# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
REG 是一种简单而有效的方法,仅通过引入一个 class token 便能大幅加速生成模型的训练收敛。其将基础视觉模型(如 DINOv2)的 class token 与 latent 在空间维度拼接后共同加噪训练,从而显著提升 Diffusion 的收敛速度与性能上限。在 ImageNet 256×256 上,REG 相比 SiT 和 REPA 分别实现了 63 倍和 23 倍的收敛加速,如下图所示:



背景简述
REPA 及其变体通过把 noised latent 和视觉基础模型判别式 clean image representation 进行对齐,来加速 Diffusion 训练收敛,但其推理时无法使用外部特征,限制了其性能上限。
为此作者提出 REG(Representation Entanglement for Generation):将 low-level latent 与预训练视觉模型的 high-level class token 纠缠,并在训练中对二者同时加噪、联合去噪优化,从而使模型具备直接从纯噪声生成图像 - 类别对的能力。REG 在显著提升生成质量的同时大幅加速训练收敛,仅需额外引入一个 token(计算开销 <0.5%),几乎不增加推理成本。此外,推理过程中 REG 能同步生成图像 latent 及其全局语义信息,并利用这些语义知识主动指导和增强图像生成。
在 ImageNet 256×256 上,SiT-XL/2+REG 收敛速度分别较 SiT-XL/2 与 SiT-XL/2+REPA 提升 63 倍与 23 倍;仅 400K 步的 SiT-L/2+REG 已优于 4M 步的 SiT-XL/2+REPA。
REG 方法介绍

REPA 方案回顾
REPA 在训练阶段(Figure 2a)通过将 SiT 的中间 noised latent 与预训练视觉模型 DINOv2 的 clean dense feature 进行对齐,从而引入判别式语义指导并加速收敛。而在推理阶段(Figure 2b),REPA 无法再使用这一外部对齐机制,即无法直接获得和利用 DINOv2 的表征来提升生成效果。因为训练时其只是间接对齐 DINOv2 与 SiT,而并未将 DINOv2 的表征显式作为 SiT 的输入。
REG 训练和推理方案
REG 训练方案非常简单,只需将 DINOv2 的 class token(携带全局语义信息)与原始 latent 一起加噪,然后拼接后输入 SiT 进行去噪训练。具体伪代码流程如下:
1. DINOv2 class token 按照标准流程进行加噪成为 noised class token (cls_input)。
Python
noises_cls = torch.randn_like(cls_token)
cls_target = d_alpha_t * cls_token + d_sigma_t * noises_cls
cls_input = alpha_t.squeeze(-1).squeeze(-1) * cls_token + sigma_t.squeeze(-1).squeeze(-1) * noises_cls
2. noised class token 通过一个 linear 层,进行映射转换,和 noised latent (x) 保持相同通道维度。
Python
cls_token = self.cls_projectors (cls_input)
cls_token = self.norm (cls_token)
cls_token = cls_token.unsqueeze (1)
3. noised class token 和 noised latent 通过 torch.cat,进行空间维度的拼接。
Python
x = torch.cat ((cls_token, x), dim=1)
4. 进行 SiT 的 forward。
5. 计算对应的 denoising_loss_cls。
Python
denoising_loss_cls = mean_flat ((cls_output - cls_target) ** 2)
REG 的推理方案同样简洁:在原有 SiT 推理流程的基础上,只需将额外随机初始化的 class token 一起加噪并参与去噪即可,具体代码参考:https://github.com/Martinser/REG/blob/main/samplers.py
1. 随机初始化的 class token (cls_z) 和 latent (z)
Python
z = torch.randn (n, model.in_channels, latent_size, latent_size, device=device)
cls_z = torch.randn (n, args.cls, device=device)
2. class token 和 latent 一起进行联合推理
REG 具体效果
在 ImageNet 256×256 上,REG 在不使用 CFG 且不改造 SiT 与 VAE 的前提下,显著超越 REPA。SiT-XL/2+REG 相比 SiT-XL/2 与 SiT-XL/2+REPA 分别实现 63 倍和 23 倍的收敛加速,仅 400K 步的 SiT-L/2+REG 即优于 4M 步(10 倍时长)的 SiT-XL/2+REPA。而在 4M 步训练下,REG 的 FID 进一步达到 1.8。

ImageNet 256×256,REG 使用 CFG,480 epochs 的 1.40 FID 超越 REPA 800 epochs 1.42 FID,同时 800 epochs 更是达到 1.36 FID。

ImageNet 512×512,REG 的表现也非常不错,REG 使用 CFG,80 epochs FID 达到 1.68,超越 REPA 200 epochs 和 SiT 600 epochs 结果。

REG 消融实验
开销对比
训练开销对比。REG 和 SiT-XL/2 相比,达到相似的 FID,REG 训练时间减少了 97.90%。同时和 REG 相比,也达到相似的 FID,REG 训练时间减少了 95.72%。

推理开销对比。可以看到 REG 整体的开销几乎没有,Params,FLOPs 和 Latency 增加的开销小于 0.5%,但是 FID 却比 SiT-XL/2 + REPA 大幅提高 56.46%。

不同超参的对比

作者对不同对齐目标,不同深度,还有 class token 的去噪 loss 的权重 (velocity prediction loss),进行广泛的消融实验,证明 REG 有效性。
不同操作对比
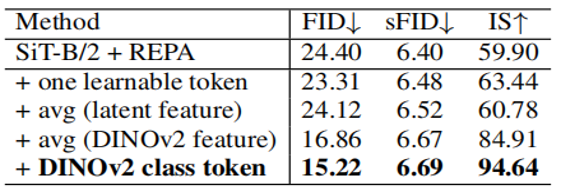
作者评估了不同内容作为 SiT 输入的影响,具体对比如下:
1. one learnable token,把 DINOv2 的 class token,换成一个可学习的 token
2. avg (latent feature),改进有限,缺乏判别性语义
3. avg (DINOv2 feature),显著提升
4. DINOv2 class token,效果最佳
表明 high-level 全局判别信息(avg (DINOv2 feature) 和 class token)能大幅提升生成质量,能有效规范生成的 latent,在保持计算效率的同时,同步提升语义质量和输出质量。
单独插入 class token 效果

研究 SiT 只插入 class token,不使用 REPA 效果。发现插入 class token,并进行联合加噪训练,依旧有非常不错的效果。
增强生成模型的判别语义学习

PS:CKNNA 是一个类似相似度的指标,REG 遵循 REPA 的设置,计算 REG 和 DINOv2 之间的 CKNNA,CKNNA 数值越大,代表 REG 和 DINOv2 越相似,REG 学习到了更多判别式语义。
Figure 3 系统分析了 REG 是否学习到了判别式语义,发现 REG 和判别式语义相关的指标 CKNNA,能在不同 block,layer,timesteps 都比 REPA 更高,具体情况如下:
1. 不同 Training steps (Figure 3 (a)): 随训练时间增加,FID 和 CKNNA 均提升,且 “更高 CKNNA → 更好生成”。REG 在各训练阶段均优于 REPA,说明引入 DINOv2 class token 增强了判别语义。
2. 不同的 layers,Figure 3 (b) 发现各模型在第 8 层语义分数达峰值后下降(此处进行 SiT 和 DINOv2 dense feature 的对齐,并计算对齐损失),但 REG 在所有层始终高于 REPA 和 SiT。这得益于其将 DINOv2 low-level latent 与 class token 融合,通过 attention 传递判别语义,使前中层专注理解 latent,后层专注生成细节。
3. 不同的 timesteps,Figure 3 (c) 呈现 REG 在所有时间步保持显著优势,验证了其在全噪声范围内稳定的语义引导能力。
总结
整体而言,REG 是一种极其简洁而高效的方案,首次提出了 high-level 与 low-level token 混合纠缠去噪的训练范式,在显著提升训练效率与收敛速度的同时完全不增加推理开销。其核心在于促进生成模型的 “理解 — 生成” 解耦:class token 指引 SiT 前层更专注于 noise latent 的理解,后层则聚焦于生成任务,从而实现 “先理解、后生成”,最终带来优异的生成效果。
文章来自于微信公众号 “机器之心”,作者 “机器之心”


