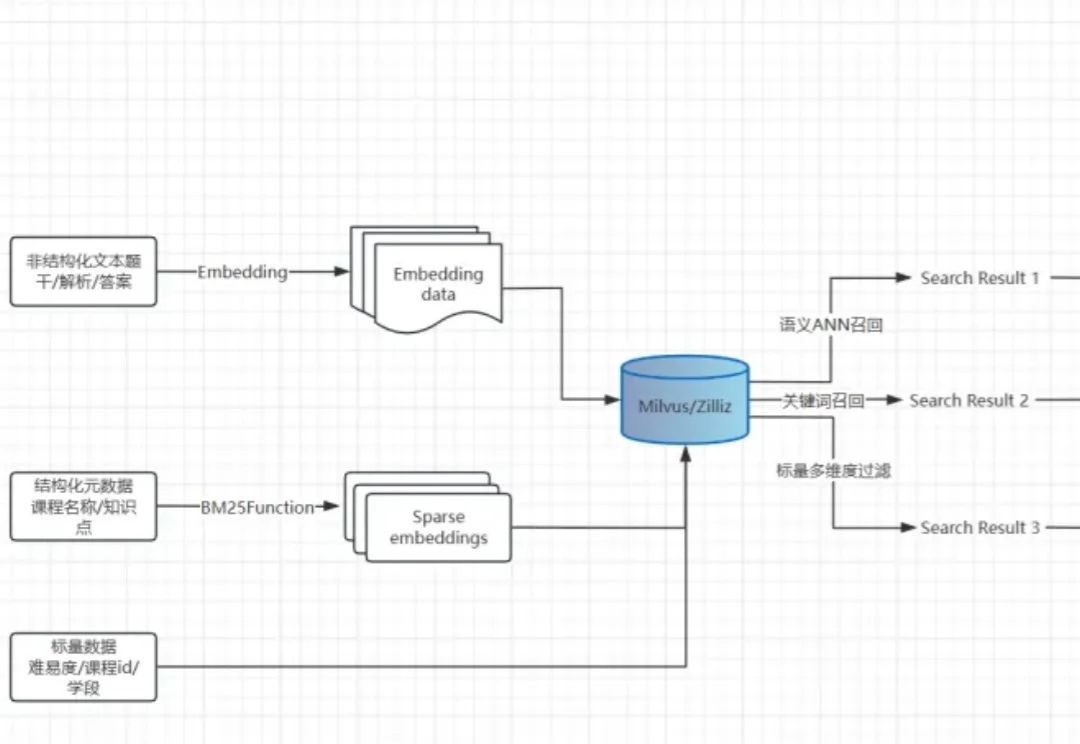
在线教育行业,如何用Milvus混合检索+微调embedding做题库检索与去重
在线教育行业,如何用Milvus混合检索+微调embedding做题库检索与去重在教育科技领域,题库是核心资产,更是连接学生、教师与知识体系的关键入口。
来自主题: AI技术研报
7252 点击 2026-05-21 09:48
 搜索
搜索
在教育科技领域,题库是核心资产,更是连接学生、教师与知识体系的关键入口。

jina-embeddings-v5-omni正式发布,我们把 v5-text 向量模型的能力延伸到图像、音频和视频。文本侧不变,v5-omni 产出的文本向量与 v5-text逐字节一致,无需重建任何已有索引。
Google悄悄干了一件大事——Gemini Embedding 2正式进入GA阶段,成为Gemini API中第一个原生多模态embedding模型。它能把文本、图片、视频、音频、PDF文档全部映射进同一个统一向量空间,支持100多种语言。

ICLR论文STEM架构率先提出「查表式记忆」架构,早于DeepSeek Engram三个月。它将Transformer的FFN从动态计算改为静态查表,用token索引的embedding表直接读取记忆,彻底解耦记忆容量与计算开销。

Google 最近发了 Gemini Embedding 2,他们第一个原生多模态向量模型。文本、图像、视频、音频、文档,全部映射到同一个 3072 维向量空间。这是 Omni Embedding(全模态向量模型)的大趋势:一个架构吃下所有模态,从 jina-embeddings-v4 到 Omni-Embed-Nemotron 再到 Omni-5,大家都在往这个方向收敛。

谷歌发布首个原生全模态 Embedding 模型 Gemini Embedding 2!它将文本、图、音视频及 PDF 无损融于统一向量空间,实现跨越五大模态的直接检索。这极大降低了架构成本,赋予了 AI 真正连贯的「记忆」,是重塑 AI 基建的里程碑。

刚刚,谷歌发布了首个原生多模态(Multimodal)嵌入模型——Gemini Embedding 2。这次模型最大的变化在于:把文本、图像、视频、音频和文档,全部映射进同一个统一的嵌入空间。
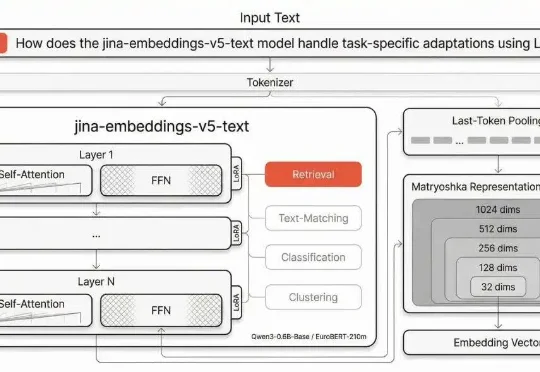
jina-embeddings-v5-text 岁在丙午,开年即战。Jina AI 的五代目向量模型春节期间正式发布。1B 参数内世界第一,全面刷新向量模型的性能天花板!

今天,Qwen 家族新成员+2,我们正式发布 Qwen3-VL-Embedding 和 Qwen3-VL-Reranker 模型系列,这两个模型基于 Qwen3-VL 构建,专为多模态信息检索与跨模态理解设计,为图文、视频等混合内容的理解与检索提供统一、高效的解决方案。
今天聊一聊我们如何做高质量rerank。